 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyse spectrale des textes: détection automatique des frontières de langue et de discours
Paper and Code
Oct 07, 2008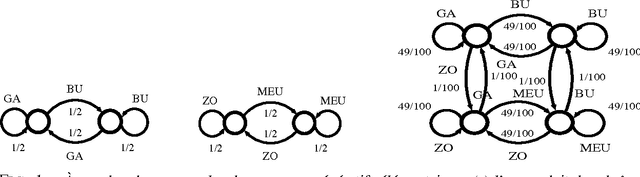

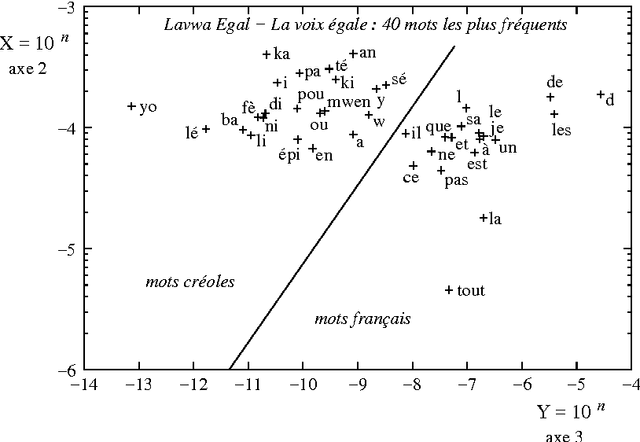
We propose a theoretical framework within which information on the vocabulary of a given corpus can be inferred on the basis of statistical information gathered on that corpus. Inferences can be made on the categories of the words in the vocabulary, and on their syntactical properties within particular languages. Based on the same statistical data, it is possible to build matrices of syntagmatic similarity (bigram transition matrices) or paradigmatic similarity (probability for any pair of words to share common contexts). When clustered with respect to their syntagmatic similarity, words tend to group into sublanguage vocabularies, and when clustered with respect to their paradigmatic similarity, into syntactic or semantic classes. Experiments have explored the first of these two possibilities. Their results are interpreted in the frame of a Markov chain modelling of the corpus' generative processe(s): we show that the results of a spectral analysis of the transition matrix can be interpreted as probability distributions of words within clusters. This method yields a soft clustering of the vocabulary into sublanguages which contribute to the generation of heterogeneous corpora. As an application, we show how multilingual texts can be visually segmented into linguistically homogeneous segments. Our method is specifically useful in the case of related languages which happened to be mixed in corpora.