 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnriched Annotations for Tumor Attribute Classification from Pathology Reports with Limited Labeled Data
Dec 15, 2020



Precision medicine has the potential to revolutionize healthcare, but much of the data for patients is locked away in unstructured free-text, limiting research and delivery of effective personalized treatments. Generating large annotated datasets for information extraction from clinical notes is often challenging and expensive due to the high level of expertise needed for high quality annotations. To enable natural language processing for small dataset sizes, we develop a novel enriched hierarchical annotation scheme and algorithm, Supervised Line Attention (SLA), and apply this algorithm to predicting categorical tumor attributes from kidney and colon cancer pathology reports from the University of California San Francisco (UCSF). Whereas previous work only annotated document level labels, we in addition ask the annotators to enrich the traditional label by asking them to also highlight the relevant line or potentially lines for the final label, which leads to a 20% increase of annotation time required per document. With the enriched annotations, we develop a simple and interpretable machine learning algorithm that first predicts the relevant lines in the document and then predicts the tumor attribute. Our results show across the small dataset sizes of 32, 64, 128, and 186 labeled documents per cancer, SLA only requires half the number of labeled documents as state-of-the-art methods to achieve similar or better micro-f1 and macro-f1 scores for the vast majority of comparisons that we made. Accounting for the increased annotation time, this leads to a 40% reduction in total annotation time over the state of the art.
Curating a COVID-19 data repository and forecasting county-level death counts in the United States
May 16, 2020
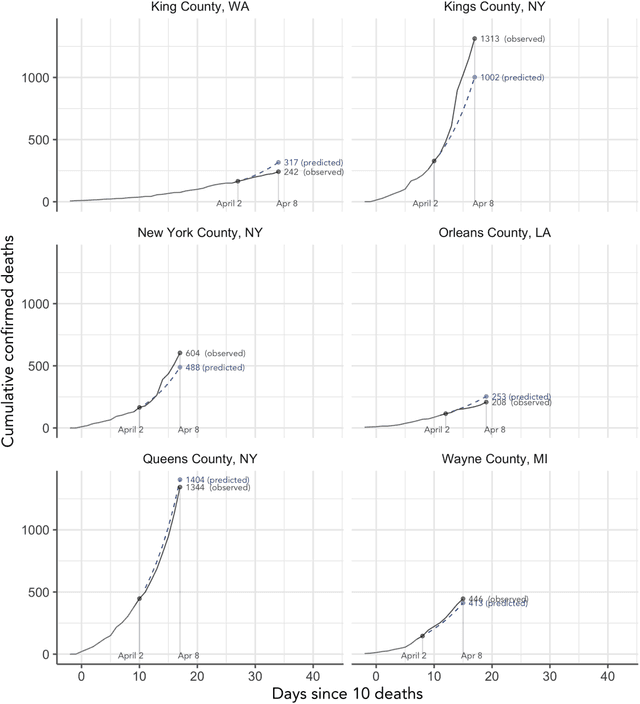
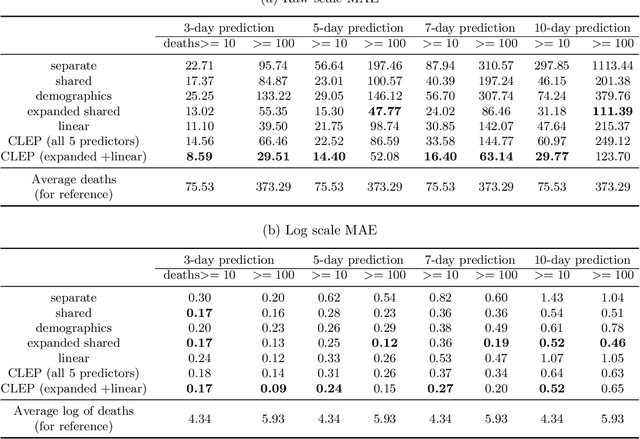
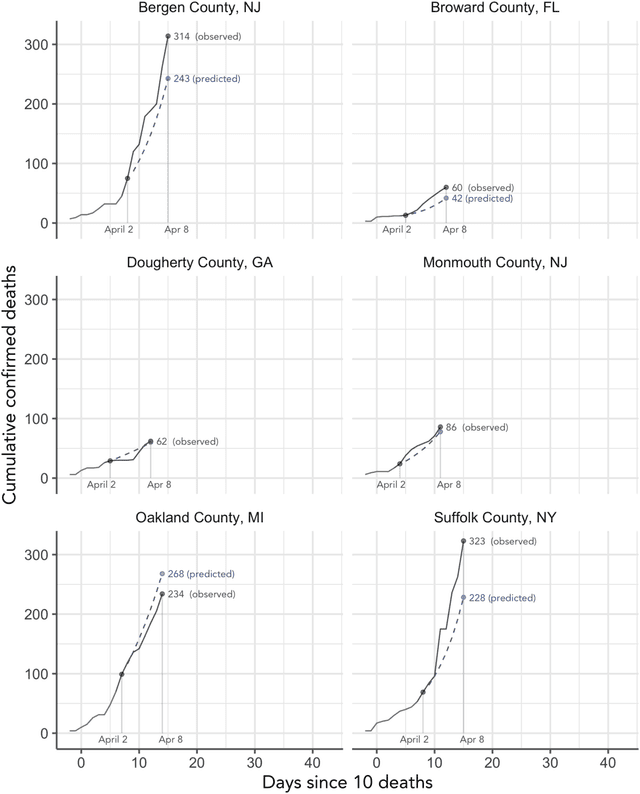
As the COVID-19 outbreak continues to evolve, accurate forecasting continues to play an extremely important role in informing policy decisions. In this paper, we collate a large data repository containing COVID-19 information from a range of different sources. We use this data to develop several predictors and prediction intervals for forecasting the short-term (e.g., over the next week) trajectory of COVID-19-related recorded deaths at the county-level in the United States. Specifically, using data from January 22, 2020, to May 10, 2020, we produce several different predictors and combine their forecasts using ensembling techniques, resulting in an ensemble we refer to as Combined Linear and Exponential Predictors (CLEP). Our individual predictors include county-specific exponential and linear predictors, an exponential predictor that pools data together across counties, and a demographics-based exponential predictor. In addition, we use the largest prediction errors in the past five days to assess the uncertainty of our death predictions, resulting in prediction intervals that we refer to as Maximum (absolute) Error Prediction Intervals (MEPI). We show that MEPI is an effective method in practice with a 94.5\% coverage rate when averaged across counties. Our forecasts are already being used by the non-profit organization, Response4Life, to determine the medical supply need for individual hospitals and have directly contributed to the distribution of medical supplies across the country. We hope that our forecasts and data repository can help guide necessary county-specific decision-making and help counties prepare for their continued fight against COVID-19. All collected data, modeling code, forecasts, and visualizations are updated daily and available at \url{https://github.com/Yu-Group/covid19-severity-prediction}.
Guiding Policies with Language via Meta-Learning
Nov 19, 2018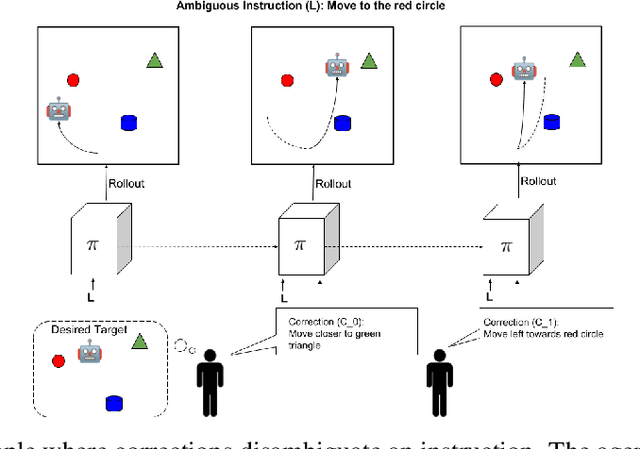

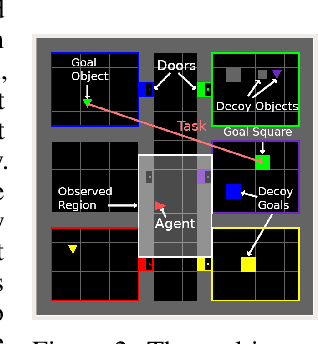
Behavioral skills or policies for autonomous agents are conventionally learned from reward functions, via reinforcement learning, or from demonstrations, via imitation learning. However, both modes of task specification have their disadvantages: reward functions require manual engineering, while demonstrations require a human expert to be able to actually perform the task in order to generate the demonstration. Instruction following from natural language instructions provides an appealing alternative: in the same way that we can specify goals to other humans simply by speaking or writing, we would like to be able to specify tasks for our machines. However, a single instruction may be insufficient to fully communicate our intent or, even if it is, may be insufficient for an autonomous agent to actually understand how to perform the desired task. In this work, we propose an interactive formulation of the task specification problem, where iterative language corrections are provided to an autonomous agent, guiding it in acquiring the desired skill. Our proposed language-guided policy learning algorithm can integrate an instruction and a sequence of corrections to acquire new skills very quickly. In our experiments, we show that this method can enable a policy to follow instructions and corrections for simulated navigation and manipulation tasks, substantially outperforming direct, non-interactive instruction following.