 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheano: A Python framework for fast computation of mathematical expressions
May 09, 2016
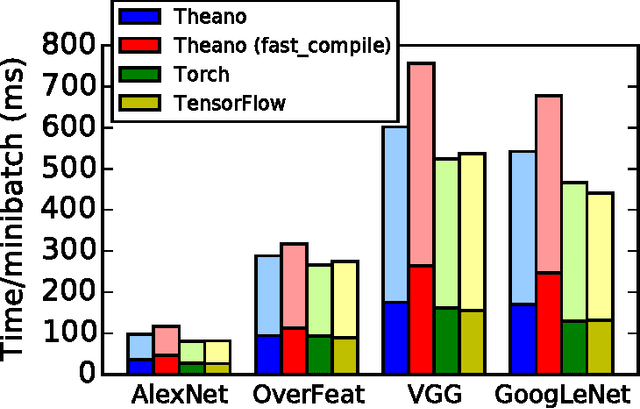
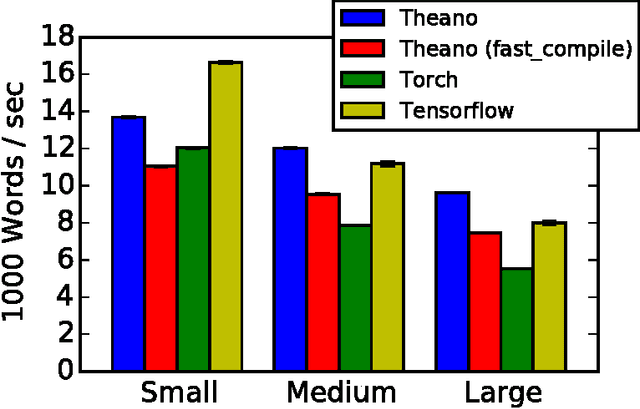
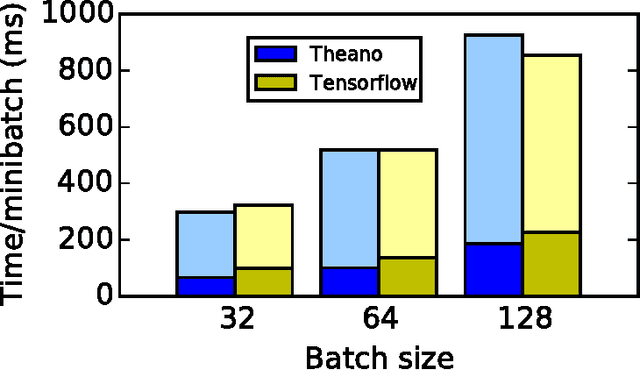
Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.
rnn : Recurrent Library for Torch
Dec 17, 2015The rnn package provides components for implementing a wide range of Recurrent Neural Networks. It is built withing the framework of the Torch distribution for use with the nn package. The components have evolved from 3 iterations, each adding to the flexibility and capability of the package. All component modules inherit either the AbstractRecurrent or AbstractSequencer classes. Strong unit testing, continued backwards compatibility and access to supporting material are the principles followed during its development. The package is compared against existing implementations of two published papers.
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Aug 15, 2013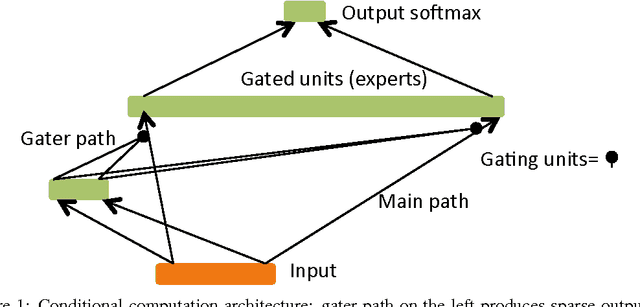
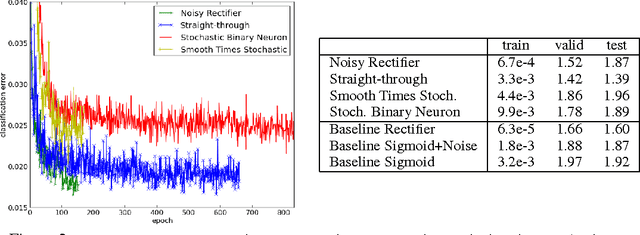
Stochastic neurons and hard non-linearities can be useful for a number of reasons in deep learning models, but in many cases they pose a challenging problem: how to estimate the gradient of a loss function with respect to the input of such stochastic or non-smooth neurons? I.e., can we "back-propagate" through these stochastic neurons? We examine this question, existing approaches, and compare four families of solutions, applicable in different settings. One of them is the minimum variance unbiased gradient estimator for stochatic binary neurons (a special case of the REINFORCE algorithm). A second approach, introduced here, decomposes the operation of a binary stochastic neuron into a stochastic binary part and a smooth differentiable part, which approximates the expected effect of the pure stochatic binary neuron to first order. A third approach involves the injection of additive or multiplicative noise in a computational graph that is otherwise differentiable. A fourth approach heuristically copies the gradient with respect to the stochastic output directly as an estimator of the gradient with respect to the sigmoid argument (we call this the straight-through estimator). To explore a context where these estimators are useful, we consider a small-scale version of {\em conditional computation}, where sparse stochastic units form a distributed representation of gaters that can turn off in combinatorially many ways large chunks of the computation performed in the rest of the neural network. In this case, it is important that the gating units produce an actual 0 most of the time. The resulting sparsity can be potentially be exploited to greatly reduce the computational cost of large deep networks for which conditional computation would be useful.