 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Paper and Code
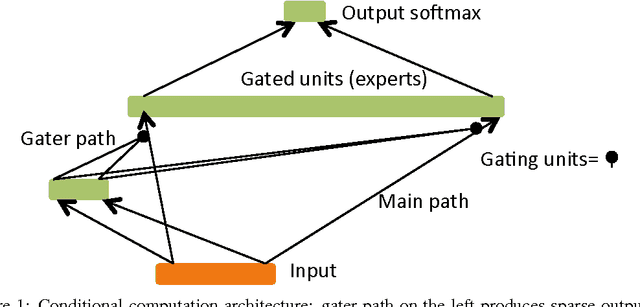
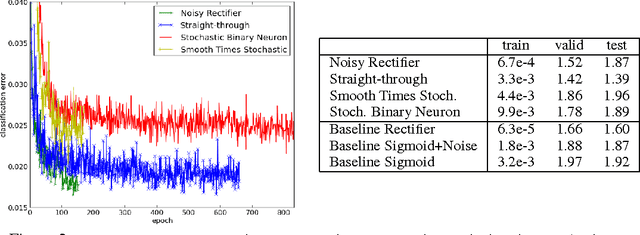
Stochastic neurons and hard non-linearities can be useful for a number of reasons in deep learning models, but in many cases they pose a challenging problem: how to estimate the gradient of a loss function with respect to the input of such stochastic or non-smooth neurons? I.e., can we "back-propagate" through these stochastic neurons? We examine this question, existing approaches, and compare four families of solutions, applicable in different settings. One of them is the minimum variance unbiased gradient estimator for stochatic binary neurons (a special case of the REINFORCE algorithm). A second approach, introduced here, decomposes the operation of a binary stochastic neuron into a stochastic binary part and a smooth differentiable part, which approximates the expected effect of the pure stochatic binary neuron to first order. A third approach involves the injection of additive or multiplicative noise in a computational graph that is otherwise differentiable. A fourth approach heuristically copies the gradient with respect to the stochastic output directly as an estimator of the gradient with respect to the sigmoid argument (we call this the straight-through estimator). To explore a context where these estimators are useful, we consider a small-scale version of {\em conditional computation}, where sparse stochastic units form a distributed representation of gaters that can turn off in combinatorially many ways large chunks of the computation performed in the rest of the neural network. In this case, it is important that the gating units produce an actual 0 most of the time. The resulting sparsity can be potentially be exploited to greatly reduce the computational cost of large deep networks for which conditional computation would be useful.