 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpace Group Equivariant Crystal Diffusion
May 16, 2025Accelerating inverse design of crystalline materials with generative models has significant implications for a range of technologies. Unlike other atomic systems, 3D crystals are invariant to discrete groups of isometries called the space groups. Crucially, these space group symmetries are known to heavily influence materials properties. We propose SGEquiDiff, a crystal generative model which naturally handles space group constraints with space group invariant likelihoods. SGEquiDiff consists of an SE(3)-invariant, telescoping discrete sampler of crystal lattices; permutation-invariant, transformer-based autoregressive sampling of Wyckoff positions, elements, and numbers of symmetrically unique atoms; and space group equivariant diffusion of atomic coordinates. We show that space group equivariant vector fields automatically live in the tangent spaces of the Wyckoff positions. SGEquiDiff achieves state-of-the-art performance on standard benchmark datasets as assessed by quantitative proxy metrics and quantum mechanical calculations.
Diagonal Symmetrization of Neural Network Solvers for the Many-Electron Schrödinger Equation
Feb 07, 2025Incorporating group symmetries into neural networks has been a cornerstone of success in many AI-for-science applications. Diagonal groups of isometries, which describe the invariance under a simultaneous movement of multiple objects, arise naturally in many-body quantum problems. Despite their importance, diagonal groups have received relatively little attention, as they lack a natural choice of invariant maps except in special cases. We study different ways of incorporating diagonal invariance in neural network ans\"atze trained via variational Monte Carlo methods, and consider specifically data augmentation, group averaging and canonicalization. We show that, contrary to standard ML setups, in-training symmetrization destabilizes training and can lead to worse performance. Our theoretical and numerical results indicate that this unexpected behavior may arise from a unique computational-statistical tradeoff not found in standard ML analyses of symmetrization. Meanwhile, we demonstrate that post hoc averaging is less sensitive to such tradeoffs and emerges as a simple, flexible and effective method for improving neural network solvers.
Where does the Stimulus go? Deep Generative Model for Commercial Banking Deposits
Jan 22, 2021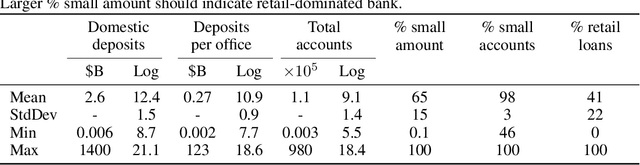
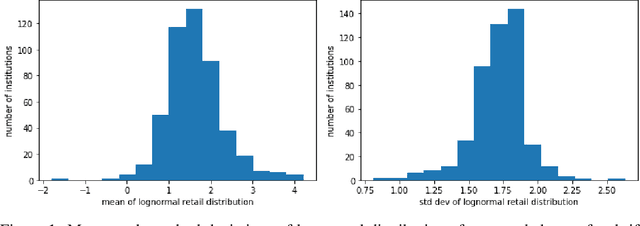
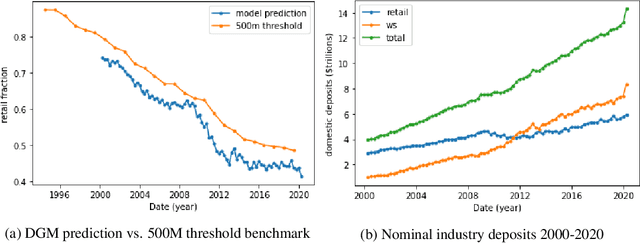

This paper examines deposits of individuals ("retail") and large companies ("wholesale") in the U.S. banking industry, and how these deposit types are impacted by macroeconomic factors, such as quantitative easing (QE). Actual data for deposits by holder are unavailable. We use a dataset on banks' financial information and probabilistic generative model to predict industry retail-wholesale deposit split from 2000 to 2020. Our model assumes account balances arise from separate retail and wholesale lognormal distributions and fit parameters of distributions by minimizing error between actual bank metrics and simulated metrics using the model's generative process. We use time-series regression to forward predict retail-wholesale deposits as function of loans, retail loans, and reserve balances at Fed banks. We find increase in reserves (representing QE) increases wholesale but not retail deposits, and increase in loans increase both wholesale and retail deposits evenly. The result shows that QE following the 2008 financial crisis benefited large companies more than average individuals, a relevant finding for economic decision making. In addition, this work benefits bank management strategy by providing forecasting capability for retail-wholesale deposits.
Graphical Models for Financial Time Series and Portfolio Selection
Jan 22, 2021
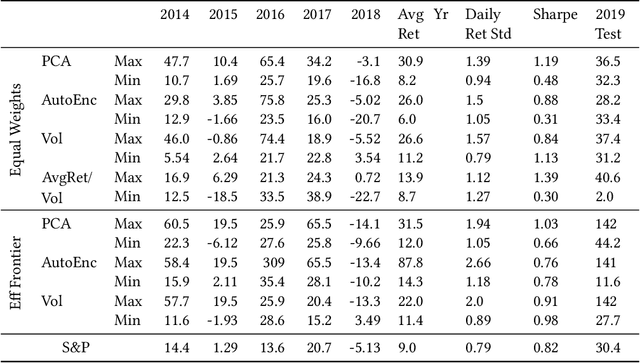
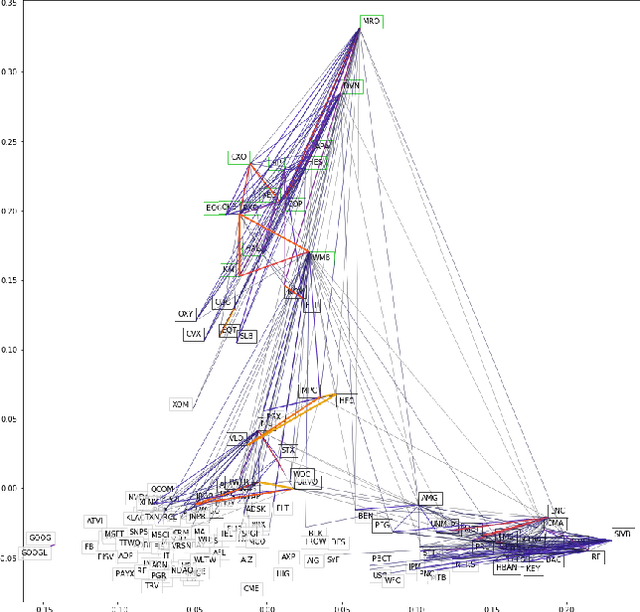

We examine a variety of graphical models to construct optimal portfolios. Graphical models such as PCA-KMeans, autoencoders, dynamic clustering, and structural learning can capture the time varying patterns in the covariance matrix and allow the creation of an optimal and robust portfolio. We compared the resulting portfolios from the different models with baseline methods. In many cases our graphical strategies generated steadily increasing returns with low risk and outgrew the S&P 500 index. This work suggests that graphical models can effectively learn the temporal dependencies in time series data and are proved useful in asset management.
Triplet-based Deep Similarity Learning for Person Re-Identification
Feb 09, 2018
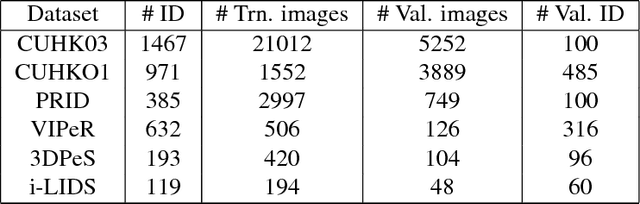
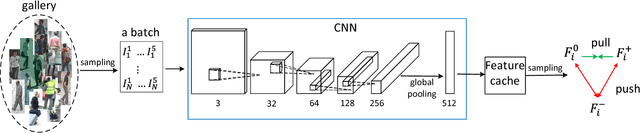
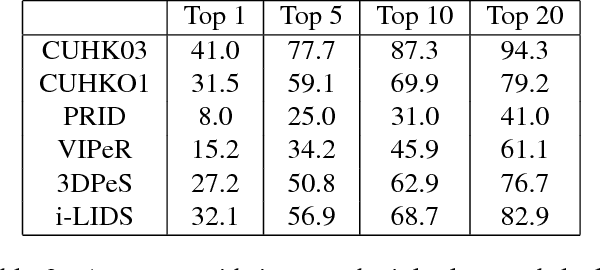
In recent years, person re-identification (re-id) catches great attention in both computer vision community and industry. In this paper, we propose a new framework for person re-identification with a triplet-based deep similarity learning using convolutional neural networks (CNNs). The network is trained with triplet input: two of them have the same class labels and the other one is different. It aims to learn the deep feature representation, with which the distance within the same class is decreased, while the distance between the different classes is increased as much as possible. Moreover, we trained the model jointly on six different datasets, which differs from common practice - one model is just trained on one dataset and tested also on the same one. However, the enormous number of possible triplet data among the large number of training samples makes the training impossible. To address this challenge, a double-sampling scheme is proposed to generate triplets of images as effective as possible. The proposed framework is evaluated on several benchmark datasets. The experimental results show that, our method is effective for the task of person re-identification and it is comparable or even outperforms the state-of-the-art methods.