 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
Graphical Models for Financial Time Series and Portfolio Selection
Jan 22, 2021
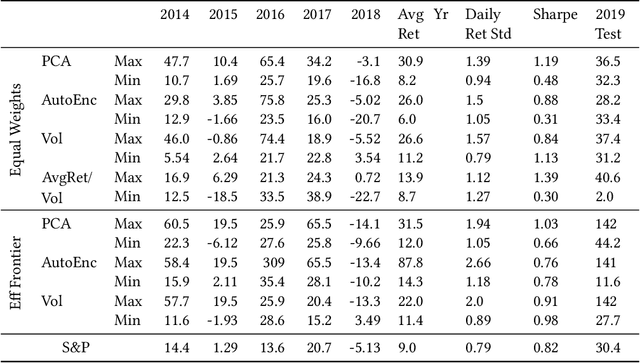
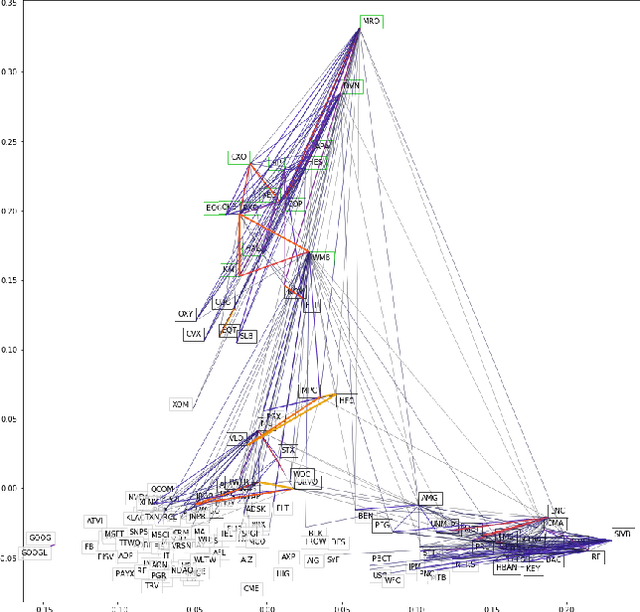

We examine a variety of graphical models to construct optimal portfolios. Graphical models such as PCA-KMeans, autoencoders, dynamic clustering, and structural learning can capture the time varying patterns in the covariance matrix and allow the creation of an optimal and robust portfolio. We compared the resulting portfolios from the different models with baseline methods. In many cases our graphical strategies generated steadily increasing returns with low risk and outgrew the S&P 500 index. This work suggests that graphical models can effectively learn the temporal dependencies in time series data and are proved useful in asset management.