 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual-Inertial SLAM as Simple as A, B, VINS
Jun 10, 2024



We present AB-VINS, a different kind of visual-inertial SLAM system. Unlike most VINS systems which only use hand-crafted techniques, AB-VINS makes use of three different deep networks. Instead of estimating sparse feature positions, AB-VINS only estimates the scale and bias parameters (a and b) of monocular depth maps, as well as other terms to correct the depth using multi-view information which results in a compressed feature state. Despite being an optimization-based system, the main VIO thread of AB-VINS surpasses the efficiency of a state-of-the-art filter-based method while also providing dense depth. While state-of-the-art loop-closing SLAM systems have to relinearize a number of variables linear the number of keyframes, AB-VINS can perform loop closures while only affecting a constant number of variables. This is due to a novel data structure called the memory tree, in which the keyframe poses are defined relative to each other rather than all in one global frame, allowing for all but a few states to be fixed. AB-VINS is not as accurate as state-of-the-art VINS systems, but it is shown through careful experimentation to be more robust.
Incremental Dense Reconstruction from Monocular Video with Guided Sparse Feature Volume Fusion
May 24, 2023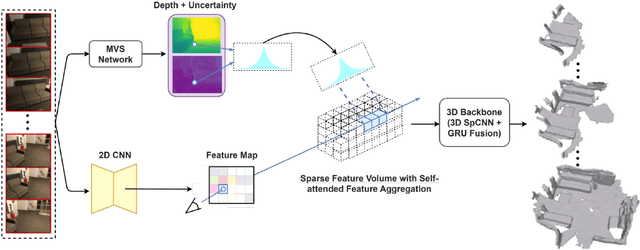
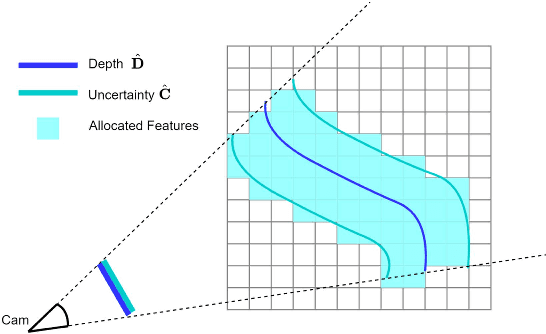
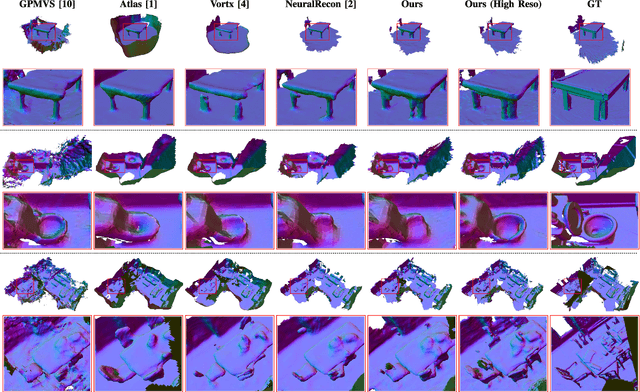

Incrementally recovering 3D dense structures from monocular videos is of paramount importance since it enables various robotics and AR applications. Feature volumes have recently been shown to enable efficient and accurate incremental dense reconstruction without the need to first estimate depth, but they are not able to achieve as high of a resolution as depth-based methods due to the large memory consumption of high-resolution feature volumes. This letter proposes a real-time feature volume-based dense reconstruction method that predicts TSDF (Truncated Signed Distance Function) values from a novel sparsified deep feature volume, which is able to achieve higher resolutions than previous feature volume-based methods, and is favorable in large-scale outdoor scenarios where the majority of voxels are empty. An uncertainty-aware multi-view stereo (MVS) network is leveraged to infer initial voxel locations of the physical surface in a sparse feature volume. Then for refining the recovered 3D geometry, deep features are attentively aggregated from multiview images at potential surface locations, and temporally fused. Besides achieving higher resolutions than before, our method is shown to produce more complete reconstructions with finer detail in many cases. Extensive evaluations on both public and self-collected datasets demonstrate a very competitive real-time reconstruction result for our method compared to state-of-the-art reconstruction methods in both indoor and outdoor settings.
Symmetry and Uncertainty-Aware Object SLAM for 6DoF Object Pose Estimation
May 04, 2022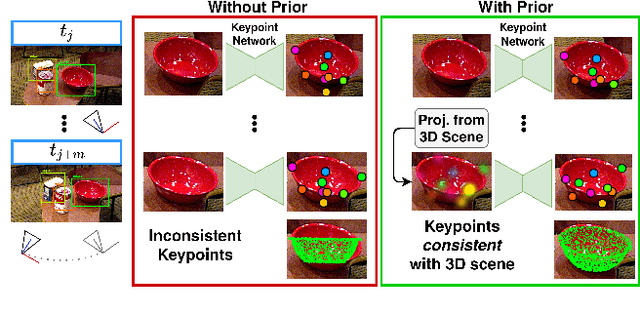
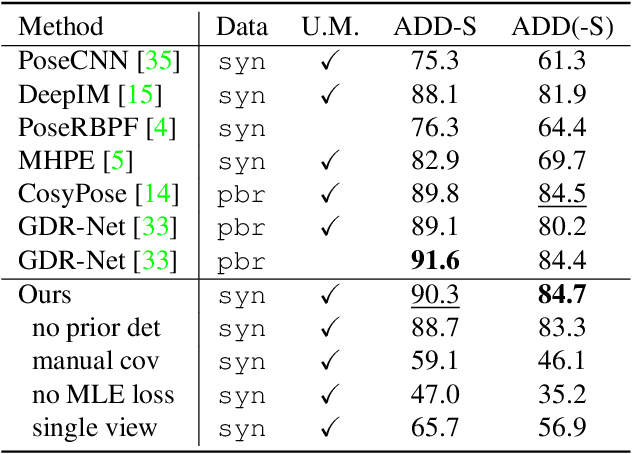
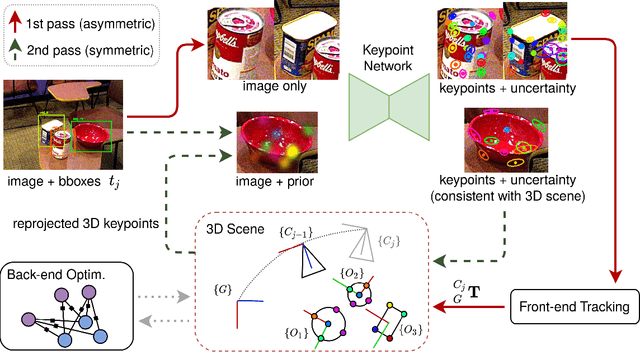
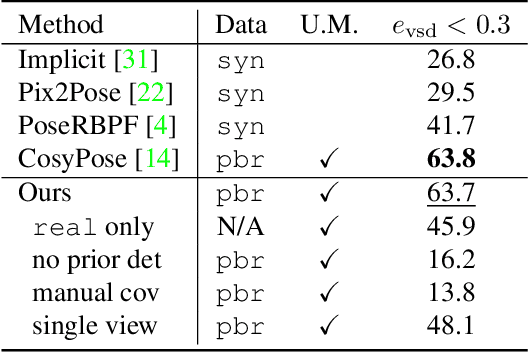
We propose a keypoint-based object-level SLAM framework that can provide globally consistent 6DoF pose estimates for symmetric and asymmetric objects alike. To the best of our knowledge, our system is among the first to utilize the camera pose information from SLAM to provide prior knowledge for tracking keypoints on symmetric objects -- ensuring that new measurements are consistent with the current 3D scene. Moreover, our semantic keypoint network is trained to predict the Gaussian covariance for the keypoints that captures the true error of the prediction, and thus is not only useful as a weight for the residuals in the system's optimization problems, but also as a means to detect harmful statistical outliers without choosing a manual threshold. Experiments show that our method provides competitive performance to the state of the art in 6DoF object pose estimation, and at a real-time speed. Our code, pre-trained models, and keypoint labels are available https://github.com/rpng/suo_slam.
CodeVIO: Visual-Inertial Odometry with Learned Optimizable Dense Depth
Dec 18, 2020
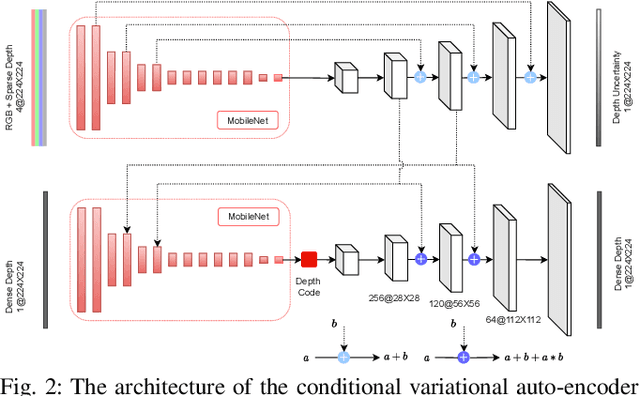
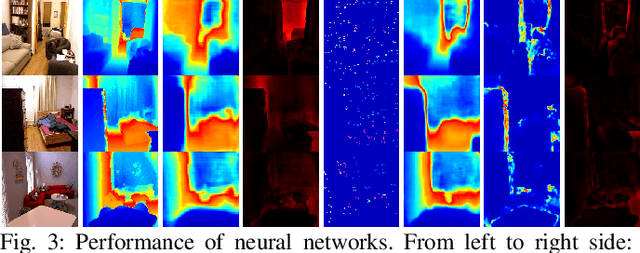
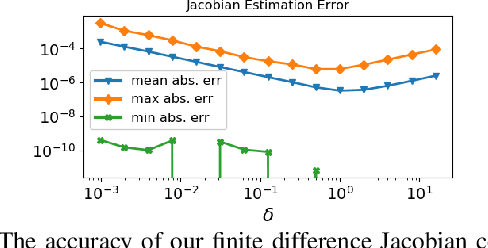
In this work, we present a lightweight, tightly-coupled deep depth network and visual-inertial odometry (VIO) system, which can provide accurate state estimates and dense depth maps of the immediate surroundings. Leveraging the proposed lightweight Conditional Variational Autoencoder (CVAE) for depth inference and encoding, we provide the network with previously marginalized sparse features from VIO to increase the accuracy of initial depth prediction and generalization capability. The compact encoded depth maps are then updated jointly with navigation states in a sliding window estimator in order to provide the dense local scene geometry. We additionally propose a novel method to obtain the CVAE's Jacobian which is shown to be more than an order of magnitude faster than previous works, and we additionally leverage First-Estimate Jacobian (FEJ) to avoid recalculation. As opposed to previous works relying on completely dense residuals, we propose to only provide sparse measurements to update the depth code and show through careful experimentation that our choice of sparse measurements and FEJs can still significantly improve the estimated depth maps. Our full system also exhibits state-of-the-art pose estimation accuracy, and we show that it can run in real-time with single-thread execution while utilizing GPU acceleration only for the network and code Jacobian.
CALC2.0: Combining Appearance, Semantic and Geometric Information for Robust and Efficient Visual Loop Closure
Oct 30, 2019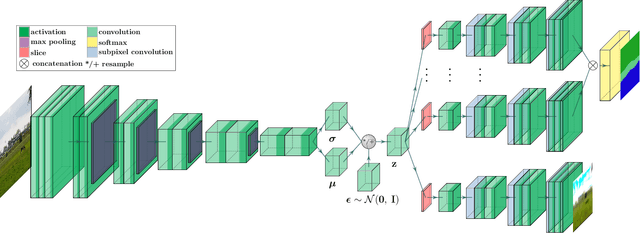
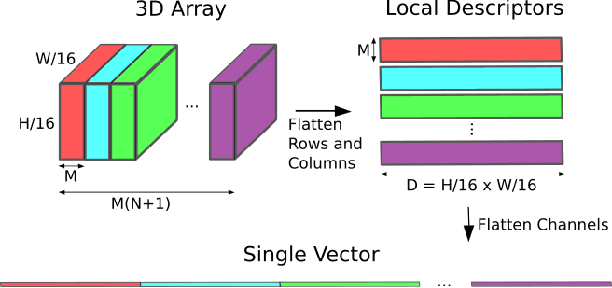

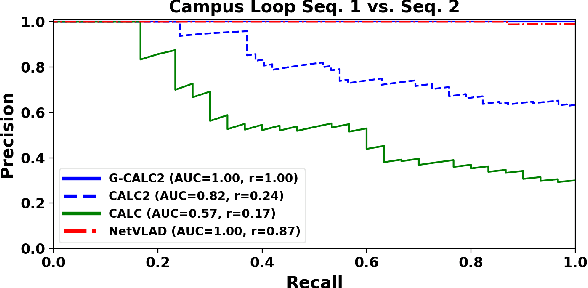
Traditional attempts for loop closure detection typically use hand-crafted features, relying on geometric and visual information only, whereas more modern approaches tend to use semantic, appearance or geometric features extracted from deep convolutional neural networks (CNNs). While these approaches are successful in many applications, they do not utilize all of the information that a monocular image provides, and many of them, particularly the deep-learning based methods, require user-chosen thresholding to actually close loops -- which may impact generality in practical applications. In this work, we address these issues by extracting all three modes of information from a custom deep CNN trained specifically for the task of place recognition. Our network is built upon a combination of a semantic segmentator, Variational Autoencoder (VAE) and triplet embedding network. The network is trained to construct a global feature space to describe both the visual appearance and semantic layout of an image. Then local keypoints are extracted from maximally-activated regions of low-level convolutional feature maps, and keypoint descriptors are extracted from these feature maps in a novel way that incorporates ideas from successful hand-crafted features. These keypoints are matched globally for loop closure candidates, and then used as a final geometric check to refute false positives. As a result, the proposed loop closure detection system requires no touchy thresholding, and is highly robust to false positives -- achieving better precision-recall curves than the state-of-the-art NetVLAD, and with real-time speeds.