 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCALC2.0: Combining Appearance, Semantic and Geometric Information for Robust and Efficient Visual Loop Closure
Paper and Code
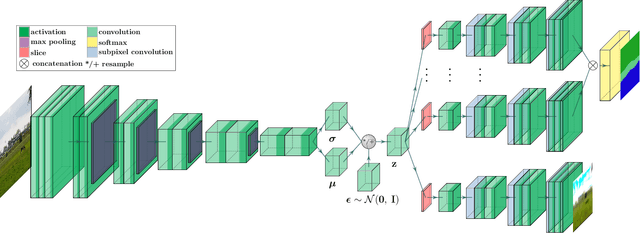
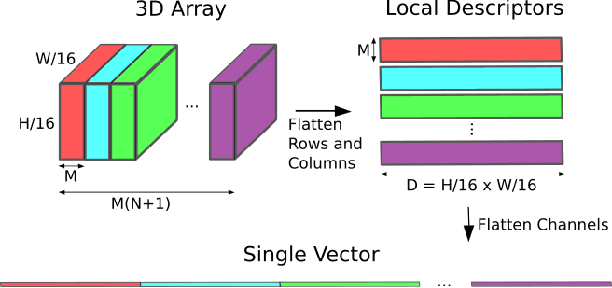

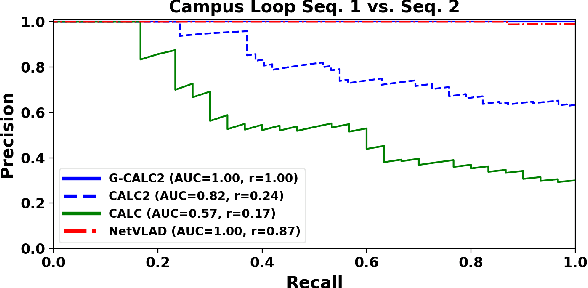
Traditional attempts for loop closure detection typically use hand-crafted features, relying on geometric and visual information only, whereas more modern approaches tend to use semantic, appearance or geometric features extracted from deep convolutional neural networks (CNNs). While these approaches are successful in many applications, they do not utilize all of the information that a monocular image provides, and many of them, particularly the deep-learning based methods, require user-chosen thresholding to actually close loops -- which may impact generality in practical applications. In this work, we address these issues by extracting all three modes of information from a custom deep CNN trained specifically for the task of place recognition. Our network is built upon a combination of a semantic segmentator, Variational Autoencoder (VAE) and triplet embedding network. The network is trained to construct a global feature space to describe both the visual appearance and semantic layout of an image. Then local keypoints are extracted from maximally-activated regions of low-level convolutional feature maps, and keypoint descriptors are extracted from these feature maps in a novel way that incorporates ideas from successful hand-crafted features. These keypoints are matched globally for loop closure candidates, and then used as a final geometric check to refute false positives. As a result, the proposed loop closure detection system requires no touchy thresholding, and is highly robust to false positives -- achieving better precision-recall curves than the state-of-the-art NetVLAD, and with real-time speeds.