 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Chain Of Thoughts Prompts for Predicting Entities, Relations, and even Literals on Knowledge Graphs
Apr 14, 2026Knowledge graph embedding (KGE) models perform well on link prediction but struggle with unseen entities, relations, and especially literals, limiting their use in dynamic, heterogeneous graphs. In contrast, pretrained large language models (LLMs) generalize effectively through prompting. We reformulate link prediction as a prompt learning problem and introduce RALP, which learns string-based chain-of-thought (CoT) prompts as scoring functions for triples. Using Bayesian Optimization through MIPRO algorithm, RALP identifies effective prompts from fewer than 30 training examples without gradient access. At inference, RALP predicts missing entities, relations or whole triples and assigns confidence scores based on the learned prompt. We evaluate on transductive, numerical, and OWL instance retrieval benchmarks. RALP improves state-of-the-art KGE models by over 5% MRR across datasets and enhances generalization via high-quality inferred triples. On OWL reasoning tasks with complex class expressions (e.g., $\exists hasChild.Female$, $\geq 5 \; hasChild.Female$), it achieves over 88% Jaccard similarity. These results highlight prompt-based LLM reasoning as a flexible alternative to embedding-based methods. We release our implementation, training, and evaluation pipeline as open source: https://github.com/dice-group/RALP .
Neural Reasoning for Robust Instance Retrieval in $\mathcal{SHOIQ}$
Oct 23, 2025Concept learning exploits background knowledge in the form of description logic axioms to learn explainable classification models from knowledge bases. Despite recent breakthroughs in neuro-symbolic concept learning, most approaches still cannot be deployed on real-world knowledge bases. This is due to their use of description logic reasoners, which are not robust against inconsistencies nor erroneous data. We address this challenge by presenting a novel neural reasoner dubbed EBR. Our reasoner relies on embeddings to approximate the results of a symbolic reasoner. We show that EBR solely requires retrieving instances for atomic concepts and existential restrictions to retrieve or approximate the set of instances of any concept in the description logic $\mathcal{SHOIQ}$. In our experiments, we compare EBR with state-of-the-art reasoners. Our results suggest that EBR is robust against missing and erroneous data in contrast to existing reasoners.
Explainable Benchmarking through the Lense of Concept Learning
Oct 23, 2025Evaluating competing systems in a comparable way, i.e., benchmarking them, is an undeniable pillar of the scientific method. However, system performance is often summarized via a small number of metrics. The analysis of the evaluation details and the derivation of insights for further development or use remains a tedious manual task with often biased results. Thus, this paper argues for a new type of benchmarking, which is dubbed explainable benchmarking. The aim of explainable benchmarking approaches is to automatically generate explanations for the performance of systems in a benchmark. We provide a first instantiation of this paradigm for knowledge-graph-based question answering systems. We compute explanations by using a novel concept learning approach developed for large knowledge graphs called PruneCEL. Our evaluation shows that PruneCEL outperforms state-of-the-art concept learners on the task of explainable benchmarking by up to 0.55 points F1 measure. A task-driven user study with 41 participants shows that in 80\% of the cases, the majority of participants can accurately predict the behavior of a system based on our explanations. Our code and data are available at https://github.com/dice-group/PruneCEL/tree/K-cap2025
Diving Deep: Forecasting Sea Surface Temperatures and Anomalies
Jan 10, 2025This overview paper details the findings from the Diving Deep: Forecasting Sea Surface Temperatures and Anomalies Challenge at the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD) 2024. The challenge focused on the data-driven predictability of global sea surface temperatures (SSTs), a key factor in climate forecasting, ecosystem management, fisheries management, and climate change monitoring. The challenge involved forecasting SST anomalies (SSTAs) three months in advance using historical data and included a special task of predicting SSTAs nine months ahead for the Baltic Sea. Participants utilized various machine learning approaches to tackle the task, leveraging data from ERA5. This paper discusses the methodologies employed, the results obtained, and the lessons learned, offering insights into the future of climate-related predictive modeling.
Resilience in Knowledge Graph Embeddings
Oct 28, 2024In recent years, knowledge graphs have gained interest and witnessed widespread applications in various domains, such as information retrieval, question-answering, recommendation systems, amongst others. Large-scale knowledge graphs to this end have demonstrated their utility in effectively representing structured knowledge. To further facilitate the application of machine learning techniques, knowledge graph embedding (KGE) models have been developed. Such models can transform entities and relationships within knowledge graphs into vectors. However, these embedding models often face challenges related to noise, missing information, distribution shift, adversarial attacks, etc. This can lead to sub-optimal embeddings and incorrect inferences, thereby negatively impacting downstream applications. While the existing literature has focused so far on adversarial attacks on KGE models, the challenges related to the other critical aspects remain unexplored. In this paper, we, first of all, give a unified definition of resilience, encompassing several factors such as generalisation, performance consistency, distribution adaption, and robustness. After formalizing these concepts for machine learning in general, we define them in the context of knowledge graphs. To find the gap in the existing works on resilience in the context of knowledge graphs, we perform a systematic survey, taking into account all these aspects mentioned previously. Our survey results show that most of the existing works focus on a specific aspect of resilience, namely robustness. After categorizing such works based on their respective aspects of resilience, we discuss the challenges and future research directions.
Inference over Unseen Entities, Relations and Literals on Knowledge Graphs
Oct 09, 2024
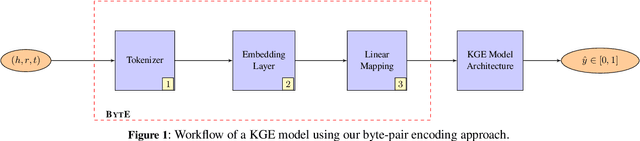

In recent years, knowledge graph embedding models have been successfully applied in the transductive setting to tackle various challenging tasks including link prediction, and query answering. Yet, the transductive setting does not allow for reasoning over unseen entities, relations, let alone numerical or non-numerical literals. Although increasing efforts are put into exploring inductive scenarios, inference over unseen entities, relations, and literals has yet to come. This limitation prohibits the existing methods from handling real-world dynamic knowledge graphs involving heterogeneous information about the world. Here, we propose a remedy to this limitation. We propose the attentive byte-pair encoding layer (BytE) to construct a triple embedding from a sequence of byte-pair encoded subword units of entities and relations. Compared to the conventional setting, BytE leads to massive feature reuse via weight tying, since it forces a knowledge graph embedding model to learn embeddings for subword units instead of entities and relations directly. Consequently, the size of the embedding matrices are not anymore bound to the unique number of entities and relations of a knowledge graph. Experimental results show that BytE improves the link prediction performance of 4 knowledge graph embedding models on datasets where the syntactic representations of triples are semantically meaningful. However, benefits of training a knowledge graph embedding model with BytE dissipate on knowledge graphs where entities and relations are represented with plain numbers or URIs. We provide an open source implementation of BytE to foster reproducible research.
Improving rule mining via embedding-based link prediction
Jun 14, 2024


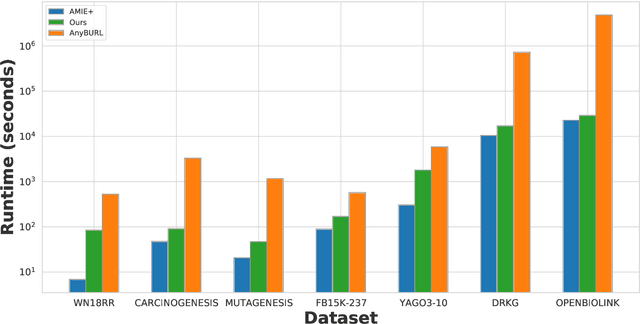
Rule mining on knowledge graphs allows for explainable link prediction. Contrarily, embedding-based methods for link prediction are well known for their generalization capabilities, but their predictions are not interpretable. Several approaches combining the two families have been proposed in recent years. The majority of the resulting hybrid approaches are usually trained within a unified learning framework, which often leads to convergence issues due to the complexity of the learning task. In this work, we propose a new way to combine the two families of approaches. Specifically, we enrich a given knowledge graph by means of its pre-trained entity and relation embeddings before applying rule mining systems on the enriched knowledge graph. To validate our approach, we conduct extensive experiments on seven benchmark datasets. An analysis of the results generated by our approach suggests that we discover new valuable rules on the enriched graphs. We provide an open source implementation of our approach as well as pretrained models and datasets at https://github.com/Jean-KOUAGOU/EnhancedRuleLearning
Universal Knowledge Graph Embeddings
Oct 23, 2023A variety of knowledge graph embedding approaches have been developed. Most of them obtain embeddings by learning the structure of the knowledge graph within a link prediction setting. As a result, the embeddings reflect only the semantics of a single knowledge graph, and embeddings for different knowledge graphs are not aligned, e.g., they cannot be used to find similar entities across knowledge graphs via nearest neighbor search. However, knowledge graph embedding applications such as entity disambiguation require a more global representation, i.e., a representation that is valid across multiple sources. We propose to learn universal knowledge graph embeddings from large-scale interlinked knowledge sources. To this end, we fuse large knowledge graphs based on the owl:sameAs relation such that every entity is represented by a unique identity. We instantiate our idea by computing universal embeddings based on DBpedia and Wikidata yielding embeddings for about 180 million entities, 15 thousand relations, and 1.2 billion triples. Moreover, we develop a convenient API to provide embeddings as a service. Experiments on link prediction show that universal knowledge graph embeddings encode better semantics compared to embeddings computed on a single knowledge graph. For reproducibility purposes, we provide our source code and datasets open access at https://github.com/dice-group/Universal_Embeddings
Neural Class Expression Synthesis
Nov 18, 2021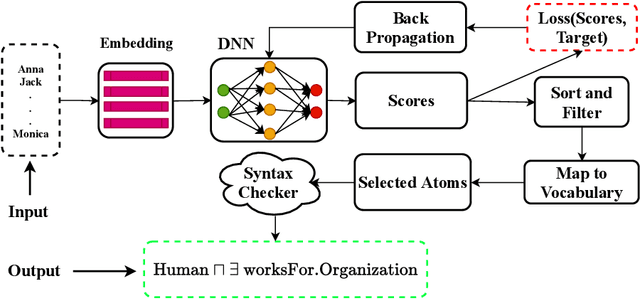

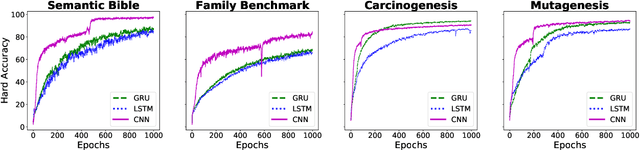
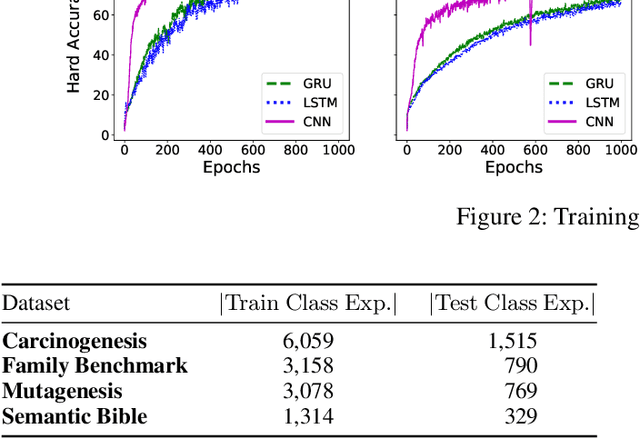
Class expression learning is a branch of explainable supervised machine learning of increasing importance. Most existing approaches for class expression learning in description logics are search algorithms or hard-rule-based. In particular, approaches based on refinement operators suffer from scalability issues as they rely on heuristic functions to explore a large search space for each learning problem. We propose a new family of approaches, which we dub synthesis approaches. Instances of this family compute class expressions directly from the examples provided. Consequently, they are not subject to the runtime limitations of search-based approaches nor the lack of flexibility of hard-rule-based approaches. We study three instances of this novel family of approaches that use lightweight neural network architectures to synthesize class expressions from sets of positive examples. The results of their evaluation on four benchmark datasets suggest that they can effectively synthesize high-quality class expressions with respect to the input examples in under a second on average. Moreover, a comparison with the state-of-the-art approaches CELOE and ELTL suggests that we achieve significantly better F-measures on large ontologies. For reproducibility purposes, we provide our implementation as well as pre-trained models in the public GitHub repository at https://github.com/ConceptLengthLearner/NCES
Prediction of concept lengths for fast concept learning in description logics
Jul 10, 2021



Concept learning approaches based on refinement operators explore partially ordered solution spaces to compute concepts, which are used as binary classification models for individuals. However, the refinement trees spanned by these approaches can easily grow to millions of nodes for complex learning problems. This leads to refinement-based approaches often failing to detect optimal concepts efficiently. In this paper, we propose a supervised machine learning approach for learning concept lengths, which allows predicting the length of the target concept and therefore facilitates the reduction of the search space during concept learning. To achieve this goal, we compare four neural architectures and evaluate them on four benchmark knowledge graphs--Carcinogenesis, Mutagenesis, Semantic Bible, Family Benchmark. Our evaluation results suggest that recurrent neural network architectures perform best at concept length prediction with an F-measure of up to 92%. We show that integrating our concept length predictor into the CELOE (Class Expression Learner for Ontology Engineering) algorithm improves CELOE's runtime by a factor of up to 13.4 without any significant changes to the quality of the results it generates. For reproducibility, we provide our implementation in the public GitHub repository at https://github.com/ConceptLengthLearner/ReproducibilityRepo