 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData and Image Prior Integration for Image Reconstruction Using Consensus Equilibrium
Aug 31, 2020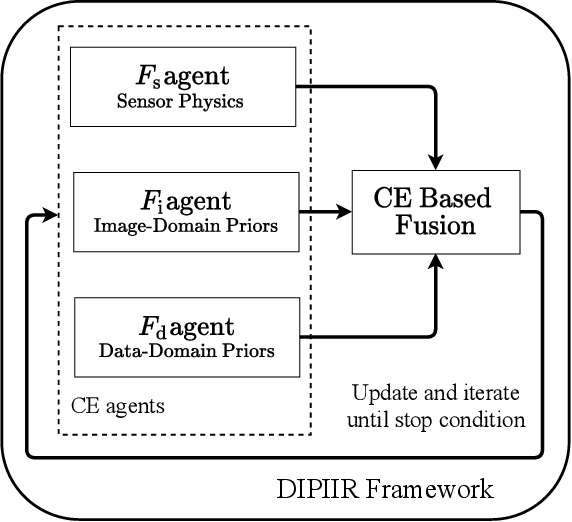
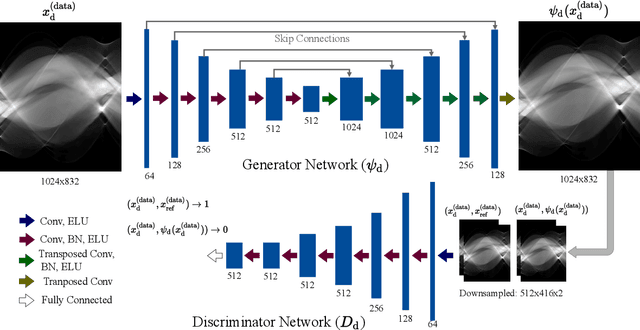
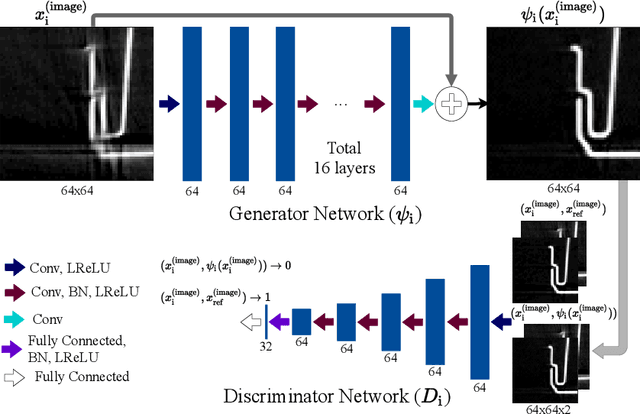
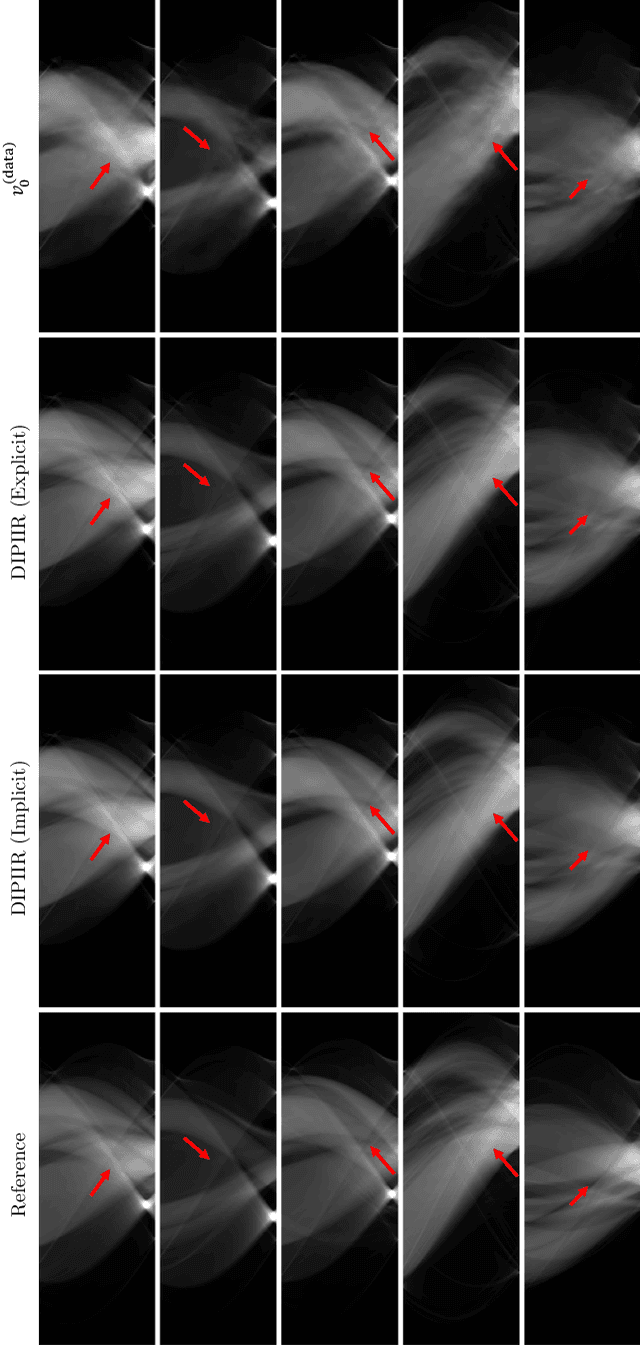
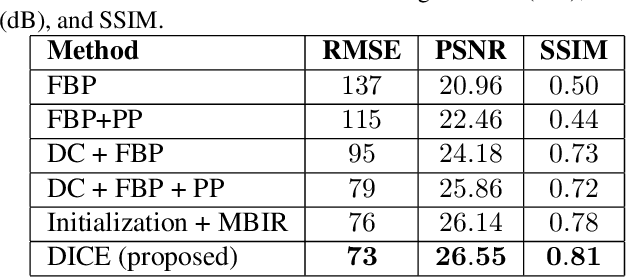
Image domain prior models have been shown to improve the quality of reconstructed images, especially when data are limited. Pre-processing of raw data, through the implicit or explicit inclusion of data domain priors have separately also shown utility in improving reconstructions. In this work, a principled approach is presented allowing the unified integration of both data and image domain priors for improved image reconstruction. The consensus equilibrium framework is extended to integrate physical sensor models, data models, and image models. In order to achieve this integration, the conventional image variables used in consensus equilibrium are augmented with variables representing data domain quantities. The overall result produces combined estimates of both the data and the reconstructed image that is consistent with the physical models and prior models being utilized. The prior models used in both domains in this work are created using deep neural networks. The superior quality allowed by incorporating both data and image domain prior models is demonstrated for two applications: limited-angle CT and accelerated MRI. The prior data model in both these applications is focused on recovering missing data. Experimental results are presented for a 90 degree limited-angle tomography problem from a real checked-bagged CT dataset and a 4x accelerated MRI problem on a simulated dataset. The new framework is very flexible and can be easily applied to other computational imaging problems with imperfect data.
A Precisely Xtreme-Multi Channel Hybrid Approach For Roman Urdu Sentiment Analysis
Mar 11, 2020

In order to accelerate the performance of various Natural Language Processing tasks for Roman Urdu, this paper for the very first time provides 3 neural word embeddings prepared using most widely used approaches namely Word2vec, FastText, and Glove. The integrity of generated neural word embeddings is evaluated using intrinsic and extrinsic evaluation approaches. Considering the lack of publicly available benchmark datasets, it provides a first-ever Roman Urdu dataset which consists of 3241 sentiments annotated against positive, negative and neutral classes. To provide benchmark baseline performance over the presented dataset, we adapt diverse machine learning (Support Vector Machine Logistic Regression, Naive Bayes), deep learning (convolutional neural network, recurrent neural network), and hybrid approaches. Effectiveness of generated neural word embeddings is evaluated by comparing the performance of machine and deep learning based methodologies using 7, and 5 distinct feature representation approaches respectively. Finally, it proposes a novel precisely extreme multi-channel hybrid methodology which outperforms state-of-the-art adapted machine and deep learning approaches by the figure of 9%, and 4% in terms of F1-score. Roman Urdu Sentiment Analysis, Pretrain word embeddings for Roman Urdu, Word2Vec, Glove, Fast-Text
Benchmark Performance of Machine And Deep Learning Based Methodologies for Urdu Text Document Classification
Mar 03, 2020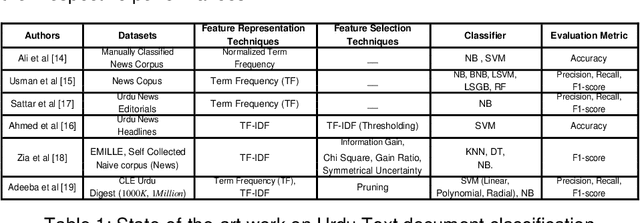
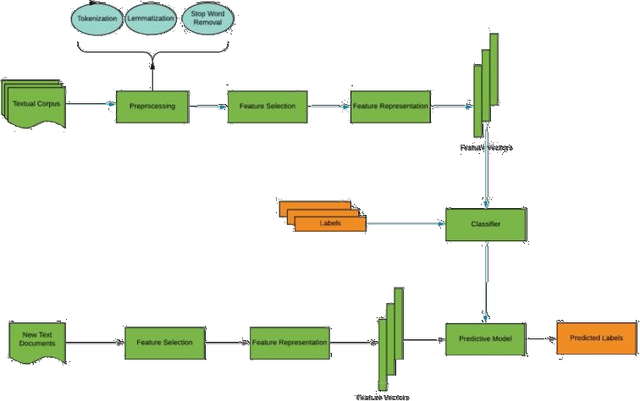
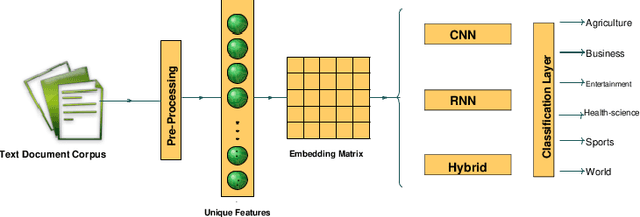

In order to provide benchmark performance for Urdu text document classification, the contribution of this paper is manifold. First, it pro-vides a publicly available benchmark dataset manually tagged against 6 classes. Second, it investigates the performance impact of traditional machine learning based Urdu text document classification methodologies by embedding 10 filter-based feature selection algorithms which have been widely used for other languages. Third, for the very first time, it as-sesses the performance of various deep learning based methodologies for Urdu text document classification. In this regard, for experimentation, we adapt 10 deep learning classification methodologies which have pro-duced best performance figures for English text classification. Fourth, it also investigates the performance impact of transfer learning by utiliz-ing Bidirectional Encoder Representations from Transformers approach for Urdu language. Fifth, it evaluates the integrity of a hybrid approach which combines traditional machine learning based feature engineering and deep learning based automated feature engineering. Experimental results show that feature selection approach named as Normalised Dif-ference Measure along with Support Vector Machine outshines state-of-the-art performance on two closed source benchmark datasets CLE Urdu Digest 1000k, and CLE Urdu Digest 1Million with a significant margin of 32%, and 13% respectively. Across all three datasets, Normalised Differ-ence Measure outperforms other filter based feature selection algorithms as it significantly uplifts the performance of all adopted machine learning, deep learning, and hybrid approaches. The source code and presented dataset are available at Github repository.
Integrating Data and Image Domain Deep Learning for Limited Angle Tomography using Consensus Equilibrium
Aug 31, 2019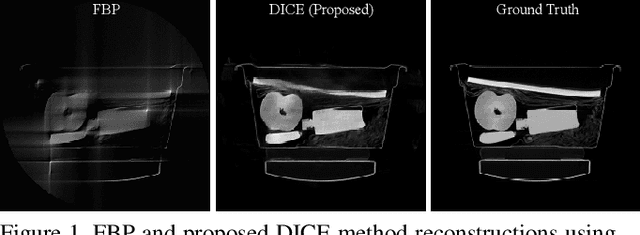
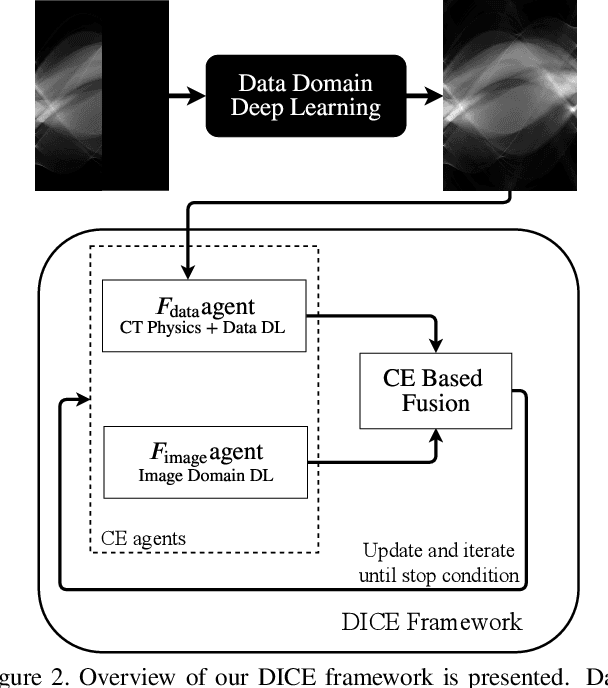

Computed Tomography (CT) is a non-invasive imaging modality with applications ranging from healthcare to security. It reconstructs cross-sectional images of an object using a collection of projection data collected at different angles. Conventional methods, such as FBP, require that the projection data be uniformly acquired over the complete angular range. In some applications, it is not possible to acquire such data. Security is one such domain where non-rotational scanning configurations are being developed which violate the complete data assumption. Conventional methods produce images from such data that are filled with artifacts. The recent success of deep learning (DL) methods has inspired researchers to post-process these artifact laden images using deep neural networks (DNNs). This approach has seen limited success on real CT problems. Another approach has been to pre-process the incomplete data using DNNs aiming to avoid the creation of artifacts altogether. Due to imperfections in the learning process, this approach can still leave perceptible residual artifacts. In this work, we aim to combine the power of deep learning in both the data and image domains through a two-step process based on the consensus equilibrium (CE) framework. Specifically, we use conditional generative adversarial networks (cGANs) in both the data and the image domain for enhanced performance and efficient computation and combine them through a consensus process. We demonstrate the effectiveness of our approach on a real security CT dataset for a challenging 90 degree limited-angle problem. The same framework can be applied to other limited data problems arising in applications such as electron microscopy, non-destructive evaluation, and medical imaging.
Fast Accurate CT Metal Artifact Reduction using Data Domain Deep Learning
Apr 10, 2019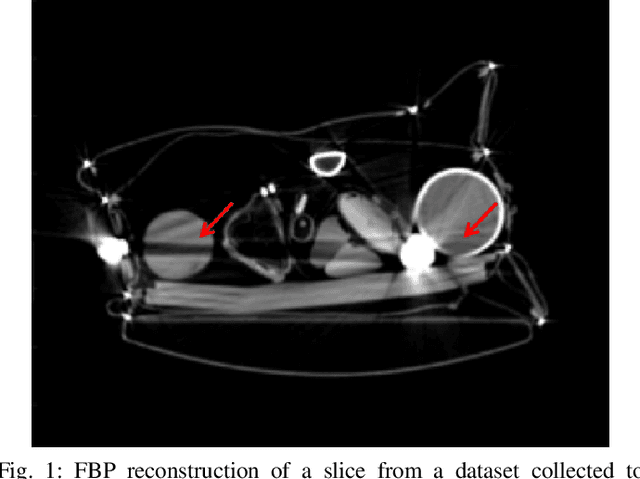
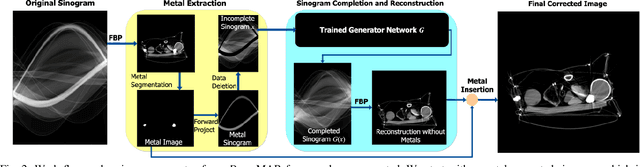
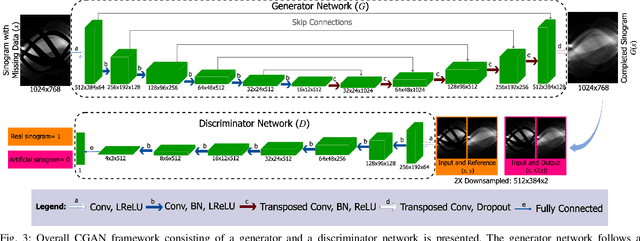

Filtered back projection (FBP) is the most widely used method for image reconstruction in X-ray computed tomography (CT) scanners. The presence of hyper-dense materials in a scene, such as metals, can strongly attenuate X-rays, producing severe streaking artifacts in the reconstruction. These metal artifacts can greatly limit subsequent object delineation and information extraction from the images, restricting their diagnostic value. This problem is particularly acute in the security domain, where there is great heterogeneity in the objects that can appear in a scene, highly accurate decisions must be made quickly. The standard practical approaches to reducing metal artifacts in CT imagery are either simplistic non-adaptive interpolation-based projection data completion methods or direct image post-processing methods. These standard approaches have had limited success. Motivated primarily by security applications, we present a new deep-learning-based metal artifact reduction (MAR) approach that tackles the problem in the projection data domain. We treat the projection data corresponding to metal objects as missing data and train an adversarial deep network to complete the missing data in the projection domain. The subsequent complete projection data is then used with FBP to reconstruct image intended to be free of artifacts. This new approach results in an end-to-end MAR algorithm that is computationally efficient so practical and fits well into existing CT workflows allowing easy adoption in existing scanners. Training deep networks can be challenging, and another contribution of our work is to demonstrate that training data generated using an accurate X-ray simulation can be used to successfully train the deep network when combined with transfer learning using limited real data sets. We demonstrate the effectiveness and potential of our algorithm on simulated and real examples.
Dendritic Spine Shape Analysis: A Clustering Perspective
Jul 19, 2016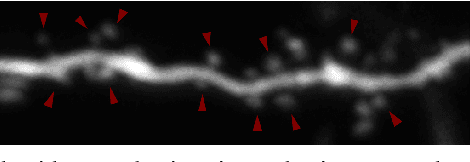

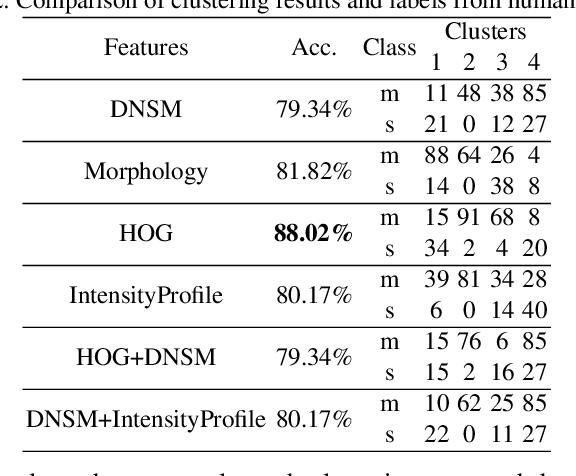

Functional properties of neurons are strongly coupled with their morphology. Changes in neuronal activity alter morphological characteristics of dendritic spines. First step towards understanding the structure-function relationship is to group spines into main spine classes reported in the literature. Shape analysis of dendritic spines can help neuroscientists understand the underlying relationships. Due to unavailability of reliable automated tools, this analysis is currently performed manually which is a time-intensive and subjective task. Several studies on spine shape classification have been reported in the literature, however, there is an on-going debate on whether distinct spine shape classes exist or whether spines should be modeled through a continuum of shape variations. Another challenge is the subjectivity and bias that is introduced due to the supervised nature of classification approaches. In this paper, we aim to address these issues by presenting a clustering perspective. In this context, clustering may serve both confirmation of known patterns and discovery of new ones. We perform cluster analysis on two-photon microscopic images of spines using morphological, shape, and appearance based features and gain insights into the spine shape analysis problem. We use histogram of oriented gradients (HOG), disjunctive normal shape models (DNSM), morphological features, and intensity profile based features for cluster analysis. We use x-means to perform cluster analysis that selects the number of clusters automatically using the Bayesian information criterion (BIC). For all features, this analysis produces 4 clusters and we observe the formation of at least one cluster consisting of spines which are difficult to be assigned to a known class. This observation supports the argument of intermediate shape types.