 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Precisely Xtreme-Multi Channel Hybrid Approach For Roman Urdu Sentiment Analysis
Mar 11, 2020

In order to accelerate the performance of various Natural Language Processing tasks for Roman Urdu, this paper for the very first time provides 3 neural word embeddings prepared using most widely used approaches namely Word2vec, FastText, and Glove. The integrity of generated neural word embeddings is evaluated using intrinsic and extrinsic evaluation approaches. Considering the lack of publicly available benchmark datasets, it provides a first-ever Roman Urdu dataset which consists of 3241 sentiments annotated against positive, negative and neutral classes. To provide benchmark baseline performance over the presented dataset, we adapt diverse machine learning (Support Vector Machine Logistic Regression, Naive Bayes), deep learning (convolutional neural network, recurrent neural network), and hybrid approaches. Effectiveness of generated neural word embeddings is evaluated by comparing the performance of machine and deep learning based methodologies using 7, and 5 distinct feature representation approaches respectively. Finally, it proposes a novel precisely extreme multi-channel hybrid methodology which outperforms state-of-the-art adapted machine and deep learning approaches by the figure of 9%, and 4% in terms of F1-score. Roman Urdu Sentiment Analysis, Pretrain word embeddings for Roman Urdu, Word2Vec, Glove, Fast-Text
Benchmark Performance of Machine And Deep Learning Based Methodologies for Urdu Text Document Classification
Mar 03, 2020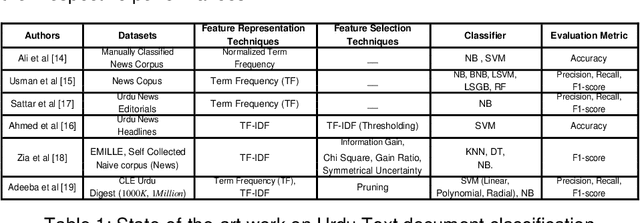
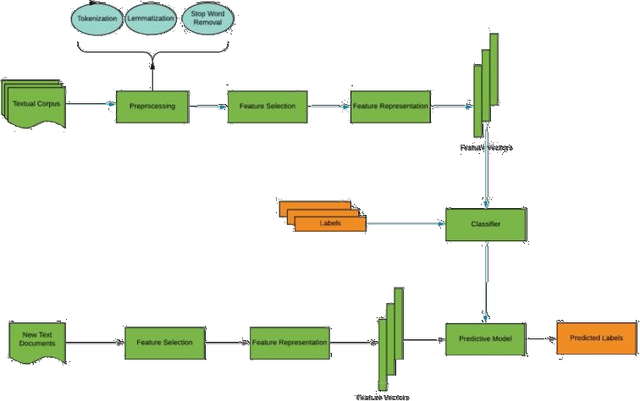
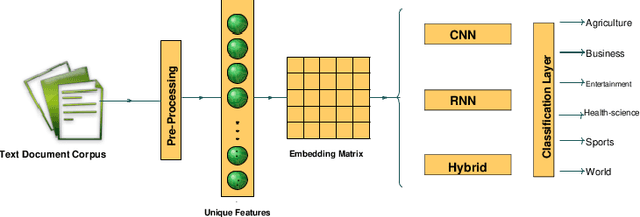

In order to provide benchmark performance for Urdu text document classification, the contribution of this paper is manifold. First, it pro-vides a publicly available benchmark dataset manually tagged against 6 classes. Second, it investigates the performance impact of traditional machine learning based Urdu text document classification methodologies by embedding 10 filter-based feature selection algorithms which have been widely used for other languages. Third, for the very first time, it as-sesses the performance of various deep learning based methodologies for Urdu text document classification. In this regard, for experimentation, we adapt 10 deep learning classification methodologies which have pro-duced best performance figures for English text classification. Fourth, it also investigates the performance impact of transfer learning by utiliz-ing Bidirectional Encoder Representations from Transformers approach for Urdu language. Fifth, it evaluates the integrity of a hybrid approach which combines traditional machine learning based feature engineering and deep learning based automated feature engineering. Experimental results show that feature selection approach named as Normalised Dif-ference Measure along with Support Vector Machine outshines state-of-the-art performance on two closed source benchmark datasets CLE Urdu Digest 1000k, and CLE Urdu Digest 1Million with a significant margin of 32%, and 13% respectively. Across all three datasets, Normalised Differ-ence Measure outperforms other filter based feature selection algorithms as it significantly uplifts the performance of all adopted machine learning, deep learning, and hybrid approaches. The source code and presented dataset are available at Github repository.