 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bayesian Generative Adversarial Network (GAN) to Generate Synthetic Time-Series Data, Application in Combined Sewer Flow Prediction
Jan 31, 2023Despite various breakthroughs in machine learning and data analysis techniques for improving smart operation and management of urban water infrastructures, some key limitations obstruct this progress. Among these shortcomings, the absence of freely available data due to data privacy or high costs of data gathering and the nonexistence of adequate rare or extreme events in the available data plays a crucial role. Here, Generative Adversarial Networks (GANs) can help overcome these challenges. In machine learning, generative models are a class of methods capable of learning data distribution to generate artificial data. In this study, we developed a GAN model to generate synthetic time series to balance our limited recorded time series data and improve the accuracy of a data-driven model for combined sewer flow prediction. We considered the sewer system of a small town in Germany as the test case. Precipitation and inflow to the storage tanks are used for the Data-Driven model development. The aim is to predict the flow using precipitation data and examine the impact of data augmentation using synthetic data in model performance. Results show that GAN can successfully generate synthetic time series from real data distribution, which helps more accurate peak flow prediction. However, the model without data augmentation works better for dry weather prediction. Therefore, an ensemble model is suggested to combine the advantages of both models.
Benchmark Performance of Machine And Deep Learning Based Methodologies for Urdu Text Document Classification
Mar 03, 2020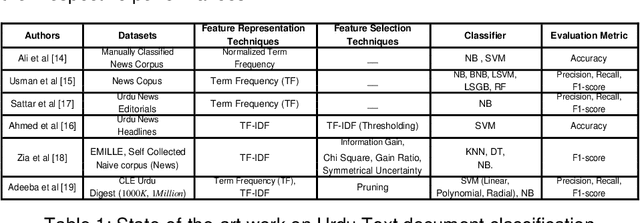
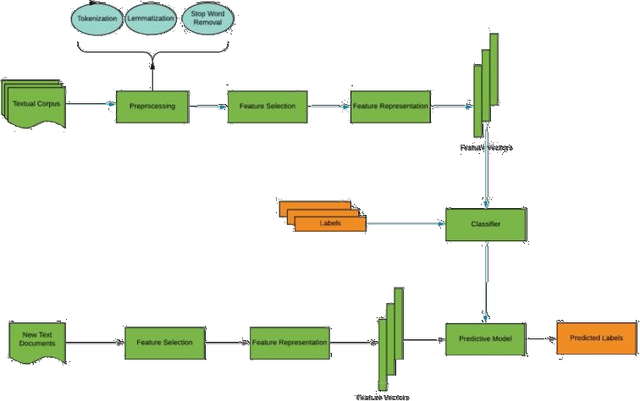
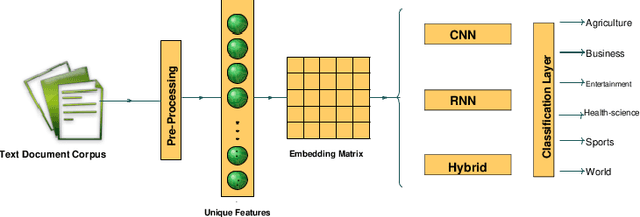

In order to provide benchmark performance for Urdu text document classification, the contribution of this paper is manifold. First, it pro-vides a publicly available benchmark dataset manually tagged against 6 classes. Second, it investigates the performance impact of traditional machine learning based Urdu text document classification methodologies by embedding 10 filter-based feature selection algorithms which have been widely used for other languages. Third, for the very first time, it as-sesses the performance of various deep learning based methodologies for Urdu text document classification. In this regard, for experimentation, we adapt 10 deep learning classification methodologies which have pro-duced best performance figures for English text classification. Fourth, it also investigates the performance impact of transfer learning by utiliz-ing Bidirectional Encoder Representations from Transformers approach for Urdu language. Fifth, it evaluates the integrity of a hybrid approach which combines traditional machine learning based feature engineering and deep learning based automated feature engineering. Experimental results show that feature selection approach named as Normalised Dif-ference Measure along with Support Vector Machine outshines state-of-the-art performance on two closed source benchmark datasets CLE Urdu Digest 1000k, and CLE Urdu Digest 1Million with a significant margin of 32%, and 13% respectively. Across all three datasets, Normalised Differ-ence Measure outperforms other filter based feature selection algorithms as it significantly uplifts the performance of all adopted machine learning, deep learning, and hybrid approaches. The source code and presented dataset are available at Github repository.