 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Patch-Based TDA Approach for Computed Tomography
Dec 13, 2025



The development of machine learning (ML) models based on computed tomography (CT) imaging modality has been a major focus of recent research in the medical imaging domain. Incorporating robust feature engineering approach can highly improve the performance of these models. Topological data analysis (TDA), a recent development based on the mathematical field of algebraic topology, mainly focuses on the data from a topological perspective, extracting deeper insight and higher dimensional structures from the data. Persistent homology (PH), a fundamental tool in the area of TDA, can extract topological features such as connected components, cycles and voids from the data. A popular approach to construct PH from 3D CT images is to utilize the 3D cubical complex filtration, a method adapted for grid-structured data. However, this approach may not always yield the best performance and can suffer from computational complexity with higher resolution CT images. This study introduces a novel patch-based PH construction approach tailored for volumetric medical imaging data, in particular CT modality. A wide range of experiments has been conducted on several datasets of 3D CT images to comprehensively analyze the performance of the proposed method with various parameters and benchmark it against the 3D cubical complex algorithm. Our results highlight the dominance of the patch-based TDA approach in terms of both classification performance and time-efficiency. The proposed approach outperformed the cubical complex method, achieving average improvement of 10.38%, 6.94%, 2.06%, 11.58%, and 8.51% in accuracy, AUC, sensitivity, specificity, and F1 score, respectively, across all datasets. Finally, we provide a convenient python package, Patch-TDA, to facilitate the utilization of the proposed approach.
Finding Reproducible and Prognostic Radiomic Features in Variable Slice Thickness Contrast Enhanced CT of Colorectal Liver Metastases
Jan 20, 2025



Establishing the reproducibility of radiomic signatures is a critical step in the path to clinical adoption of quantitative imaging biomarkers; however, radiomic signatures must also be meaningfully related to an outcome of clinical importance to be of value for personalized medicine. In this study, we analyze both the reproducibility and prognostic value of radiomic features extracted from the liver parenchyma and largest liver metastases in contrast enhanced CT scans of patients with colorectal liver metastases (CRLM). A prospective cohort of 81 patients from two major US cancer centers was used to establish the reproducibility of radiomic features extracted from images reconstructed with different slice thicknesses. A publicly available, single-center cohort of 197 preoperative scans from patients who underwent hepatic resection for treatment of CRLM was used to evaluate the prognostic value of features and models to predict overall survival. A standard set of 93 features was extracted from all images, with a set of eight different extractor settings. The feature extraction settings producing the most reproducible, as well as the most prognostically discriminative feature values were highly dependent on both the region of interest and the specific feature in question. While the best overall predictive model was produced using features extracted with a particular setting, without accounting for reproducibility, (C-index = 0.630 (0.603--0.649)) an equivalent-performing model (C-index = 0.629 (0.605--0.645)) was produced by pooling features from all extraction settings, and thresholding features with low reproducibility ($\mathrm{CCC} \geq 0.85$), prior to feature selection. Our findings support a data-driven approach to feature extraction and selection, preferring the inclusion of many features, and narrowing feature selection based on reproducibility when relevant data is available.
* Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://melba-journal.org/2024:032
Towards Optimal Patch Size in Vision Transformers for Tumor Segmentation
Aug 31, 2023Detection of tumors in metastatic colorectal cancer (mCRC) plays an essential role in the early diagnosis and treatment of liver cancer. Deep learning models backboned by fully convolutional neural networks (FCNNs) have become the dominant model for segmenting 3D computerized tomography (CT) scans. However, since their convolution layers suffer from limited kernel size, they are not able to capture long-range dependencies and global context. To tackle this restriction, vision transformers have been introduced to solve FCNN's locality of receptive fields. Although transformers can capture long-range features, their segmentation performance decreases with various tumor sizes due to the model sensitivity to the input patch size. While finding an optimal patch size improves the performance of vision transformer-based models on segmentation tasks, it is a time-consuming and challenging procedure. This paper proposes a technique to select the vision transformer's optimal input multi-resolution image patch size based on the average volume size of metastasis lesions. We further validated our suggested framework using a transfer-learning technique, demonstrating that the highest Dice similarity coefficient (DSC) performance was obtained by pre-training on training data with a larger tumour volume using the suggested ideal patch size and then training with a smaller one. We experimentally evaluate this idea through pre-training our model on a multi-resolution public dataset. Our model showed consistent and improved results when applied to our private multi-resolution mCRC dataset with a smaller average tumor volume. This study lays the groundwork for optimizing semantic segmentation of small objects using vision transformers. The implementation source code is available at:https://github.com/Ramtin-Mojtahedi/OVTPS.
Attention-based CT Scan Interpolation for Lesion Segmentation of Colorectal Liver Metastases
Aug 30, 2023Small liver lesions common to colorectal liver metastases (CRLMs) are challenging for convolutional neural network (CNN) segmentation models, especially when we have a wide range of slice thicknesses in the computed tomography (CT) scans. Slice thickness of CT images may vary by clinical indication. For example, thinner slices are used for presurgical planning when fine anatomic details of small vessels are required. While keeping the effective radiation dose in patients as low as possible, various slice thicknesses are employed in CRLMs due to their limitations. However, differences in slice thickness across CTs lead to significant performance degradation in CT segmentation models based on CNNs. This paper proposes a novel unsupervised attention-based interpolation model to generate intermediate slices from consecutive triplet slices in CT scans. We integrate segmentation loss during the interpolation model's training to leverage segmentation labels in existing slices to generate middle ones. Unlike common interpolation techniques in CT volumes, our model highlights the regions of interest (liver and lesions) inside the abdominal CT scans in the interpolated slice. Moreover, our model's outputs are consistent with the original input slices while increasing the segmentation performance in two cutting-edge 3D segmentation pipelines. We tested the proposed model on the CRLM dataset to upsample subjects with thick slices and create isotropic volume for our segmentation model. The produced isotropic dataset increases the Dice score in the segmentation of lesions and outperforms other interpolation approaches in terms of interpolation metrics.
Federated Learning Enables Big Data for Rare Cancer Boundary Detection
Apr 25, 2022Although machine learning (ML) has shown promise in numerous domains, there are concerns about generalizability to out-of-sample data. This is currently addressed by centrally sharing ample, and importantly diverse, data from multiple sites. However, such centralization is challenging to scale (or even not feasible) due to various limitations. Federated ML (FL) provides an alternative to train accurate and generalizable ML models, by only sharing numerical model updates. Here we present findings from the largest FL study to-date, involving data from 71 healthcare institutions across 6 continents, to generate an automatic tumor boundary detector for the rare disease of glioblastoma, utilizing the largest dataset of such patients ever used in the literature (25,256 MRI scans from 6,314 patients). We demonstrate a 33% improvement over a publicly trained model to delineate the surgically targetable tumor, and 23% improvement over the tumor's entire extent. We anticipate our study to: 1) enable more studies in healthcare informed by large and diverse data, ensuring meaningful results for rare diseases and underrepresented populations, 2) facilitate further quantitative analyses for glioblastoma via performance optimization of our consensus model for eventual public release, and 3) demonstrate the effectiveness of FL at such scale and task complexity as a paradigm shift for multi-site collaborations, alleviating the need for data sharing.
Modality Completion via Gaussian Process Prior Variational Autoencoders for Multi-Modal Glioma Segmentation
Jul 07, 2021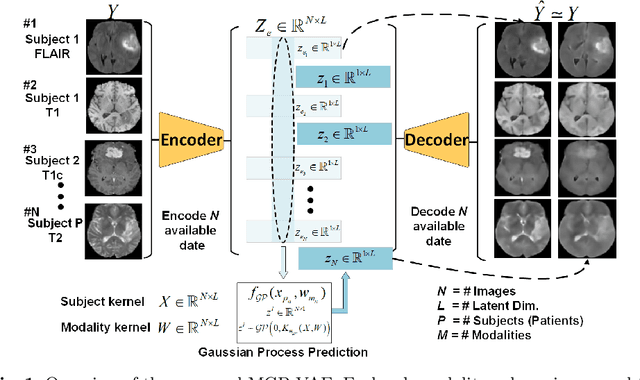
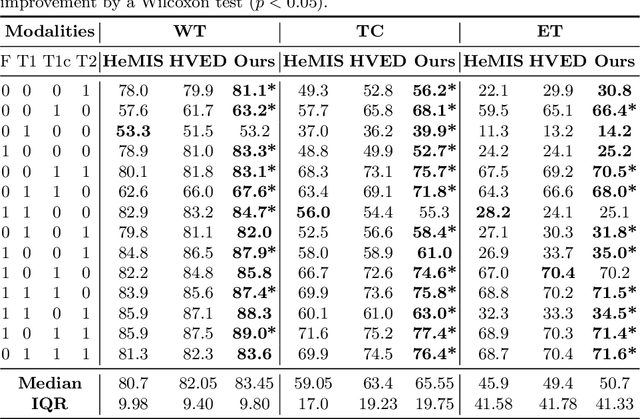
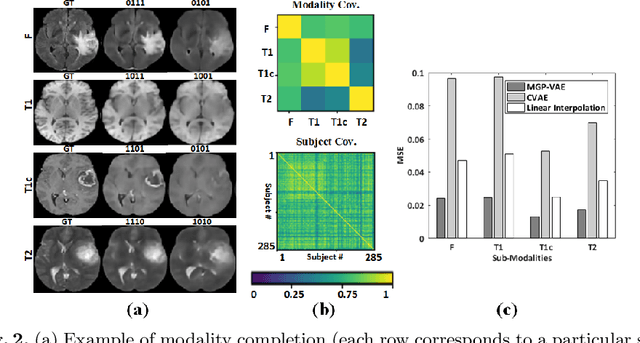
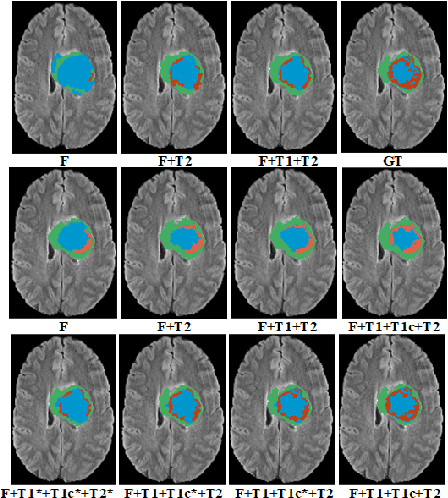
In large studies involving multi protocol Magnetic Resonance Imaging (MRI), it can occur to miss one or more sub-modalities for a given patient owing to poor quality (e.g. imaging artifacts), failed acquisitions, or hallway interrupted imaging examinations. In some cases, certain protocols are unavailable due to limited scan time or to retrospectively harmonise the imaging protocols of two independent studies. Missing image modalities pose a challenge to segmentation frameworks as complementary information contributed by the missing scans is then lost. In this paper, we propose a novel model, Multi-modal Gaussian Process Prior Variational Autoencoder (MGP-VAE), to impute one or more missing sub-modalities for a patient scan. MGP-VAE can leverage the Gaussian Process (GP) prior on the Variational Autoencoder (VAE) to utilize the subjects/patients and sub-modalities correlations. Instead of designing one network for each possible subset of present sub-modalities or using frameworks to mix feature maps, missing data can be generated from a single model based on all the available samples. We show the applicability of MGP-VAE on brain tumor segmentation where either, two, or three of four sub-modalities may be missing. Our experiments against competitive segmentation baselines with missing sub-modality on BraTS'19 dataset indicate the effectiveness of the MGP-VAE model for segmentation tasks.
Convolutional 3D to 2D Patch Conversion for Pixel-wise Glioma Segmentation in MRI Scans
Oct 20, 2020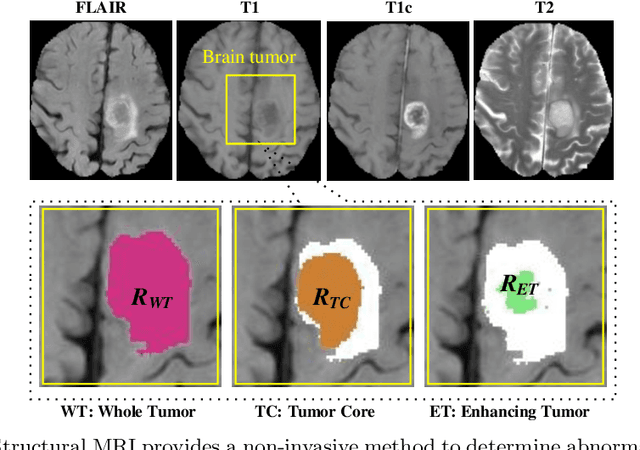
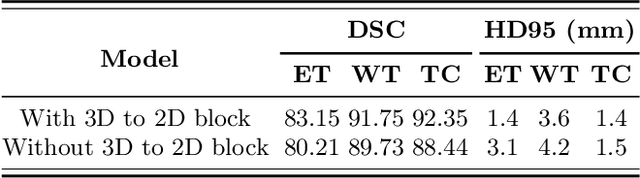
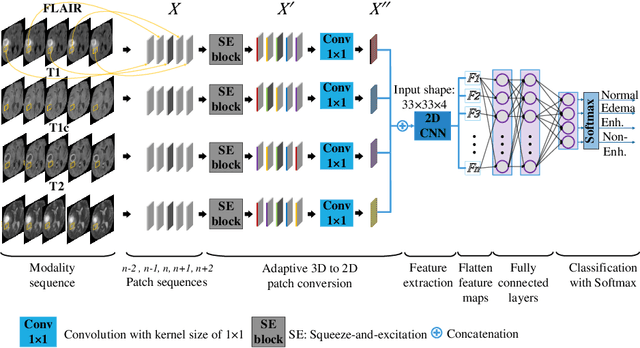
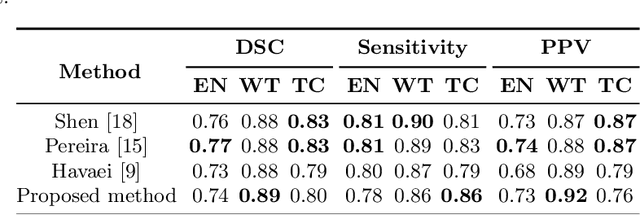
Structural magnetic resonance imaging (MRI) has been widely utilized for analysis and diagnosis of brain diseases. Automatic segmentation of brain tumors is a challenging task for computer-aided diagnosis due to low-tissue contrast in the tumor subregions. To overcome this, we devise a novel pixel-wise segmentation framework through a convolutional 3D to 2D MR patch conversion model to predict class labels of the central pixel in the input sliding patches. Precisely, we first extract 3D patches from each modality to calibrate slices through the squeeze and excitation (SE) block. Then, the output of the SE block is fed directly into subsequent bottleneck layers to reduce the number of channels. Finally, the calibrated 2D slices are concatenated to obtain multimodal features through a 2D convolutional neural network (CNN) for prediction of the central pixel. In our architecture, both local inter-slice and global intra-slice features are jointly exploited to predict class label of the central voxel in a given patch through the 2D CNN classifier. We implicitly apply all modalities through trainable parameters to assign weights to the contributions of each sequence for segmentation. Experimental results on the segmentation of brain tumors in multimodal MRI scans (BraTS'19) demonstrate that our proposed method can efficiently segment the tumor regions.
High Tissue Contrast MRI Synthesis Using Multi-Stage Attention-GAN for Glioma Segmentation
Jun 09, 2020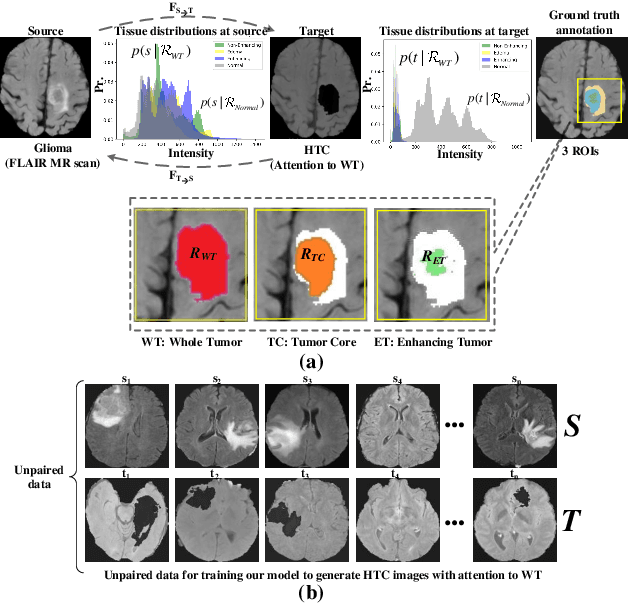
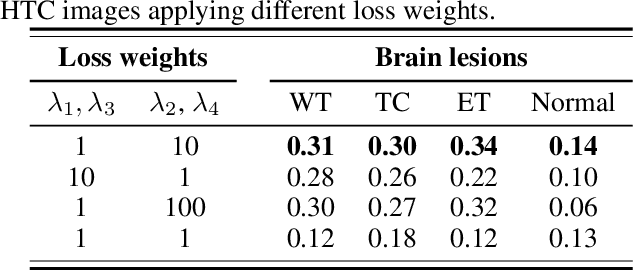
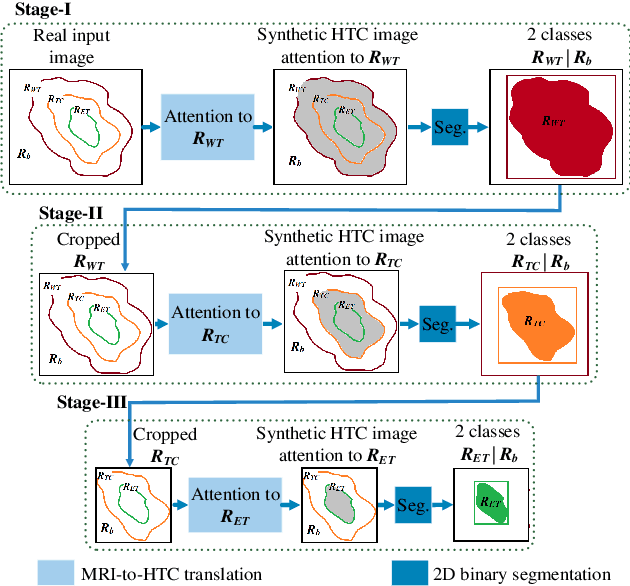
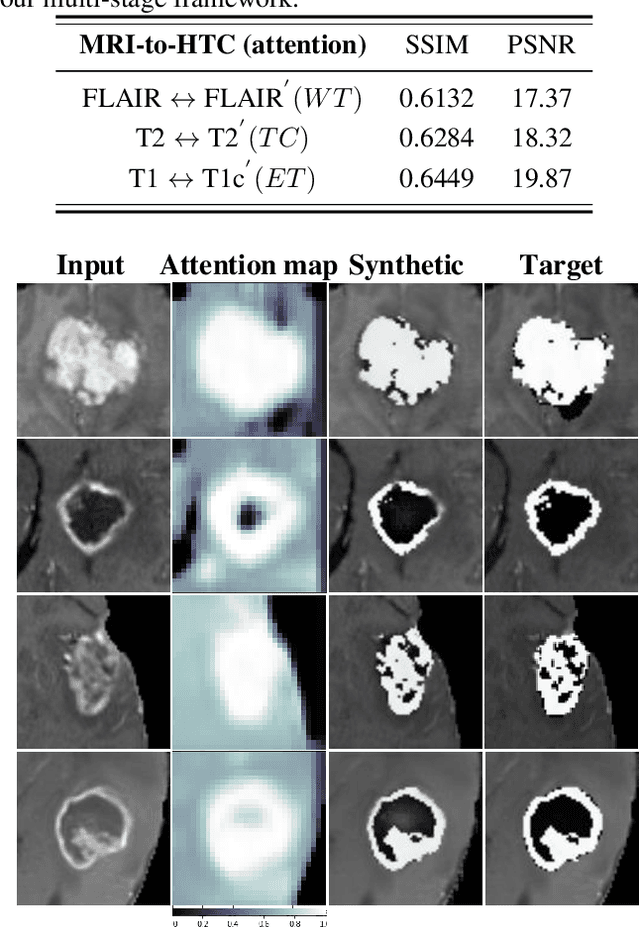
Magnetic resonance imaging (MRI) provides varying tissue contrast images of internal organs based on a strong magnetic field. Despite the non-invasive advantage of MRI in frequent imaging, the low contrast MR images in the target area make tissue segmentation a challenging problem. This paper demonstrates the potential benefits of image-to-image translation techniques to generate synthetic high tissue contrast (HTC) images. Notably, we adopt a new cycle generative adversarial network (CycleGAN) with an attention mechanism to increase the contrast within underlying tissues. The attention block, as well as training on HTC images, guides our model to converge on certain tissues. To increase the resolution of HTC images, we employ multi-stage architecture to focus on one particular tissue as a foreground and filter out the irrelevant background in each stage. This multi-stage structure also alleviates the common artifacts of the synthetic images by decreasing the gap between source and target domains. We show the application of our method for synthesizing HTC images on brain MR scans, including glioma tumor. We also employ HTC MR images in both the end-to-end and two-stage segmentation structure to confirm the effectiveness of these images. The experiments over three competitive segmentation baselines on BraTS 2018 dataset indicate that incorporating the synthetic HTC images in the multi-modal segmentation framework improves the average Dice scores 0.8%, 0.6%, and 0.5% on the whole tumor, tumor core, and enhancing tumor, respectively, while eliminating one real MRI sequence from the segmentation procedure.
Brain Tumor Synthetic Segmentation in 3D Multimodal MRI Scans
Sep 27, 2019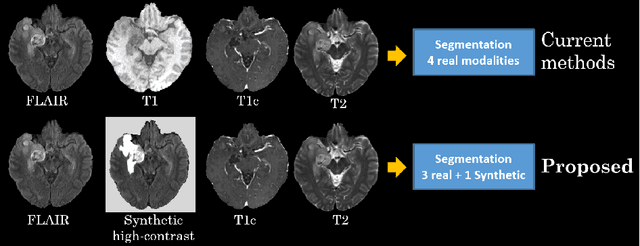
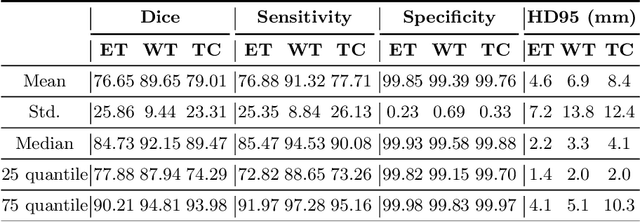
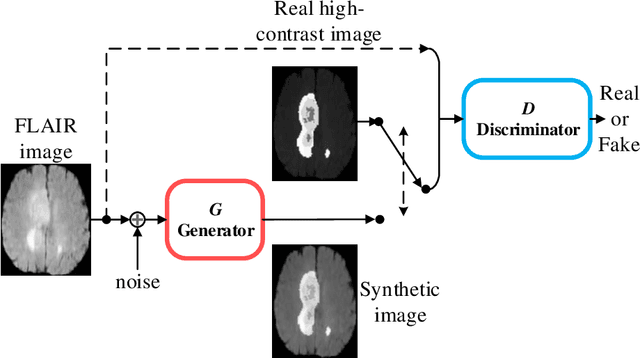
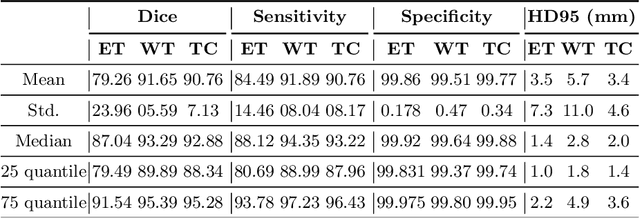
The magnetic resonance (MR) analysis of brain tumors is widely used for diagnosis and examination of tumor subregions. The overlapping area among the intensity distribution of healthy, enhancing, non-enhancing, and edema region makes the automatic segmentation a challenging task. Here, we show that a convolutional neural network trained on high-contrast images can transform intensity distribution of brain lesion in its internal subregions. Specifically, generative adversarial network (GAN) is extended to synthesize high-contrast images. A comparison of these synthetic images and real images of brain tumor tissue in MR scans showed significant segmentation improvement and decreased the number of real channels for segmentation. The synthetic images are used as a substitute for real channels and can bypass real modalities in the multimodal brain tumor segmentation framework. Segmentation results on BraTS 2019 dataset demonstrate that our proposed approach can efficiently segment the tumor areas.