 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing LLMs to Investigate the Disputed Role of Evidence in Electronic Cigarette Health Policy Formation in Australia and the UK
May 10, 2025Australia and the UK have developed contrasting approaches to the regulation of electronic cigarettes, with - broadly speaking - Australia adopting a relatively restrictive approach and the UK adopting a more permissive approach. Notably, these divergent policies were developed from the same broad evidence base. In this paper, to investigate differences in how the two jurisdictions manage and present evidence, we developed and evaluated a Large Language Model-based sentence classifier to perform automated analyses of electronic cigarette-related policy documents drawn from official Australian and UK legislative processes (109 documents in total). Specifically, we utilized GPT-4 to automatically classify sentences based on whether they contained claims that e-cigarettes were broadly helpful or harmful for public health. Our LLM-based classifier achieved an F-score of 0.9. Further, when applying the classifier to our entire sentence-level corpus, we found that Australian legislative documents show a much higher proportion of harmful statements, and a lower proportion of helpful statements compared to the expected values, with the opposite holding for the UK. In conclusion, this work utilized an LLM-based approach to provide evidence to support the contention that - drawing on the same evidence base - Australian ENDS-related policy documents emphasize the harms associated with ENDS products and UK policy documents emphasize the benefits. Further, our approach provides a starting point for using LLM-based methods to investigate the complex relationship between evidence and health policy formation.
Query pipeline optimization for cancer patient question answering systems
Dec 19, 2024Retrieval-augmented generation (RAG) mitigates hallucination in Large Language Models (LLMs) by using query pipelines to retrieve relevant external information and grounding responses in retrieved knowledge. However, query pipeline optimization for cancer patient question-answering (CPQA) systems requires separately optimizing multiple components with domain-specific considerations. We propose a novel three-aspect optimization approach for the RAG query pipeline in CPQA systems, utilizing public biomedical databases like PubMed and PubMed Central. Our optimization includes: (1) document retrieval, utilizing a comparative analysis of NCBI resources and introducing Hybrid Semantic Real-time Document Retrieval (HSRDR); (2) passage retrieval, identifying optimal pairings of dense retrievers and rerankers; and (3) semantic representation, introducing Semantic Enhanced Overlap Segmentation (SEOS) for improved contextual understanding. On a custom-developed dataset tailored for cancer-related inquiries, our optimized RAG approach improved the answer accuracy of Claude-3-haiku by 5.24% over chain-of-thought prompting and about 3% over a naive RAG setup. This study highlights the importance of domain-specific query optimization in realizing the full potential of RAG and provides a robust framework for building more accurate and reliable CPQA systems, advancing the development of RAG-based biomedical systems.
Whose Side Are You On? Investigating the Political Stance of Large Language Models
Mar 15, 2024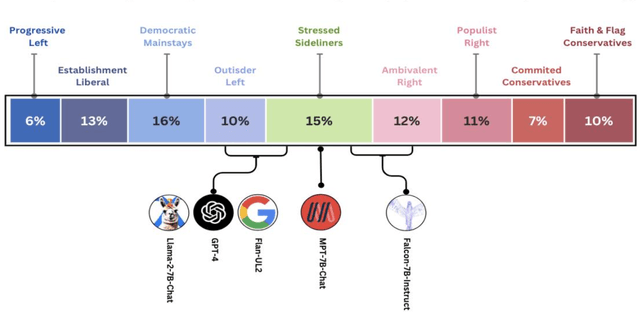
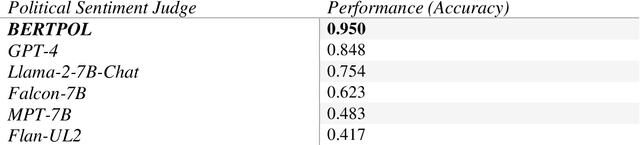
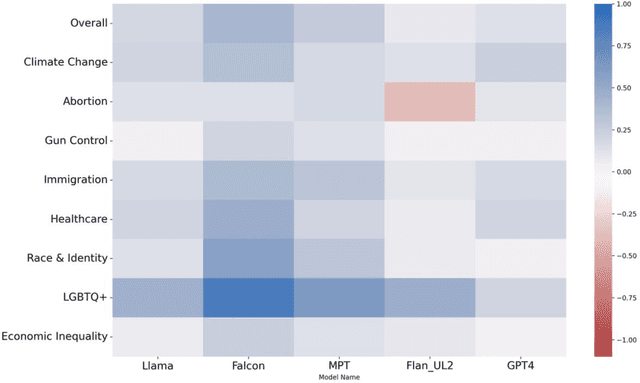

Large Language Models (LLMs) have gained significant popularity for their application in various everyday tasks such as text generation, summarization, and information retrieval. As the widespread adoption of LLMs continues to surge, it becomes increasingly crucial to ensure that these models yield responses that are politically impartial, with the aim of preventing information bubbles, upholding fairness in representation, and mitigating confirmation bias. In this paper, we propose a quantitative framework and pipeline designed to systematically investigate the political orientation of LLMs. Our investigation delves into the political alignment of LLMs across a spectrum of eight polarizing topics, spanning from abortion to LGBTQ issues. Across topics, the results indicate that LLMs exhibit a tendency to provide responses that closely align with liberal or left-leaning perspectives rather than conservative or right-leaning ones when user queries include details pertaining to occupation, race, or political affiliation. The findings presented in this study not only reaffirm earlier observations regarding the left-leaning characteristics of LLMs but also surface particular attributes, such as occupation, that are particularly susceptible to such inclinations even when directly steered towards conservatism. As a recommendation to avoid these models providing politicised responses, users should be mindful when crafting queries, and exercise caution in selecting neutral prompt language.
How Do You #relax When You're #stressed? A Content Analysis and Infodemiology Study of Stress-Related Tweets
Nov 22, 2019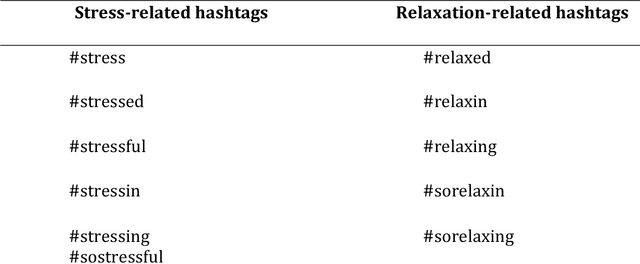
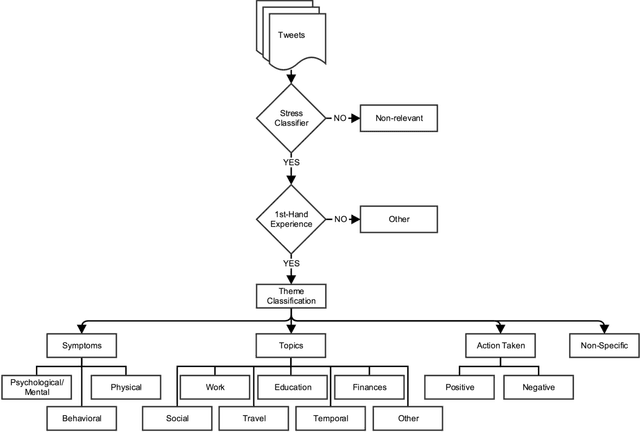
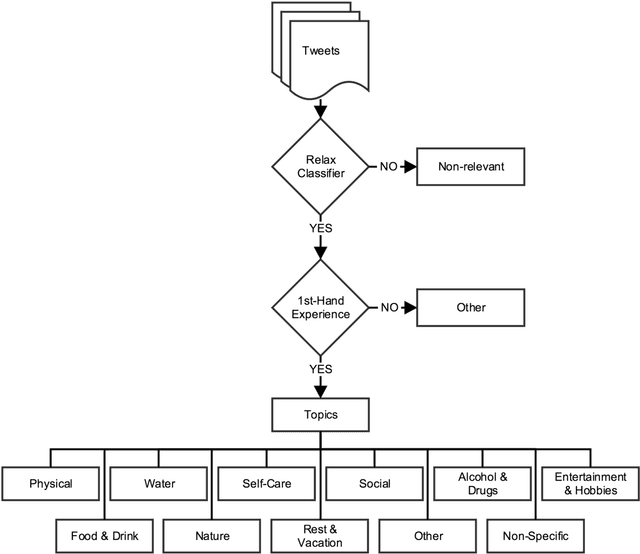
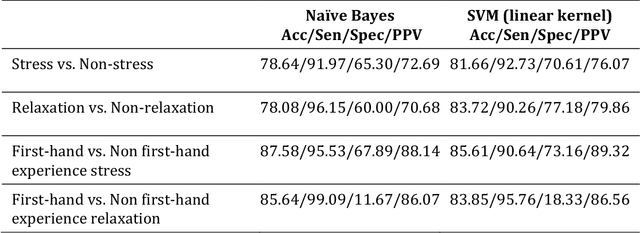
Background: Stress is a contributing factor to many major health problems in the United States, such as heart disease, depression, and autoimmune diseases. Relaxation is often recommended in mental health treatment as a frontline strategy to reduce stress, thereby improving health conditions. Objective: The objective of our study was to understand how people express their feelings of stress and relaxation through Twitter messages. Methods: We first performed a qualitative content analysis of 1326 and 781 tweets containing the keywords "stress" and "relax", respectively. We then investigated the use of machine learning algorithms to automatically classify tweets as stress versus non stress and relaxation versus non relaxation. Finally, we applied these classifiers to sample datasets drawn from 4 cities with the goal of evaluating the extent of any correlation between our automatic classification of tweets and results from public stress surveys. Results: Content analysis showed that the most frequent topic of stress tweets was education, followed by work and social relationships. The most frequent topic of relaxation tweets was rest and vacation, followed by nature and water. When we applied the classifiers to the cities dataset, the proportion of stress tweets in New York and San Diego was substantially higher than that in Los Angeles and San Francisco. Conclusions: This content analysis and infodemiology study revealed that Twitter, when used in conjunction with natural language processing techniques, is a useful data source for understanding stress and stress management strategies, and can potentially supplement infrequently collected survey-based stress data.
* 38 pages,12 figures, 6 tables, 5 Appendix (full version) -- shorter version published in JMIR Public Health Surveill 2017;3(2):e35
An Empirical Study of Sections in Classifying Disease Outbreak Reports
Nov 21, 2019
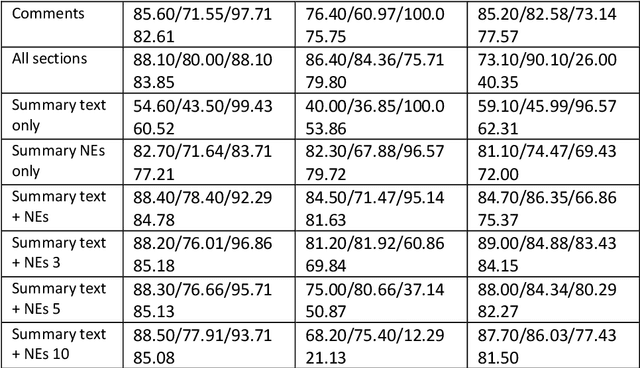
Identifying articles that relate to infectious diseases is a necessary step for any automatic bio-surveillance system that monitors news articles from the Internet. Unlike scientific articles which are available in a strongly structured form, news articles are usually loosely structured. In this chapter, we investigate the importance of each section and the effect of section weighting on performance of text classification. The experimental results show that (1) classification models using the headline and leading sentence achieve a high performance in terms of F-score compared to other parts of the article; (2) all section with bag-of-word representation (full text) achieves the highest recall; and (3) section weighting information can help to improve accuracy.
* 13 pages, 2 tables, book chapter in Web-Based Applications in Healthcare and Biomedicine. Annals of Information Systems, vol 7. Springer, Boston, MA, 2010
Feature Studies to Inform the Classification of Depressive Symptoms from Twitter Data for Population Health
Jan 28, 2017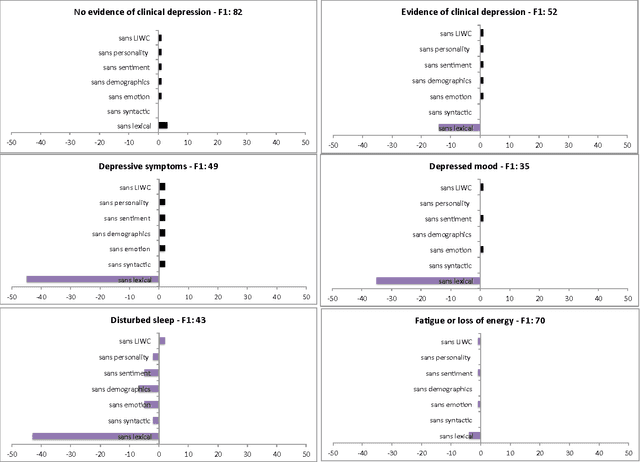
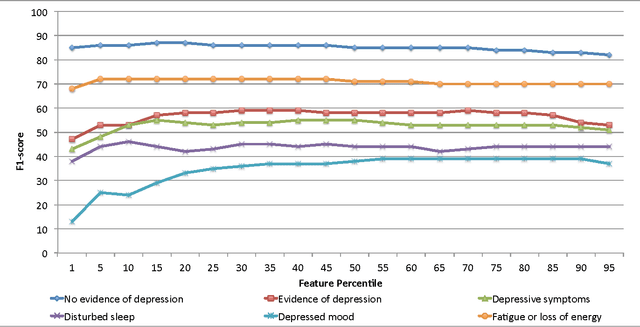
The utility of Twitter data as a medium to support population-level mental health monitoring is not well understood. In an effort to better understand the predictive power of supervised machine learning classifiers and the influence of feature sets for efficiently classifying depression-related tweets on a large-scale, we conducted two feature study experiments. In the first experiment, we assessed the contribution of feature groups such as lexical information (e.g., unigrams) and emotions (e.g., strongly negative) using a feature ablation study. In the second experiment, we determined the percentile of top ranked features that produced the optimal classification performance by applying a three-step feature elimination approach. In the first experiment, we observed that lexical features are critical for identifying depressive symptoms, specifically for depressed mood (-35 points) and for disturbed sleep (-43 points). In the second experiment, we observed that the optimal F1-score performance of top ranked features in percentiles variably ranged across classes e.g., fatigue or loss of energy (5th percentile, 288 features) to depressed mood (55th percentile, 3,168 features) suggesting there is no consistent count of features for predicting depressive-related tweets. We conclude that simple lexical features and reduced feature sets can produce comparable results to larger feature sets.
Natural Language Processing in Biomedicine: A Unified System Architecture Overview
Jan 08, 2014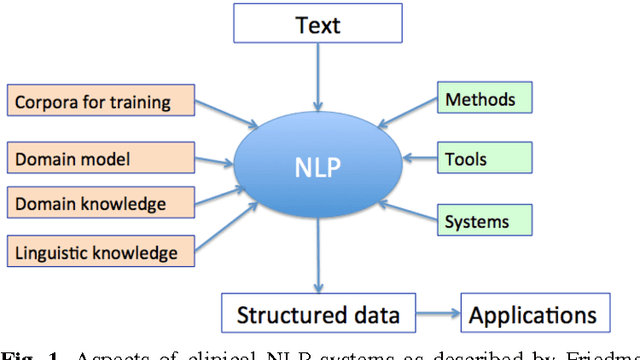
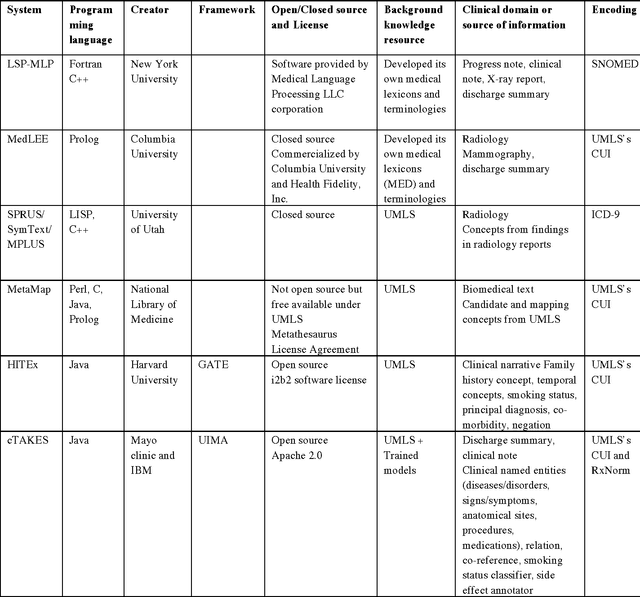
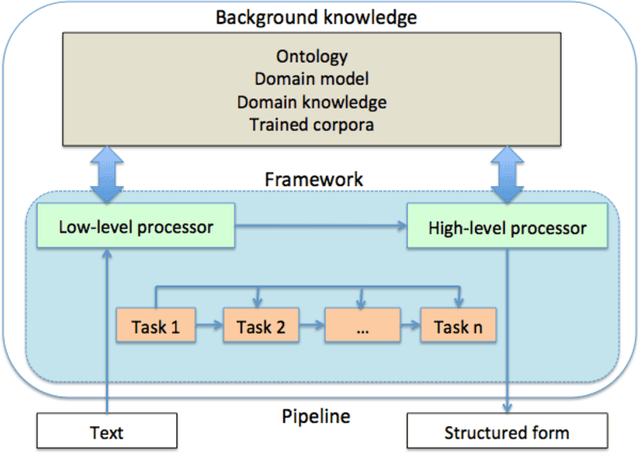
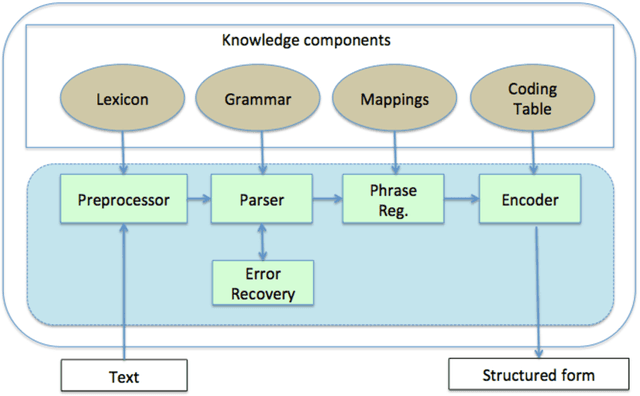
In modern electronic medical records (EMR) much of the clinically important data - signs and symptoms, symptom severity, disease status, etc. - are not provided in structured data fields, but rather are encoded in clinician generated narrative text. Natural language processing (NLP) provides a means of "unlocking" this important data source for applications in clinical decision support, quality assurance, and public health. This chapter provides an overview of representative NLP systems in biomedicine based on a unified architectural view. A general architecture in an NLP system consists of two main components: background knowledge that includes biomedical knowledge resources and a framework that integrates NLP tools to process text. Systems differ in both components, which we will review briefly. Additionally, challenges facing current research efforts in biomedical NLP include the paucity of large, publicly available annotated corpora, although initiatives that facilitate data sharing, system evaluation, and collaborative work between researchers in clinical NLP are starting to emerge.