 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask formulation for Extracting Social Determinants of Health from Clinical Narratives
Jan 26, 2023
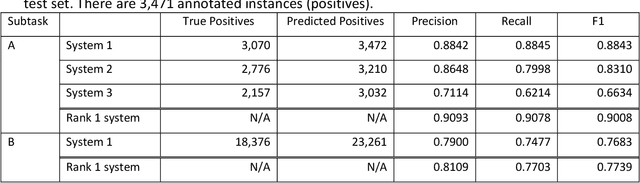
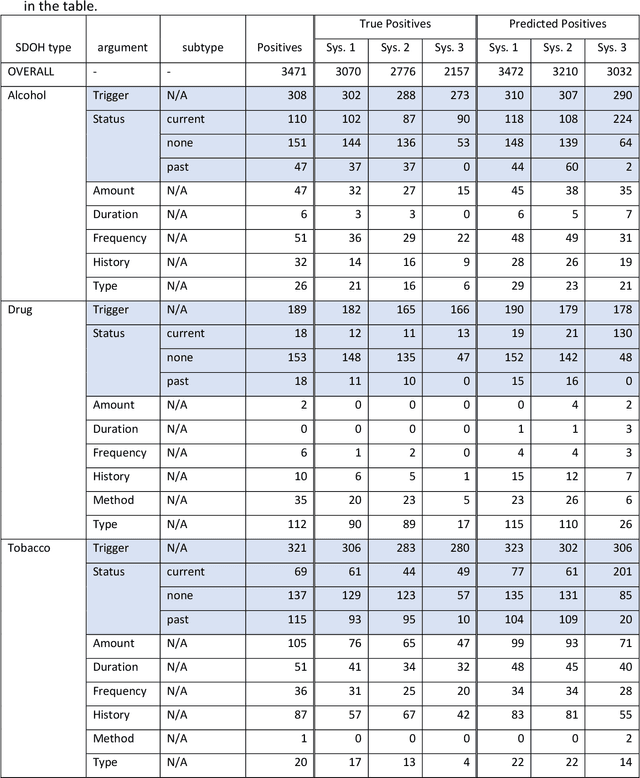
Objective: The 2022 n2c2 NLP Challenge posed identification of social determinants of health (SDOH) in clinical narratives. We present three systems that we developed for the Challenge and discuss the distinctive task formulation used in each of the three systems. Materials and Methods: The first system identifies target pieces of information independently using machine learning classifiers. The second system uses a large language model (LLM) to extract complete structured outputs per document. The third system extracts candidate phrases using machine learning and identifies target relations with hand-crafted rules. Results: The three systems achieved F1 scores of 0.884, 0.831, and 0.663 in the Subtask A of the Challenge, which are ranked third, seventh, and eighth among the 15 participating teams. The review of the extraction results from our systems reveals characteristics of each approach and those of the SODH extraction task. Discussion: Phrases and relations annotated in the task is unique and diverse, not conforming to the conventional event extraction task. These annotations are difficult to model with limited training data. The system that extracts information independently, ignoring the annotated relations, achieves the highest F1 score. Meanwhile, LLM with its versatile capability achieves the high F1 score, while respecting the annotated relations. The rule-based system tackling relation extraction obtains the low F1 score, while it is the most explainable approach. Conclusion: The F1 scores of the three systems vary in this challenge setting, but each approach has advantages and disadvantages in a practical application. The selection of the approach depends not only on the F1 score but also on the requirements in the application.
How Do You #relax When You're #stressed? A Content Analysis and Infodemiology Study of Stress-Related Tweets
Nov 22, 2019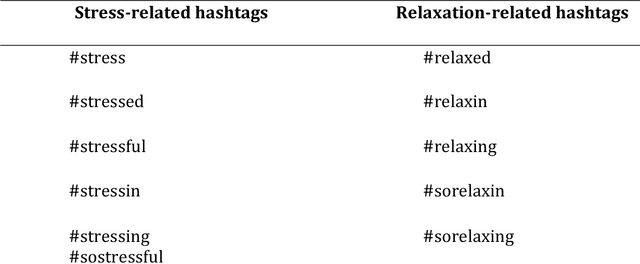
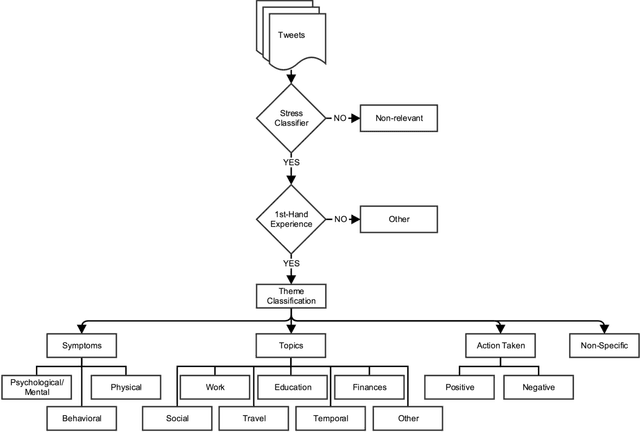
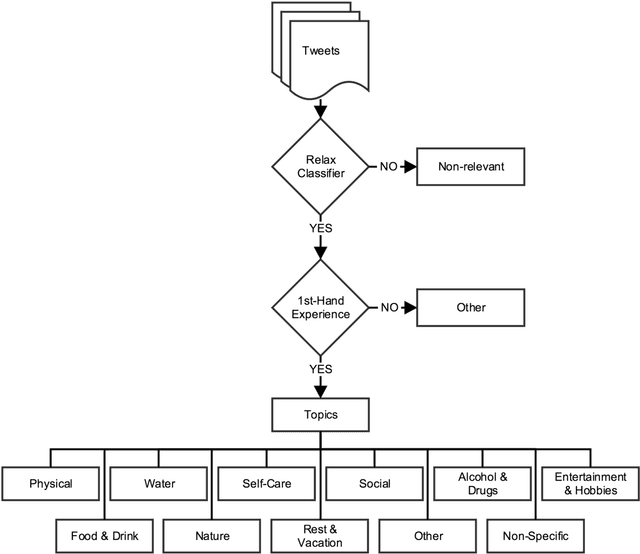
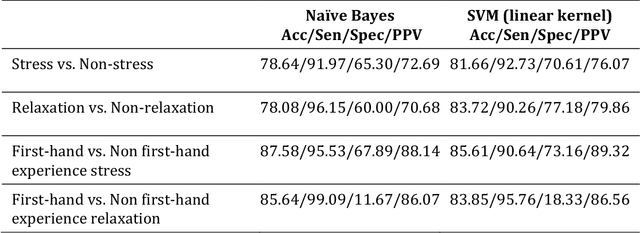
Background: Stress is a contributing factor to many major health problems in the United States, such as heart disease, depression, and autoimmune diseases. Relaxation is often recommended in mental health treatment as a frontline strategy to reduce stress, thereby improving health conditions. Objective: The objective of our study was to understand how people express their feelings of stress and relaxation through Twitter messages. Methods: We first performed a qualitative content analysis of 1326 and 781 tweets containing the keywords "stress" and "relax", respectively. We then investigated the use of machine learning algorithms to automatically classify tweets as stress versus non stress and relaxation versus non relaxation. Finally, we applied these classifiers to sample datasets drawn from 4 cities with the goal of evaluating the extent of any correlation between our automatic classification of tweets and results from public stress surveys. Results: Content analysis showed that the most frequent topic of stress tweets was education, followed by work and social relationships. The most frequent topic of relaxation tweets was rest and vacation, followed by nature and water. When we applied the classifiers to the cities dataset, the proportion of stress tweets in New York and San Diego was substantially higher than that in Los Angeles and San Francisco. Conclusions: This content analysis and infodemiology study revealed that Twitter, when used in conjunction with natural language processing techniques, is a useful data source for understanding stress and stress management strategies, and can potentially supplement infrequently collected survey-based stress data.
* 38 pages,12 figures, 6 tables, 5 Appendix (full version) -- shorter version published in JMIR Public Health Surveill 2017;3(2):e35
Classifying Vietnamese Disease Outbreak Reports with Important Sentences and Rich Features
Nov 22, 2019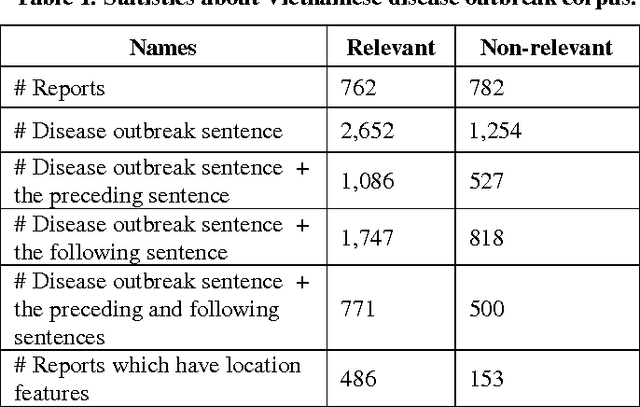
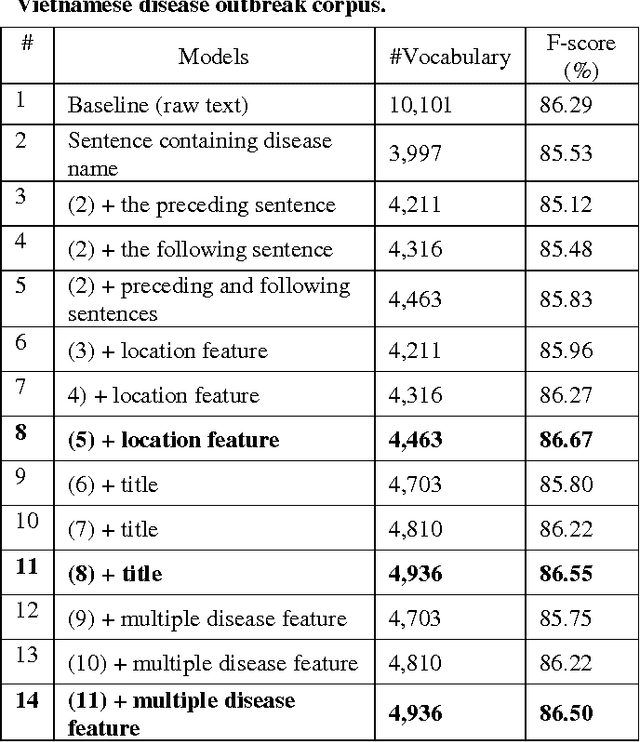
Text classification is an important field of research from mid 90s up to now. It has many applications, one of them is in Web-based biosurveillance systems which identify and summarize online disease outbreak reports. In this paper we focus on classifying Vietnamese disease outbreak reports. We investigate important properties of disease outbreak reports, e.g., sentences containing names of outbreak disease, locations. Evaluation on 10-time 10- fold cross-validation using the Support Vector Machine algorithm shows that using sentences containing disease outbreak names with its preceding/following sentences in combination with location features achieve the best F-score with 86.67% - an improvement of 0.38% in comparison to using all raw text. Our results suggest that using important sentences and rich feature can improve performance of Vietnamese disease outbreak text classification.
* 5 pages, 2 tables
Global Health Monitor: A Web-based System for Detecting and Mapping Infectious Diseases
Nov 21, 2019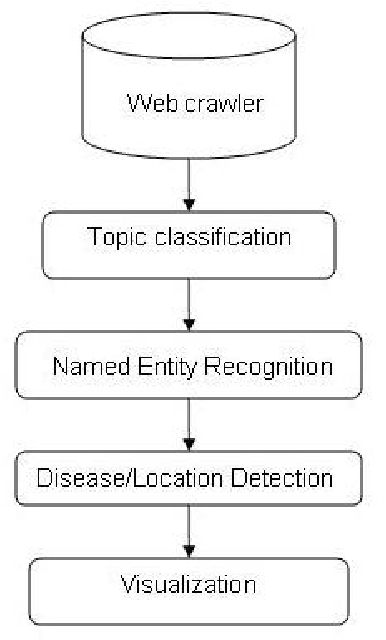
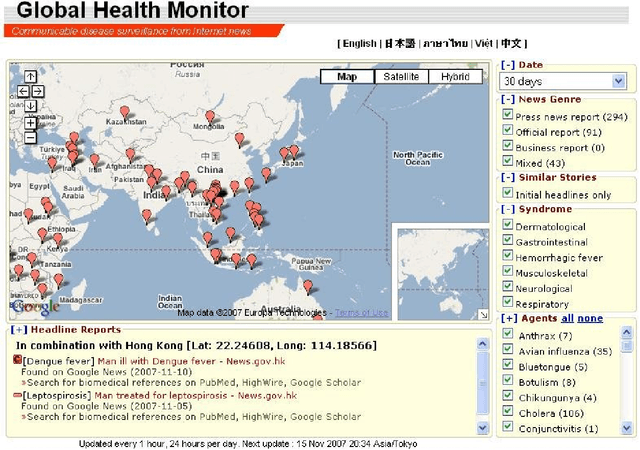
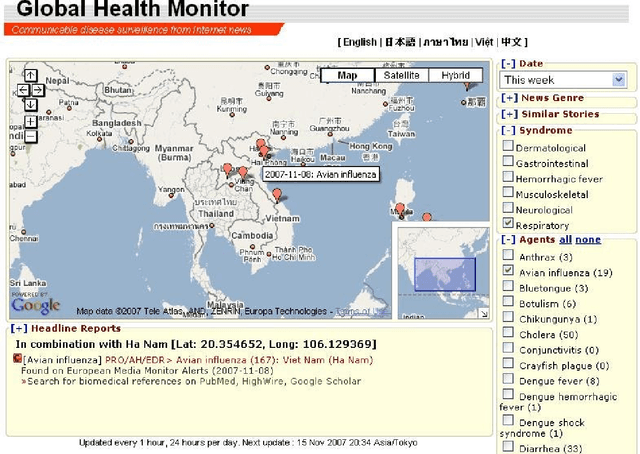
We present the Global Health Monitor, an online Web-based system for detecting and mapping infectious disease outbreaks that appear in news stories. The system analyzes English news stories from news feed providers, classifies them for topical relevance and plots them onto a Google map using geo-coding information, helping public health workers to monitor the spread of diseases in a geo-temporal context. The background knowledge for the system is contained in the BioCaster ontology (BCO) (Collier et al., 2007a) which includes both information on infectious diseases as well as geographical locations with their latitudes/longitudes. The system consists of four main stages: topic classification, named entity recognition (NER), disease/location detection and visualization. Evaluation of the system shows that it achieved high accuracy on a gold standard corpus. The system is now in practical use. Running on a clustercomputer, it monitors more than 1500 news feeds 24/7, updating the map every hour.
* 6 pages, 3 figures, Proc. of IJCNLP 2008
An Empirical Study of Sections in Classifying Disease Outbreak Reports
Nov 21, 2019
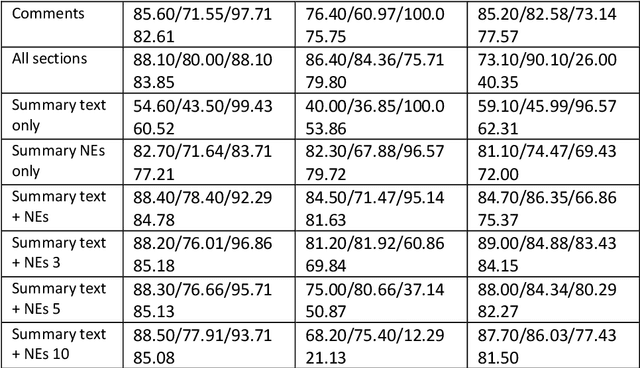
Identifying articles that relate to infectious diseases is a necessary step for any automatic bio-surveillance system that monitors news articles from the Internet. Unlike scientific articles which are available in a strongly structured form, news articles are usually loosely structured. In this chapter, we investigate the importance of each section and the effect of section weighting on performance of text classification. The experimental results show that (1) classification models using the headline and leading sentence achieve a high performance in terms of F-score compared to other parts of the article; (2) all section with bag-of-word representation (full text) achieves the highest recall; and (3) section weighting information can help to improve accuracy.
* 13 pages, 2 tables, book chapter in Web-Based Applications in Healthcare and Biomedicine. Annals of Information Systems, vol 7. Springer, Boston, MA, 2010
Using natural language processing to extract health-related causality from Twitter messages
Nov 15, 2019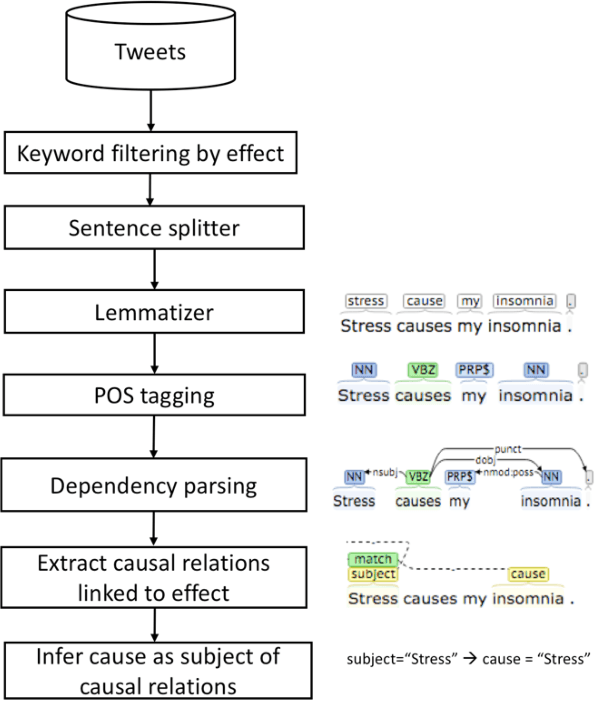
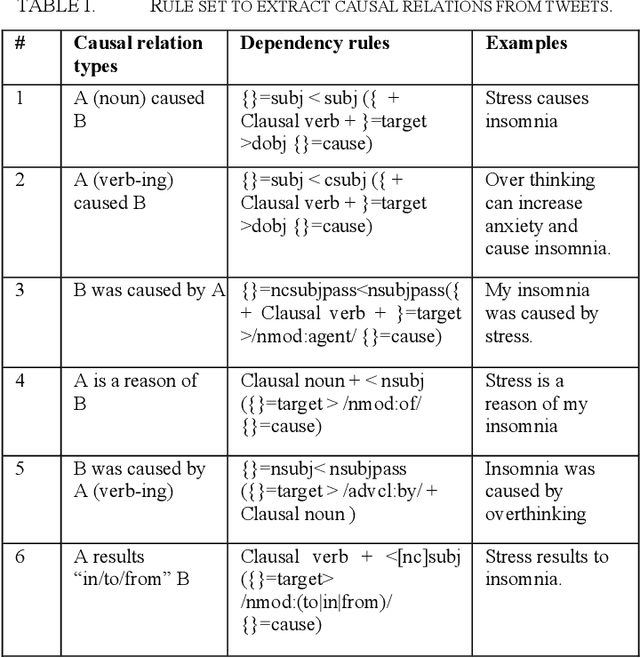
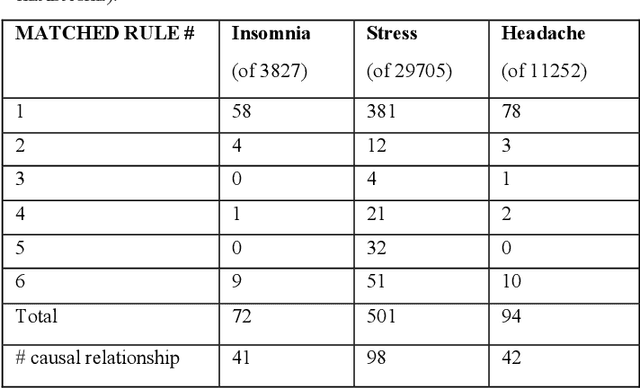
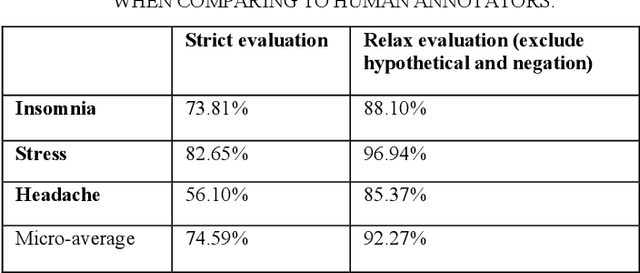
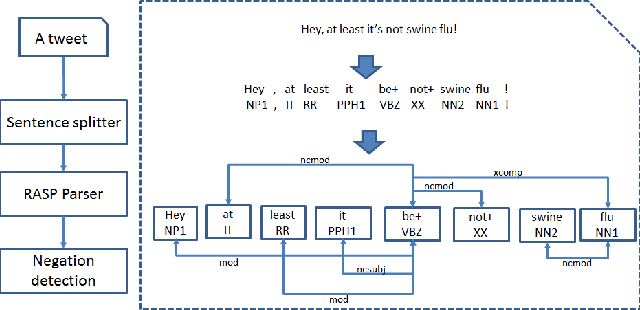
Twitter messages (tweets) contain various types of information, which include health-related information. Analysis of health-related tweets would help us understand health conditions and concerns encountered in our daily life. In this work, we evaluated an approach to extracting causal relations from tweets using natural language processing (NLP) techniques. We focused on three health-related topics: stress", "insomnia", and "headache". We proposed a set of lexico-syntactic patterns based on dependency parser outputs to extract causal information. A large dataset consisting of 24 million tweets were used. The results show that our approach achieved an average precision between 74.59% and 92.27%. Analysis of extracted relations revealed interesting findings about health-related in Twitter.
* 5 pages
Natural Language Processing in Biomedicine: A Unified System Architecture Overview
Jan 08, 2014
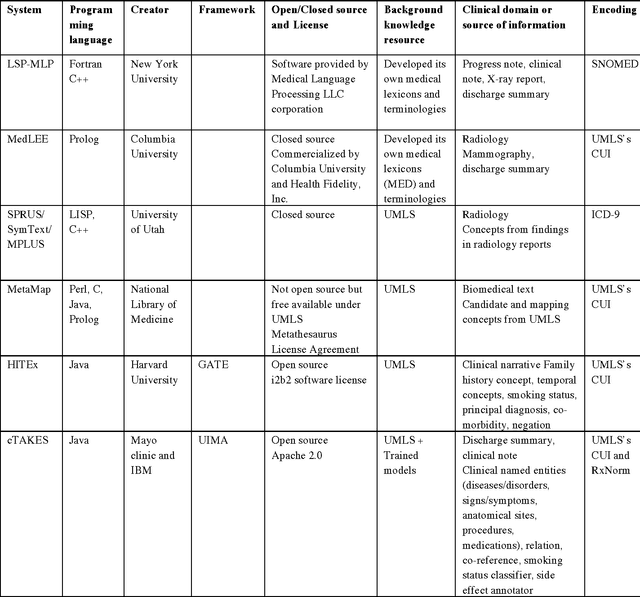
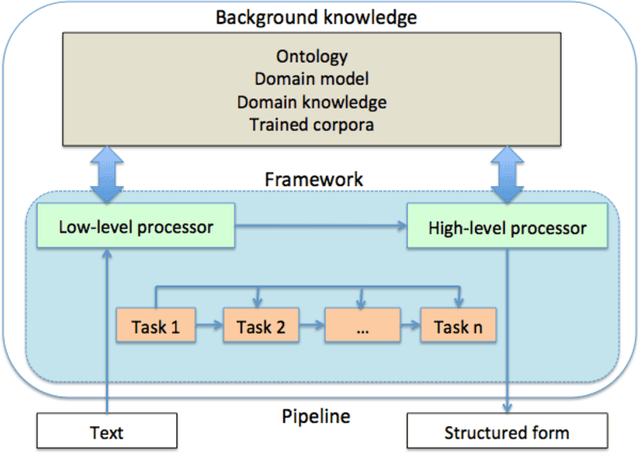
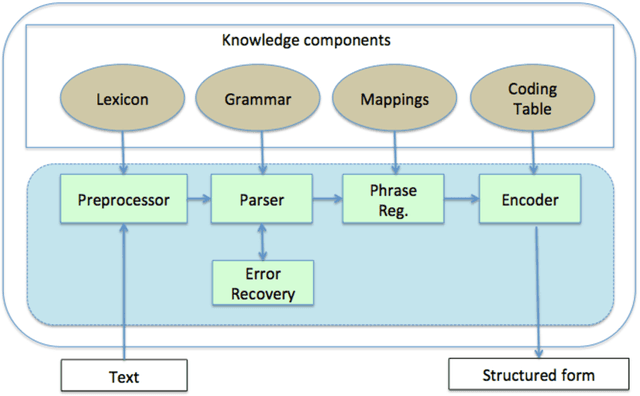
In modern electronic medical records (EMR) much of the clinically important data - signs and symptoms, symptom severity, disease status, etc. - are not provided in structured data fields, but rather are encoded in clinician generated narrative text. Natural language processing (NLP) provides a means of "unlocking" this important data source for applications in clinical decision support, quality assurance, and public health. This chapter provides an overview of representative NLP systems in biomedicine based on a unified architectural view. A general architecture in an NLP system consists of two main components: background knowledge that includes biomedical knowledge resources and a framework that integrates NLP tools to process text. Systems differ in both components, which we will review briefly. Additionally, challenges facing current research efforts in biomedical NLP include the paucity of large, publicly available annotated corpora, although initiatives that facilitate data sharing, system evaluation, and collaborative work between researchers in clinical NLP are starting to emerge.
Enhancing Twitter Data Analysis with Simple Semantic Filtering: Example in Tracking Influenza-Like Illnesses
Oct 02, 2012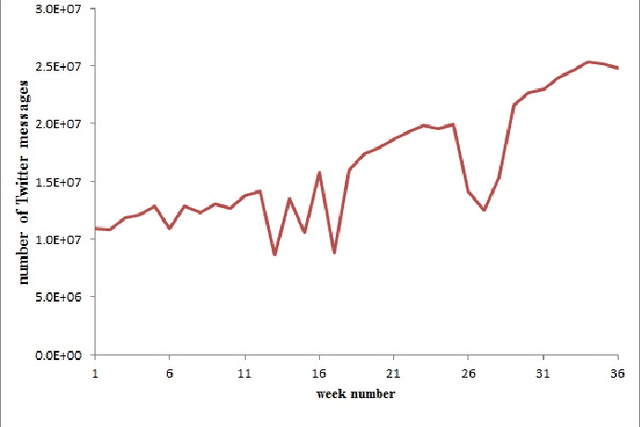
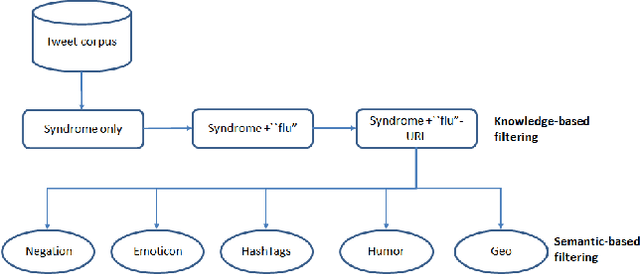
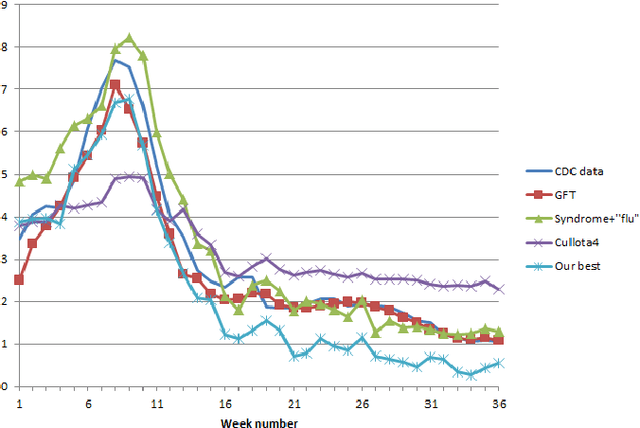
Systems that exploit publicly available user generated content such as Twitter messages have been successful in tracking seasonal influenza. We developed a novel filtering method for Influenza-Like-Illnesses (ILI)-related messages using 587 million messages from Twitter micro-blogs. We first filtered messages based on syndrome keywords from the BioCaster Ontology, an extant knowledge model of laymen's terms. We then filtered the messages according to semantic features such as negation, hashtags, emoticons, humor and geography. The data covered 36 weeks for the US 2009 influenza season from 30th August 2009 to 8th May 2010. Results showed that our system achieved the highest Pearson correlation coefficient of 98.46% (p-value<2.2e-16), an improvement of 3.98% over the previous state-of-the-art method. The results indicate that simple NLP-based enhancements to existing approaches to mine Twitter data can increase the value of this inexpensive resource.
Syndromic classification of Twitter messages
Oct 13, 2011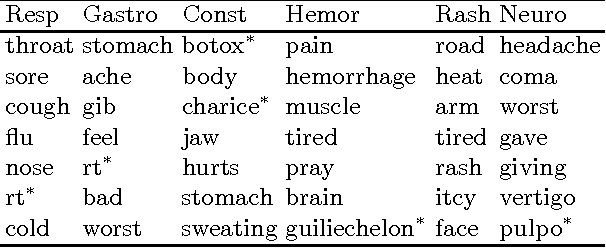
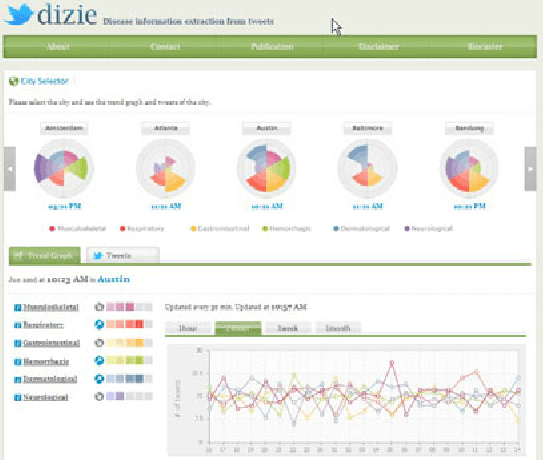
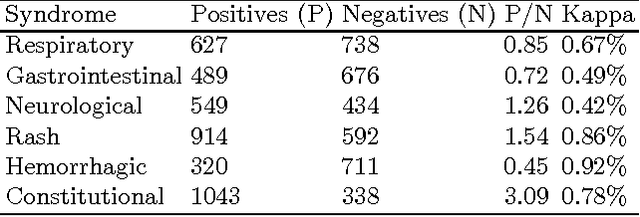
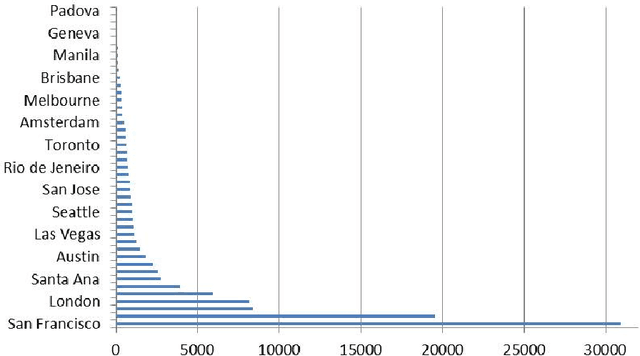
Recent studies have shown strong correlation between social networking data and national influenza rates. We expanded upon this success to develop an automated text mining system that classifies Twitter messages in real time into six syndromic categories based on key terms from a public health ontology. 10-fold cross validation tests were used to compare Naive Bayes (NB) and Support Vector Machine (SVM) models on a corpus of 7431 Twitter messages. SVM performed better than NB on 4 out of 6 syndromes. The best performing classifiers showed moderately strong F1 scores: respiratory = 86.2 (NB); gastrointestinal = 85.4 (SVM polynomial kernel degree 2); neurological = 88.6 (SVM polynomial kernel degree 1); rash = 86.0 (SVM polynomial kernel degree 1); constitutional = 89.3 (SVM polynomial kernel degree 1); hemorrhagic = 89.9 (NB). The resulting classifiers were deployed together with an EARS C2 aberration detection algorithm in an experimental online system.
An analysis of Twitter messages in the 2011 Tohoku Earthquake
Sep 08, 2011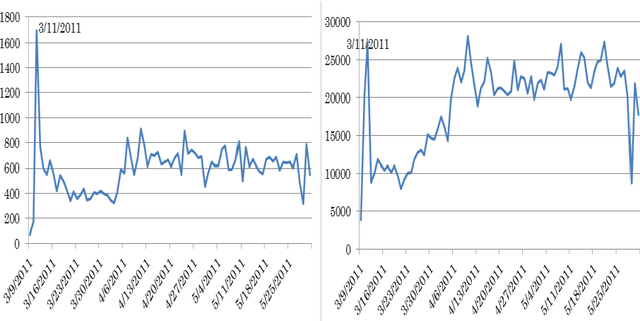

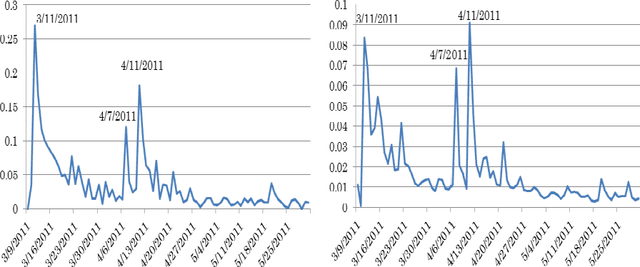

Social media such as Facebook and Twitter have proven to be a useful resource to understand public opinion towards real world events. In this paper, we investigate over 1.5 million Twitter messages (tweets) for the period 9th March 2011 to 31st May 2011 in order to track awareness and anxiety levels in the Tokyo metropolitan district to the 2011 Tohoku Earthquake and subsequent tsunami and nuclear emergencies. These three events were tracked using both English and Japanese tweets. Preliminary results indicated: 1) close correspondence between Twitter data and earthquake events, 2) strong correlation between English and Japanese tweets on the same events, 3) tweets in the native language play an important roles in early warning, 4) tweets showed how quickly Japanese people's anxiety returned to normal levels after the earthquake event. Several distinctions between English and Japanese tweets on earthquake events are also discussed. The results suggest that Twitter data can be used as a useful resource for tracking the public mood of populations affected by natural disasters as well as an early warning system.
* 9 pages, 4 figures, eHealth 2011 conference, Malaga (Spain) (accepted)