 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Processing in Biomedicine: A Unified System Architecture Overview
Paper and Code
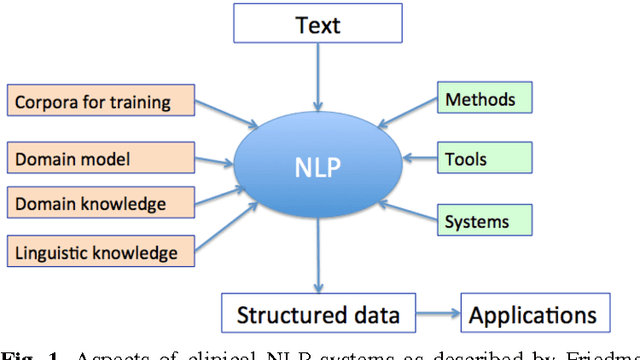
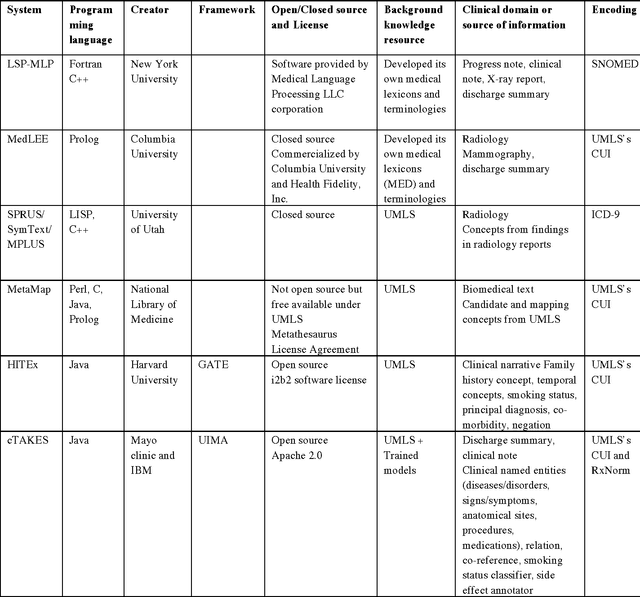
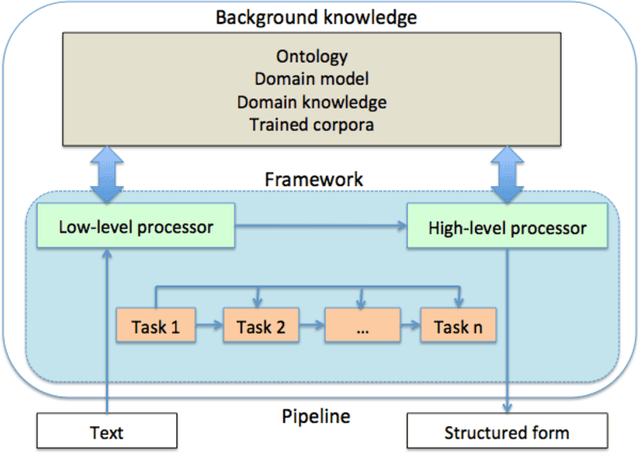
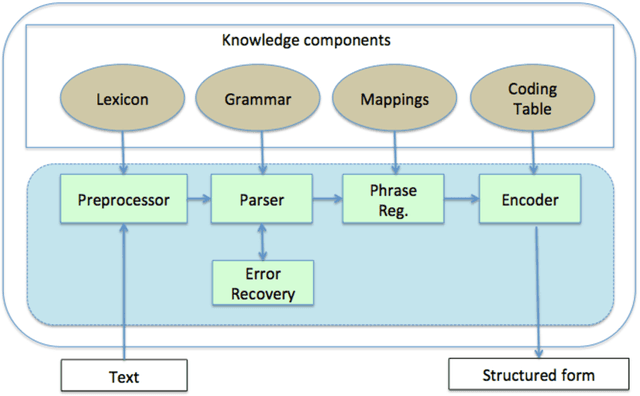
In modern electronic medical records (EMR) much of the clinically important data - signs and symptoms, symptom severity, disease status, etc. - are not provided in structured data fields, but rather are encoded in clinician generated narrative text. Natural language processing (NLP) provides a means of "unlocking" this important data source for applications in clinical decision support, quality assurance, and public health. This chapter provides an overview of representative NLP systems in biomedicine based on a unified architectural view. A general architecture in an NLP system consists of two main components: background knowledge that includes biomedical knowledge resources and a framework that integrates NLP tools to process text. Systems differ in both components, which we will review briefly. Additionally, challenges facing current research efforts in biomedical NLP include the paucity of large, publicly available annotated corpora, although initiatives that facilitate data sharing, system evaluation, and collaborative work between researchers in clinical NLP are starting to emerge.