 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Twitter Data Analysis with Simple Semantic Filtering: Example in Tracking Influenza-Like Illnesses
Paper and Code
Oct 02, 2012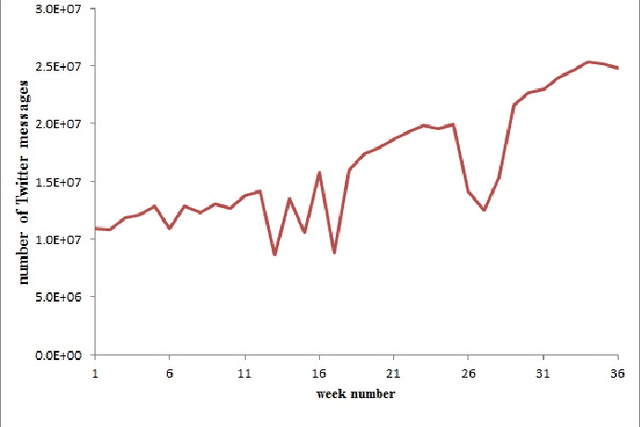
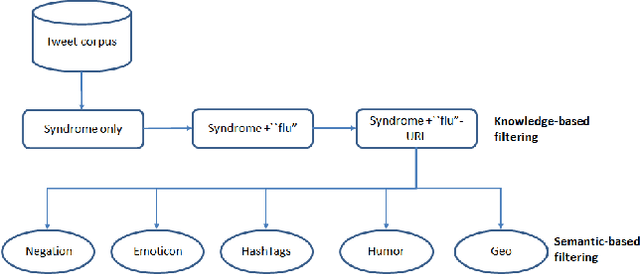
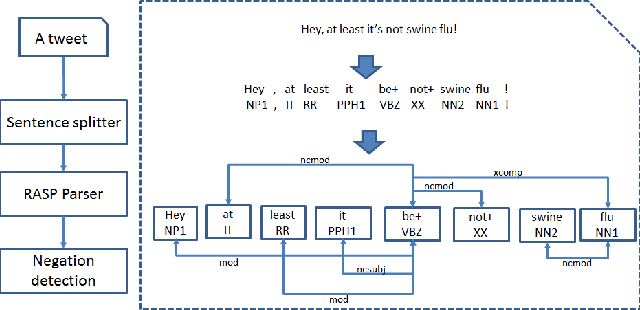
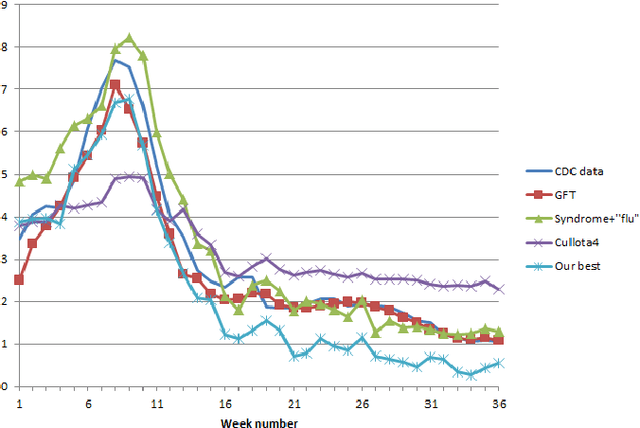
Systems that exploit publicly available user generated content such as Twitter messages have been successful in tracking seasonal influenza. We developed a novel filtering method for Influenza-Like-Illnesses (ILI)-related messages using 587 million messages from Twitter micro-blogs. We first filtered messages based on syndrome keywords from the BioCaster Ontology, an extant knowledge model of laymen's terms. We then filtered the messages according to semantic features such as negation, hashtags, emoticons, humor and geography. The data covered 36 weeks for the US 2009 influenza season from 30th August 2009 to 8th May 2010. Results showed that our system achieved the highest Pearson correlation coefficient of 98.46% (p-value<2.2e-16), an improvement of 3.98% over the previous state-of-the-art method. The results indicate that simple NLP-based enhancements to existing approaches to mine Twitter data can increase the value of this inexpensive resource.