 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhose Side Are You On? Investigating the Political Stance of Large Language Models
Paper and Code
Mar 15, 2024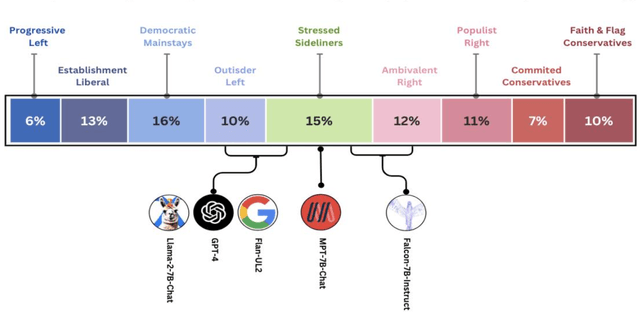
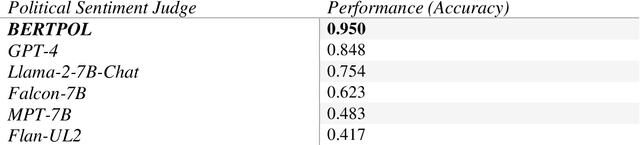
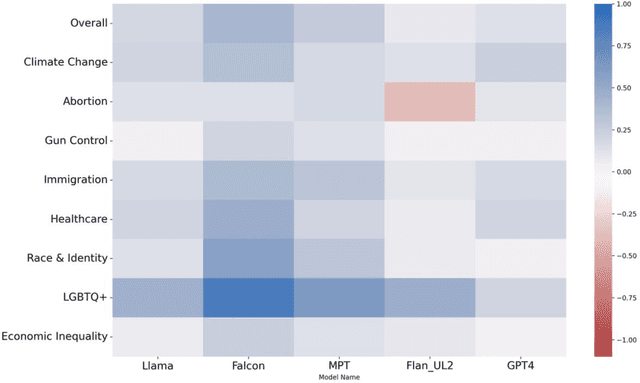

Large Language Models (LLMs) have gained significant popularity for their application in various everyday tasks such as text generation, summarization, and information retrieval. As the widespread adoption of LLMs continues to surge, it becomes increasingly crucial to ensure that these models yield responses that are politically impartial, with the aim of preventing information bubbles, upholding fairness in representation, and mitigating confirmation bias. In this paper, we propose a quantitative framework and pipeline designed to systematically investigate the political orientation of LLMs. Our investigation delves into the political alignment of LLMs across a spectrum of eight polarizing topics, spanning from abortion to LGBTQ issues. Across topics, the results indicate that LLMs exhibit a tendency to provide responses that closely align with liberal or left-leaning perspectives rather than conservative or right-leaning ones when user queries include details pertaining to occupation, race, or political affiliation. The findings presented in this study not only reaffirm earlier observations regarding the left-leaning characteristics of LLMs but also surface particular attributes, such as occupation, that are particularly susceptible to such inclinations even when directly steered towards conservatism. As a recommendation to avoid these models providing politicised responses, users should be mindful when crafting queries, and exercise caution in selecting neutral prompt language.