 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOperationalizing Assurance Cases for Data Scientists: A Showcase of Concepts and Tooling in the Context of Test Data Quality for Machine Learning
Dec 08, 2023Assurance Cases (ACs) are an established approach in safety engineering to argue quality claims in a structured way. In the context of quality assurance for Machine Learning (ML)-based software components, ACs are also being discussed and appear promising. Tools for operationalizing ACs do exist, yet mainly focus on supporting safety engineers on the system level. However, assuring the quality of an ML component within the system is commonly the responsibility of data scientists, who are usually less familiar with these tools. To address this gap, we propose a framework to support the operationalization of ACs for ML components based on technologies that data scientists use on a daily basis: Python and Jupyter Notebook. Our aim is to make the process of creating ML-related evidence in ACs more effective. Results from the application of the framework, documented through notebooks, can be integrated into existing AC tools. We illustrate the application of the framework on an example excerpt concerned with the quality of the test data.
Uncertainty Wrapper in the medical domain: Establishing transparent uncertainty quantification for opaque machine learning models in practice
Nov 09, 2023



When systems use data-based models that are based on machine learning (ML), errors in their results cannot be ruled out. This is particularly critical if it remains unclear to the user how these models arrived at their decisions and if errors can have safety-relevant consequences, as is often the case in the medical field. In such cases, the use of dependable methods to quantify the uncertainty remaining in a result allows the user to make an informed decision about further usage and draw possible conclusions based on a given result. This paper demonstrates the applicability and practical utility of the Uncertainty Wrapper using flow cytometry as an application from the medical field that can benefit from the use of ML models in conjunction with dependable and transparent uncertainty quantification.
Badgers: generating data quality deficits with Python
Jul 10, 2023


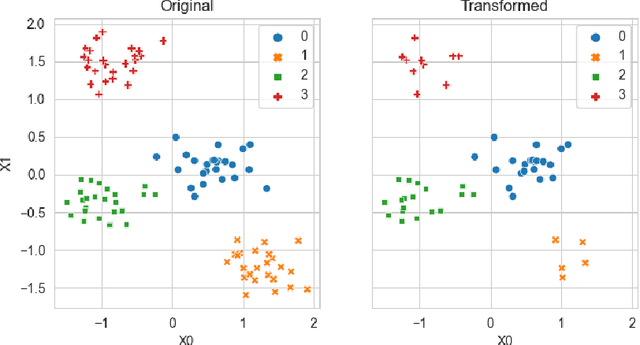
Generating context specific data quality deficits is necessary to experimentally assess data quality of data-driven (artificial intelligence (AI) or machine learning (ML)) applications. In this paper we present badgers, an extensible open-source Python library to generate data quality deficits (outliers, imbalanced data, drift, etc.) for different modalities (tabular data, time-series, text, etc.). The documentation is accessible at https://fraunhofer-iese.github.io/badgers/ and the source code at https://github.com/Fraunhofer-IESE/badgers
Timeseries-aware Uncertainty Wrappers for Uncertainty Quantification of Information-Fusion-Enhanced AI Models based on Machine Learning
May 24, 2023
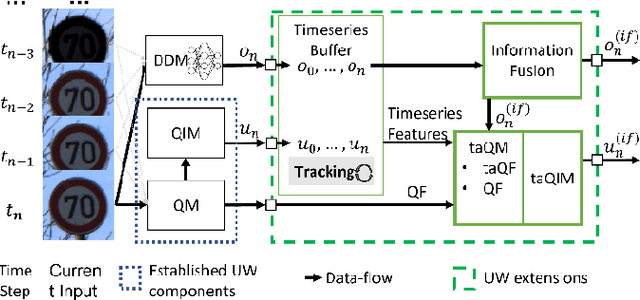

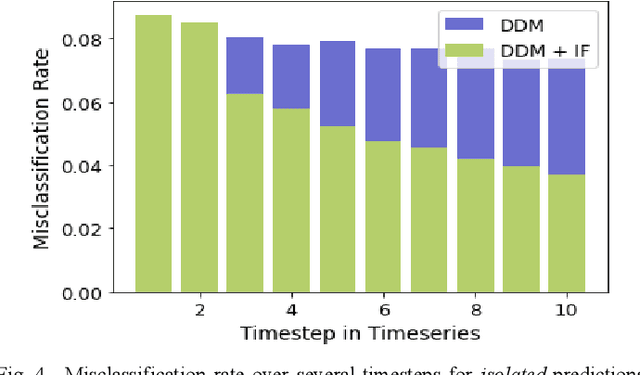
As the use of Artificial Intelligence (AI) components in cyber-physical systems is becoming more common, the need for reliable system architectures arises. While data-driven models excel at perception tasks, model outcomes are usually not dependable enough for safety-critical applications. In this work,we present a timeseries-aware uncertainty wrapper for dependable uncertainty estimates on timeseries data. The uncertainty wrapper is applied in combination with information fusion over successive model predictions in time. The application of the uncertainty wrapper is demonstrated with a traffic sign recognition use case. We show that it is possible to increase model accuracy through information fusion and additionally increase the quality of uncertainty estimates through timeseries-aware input quality features.
Architectural patterns for handling runtime uncertainty of data-driven models in safety-critical perception
Jun 14, 2022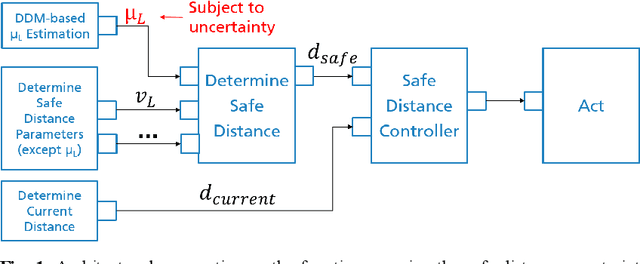
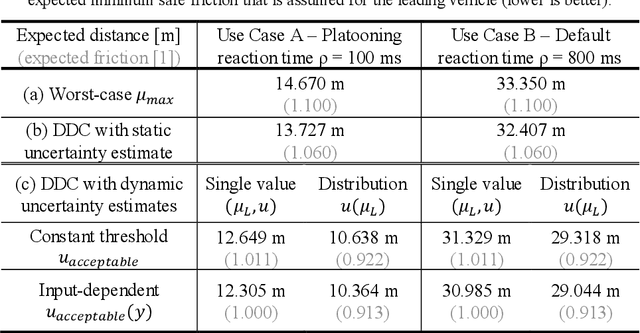
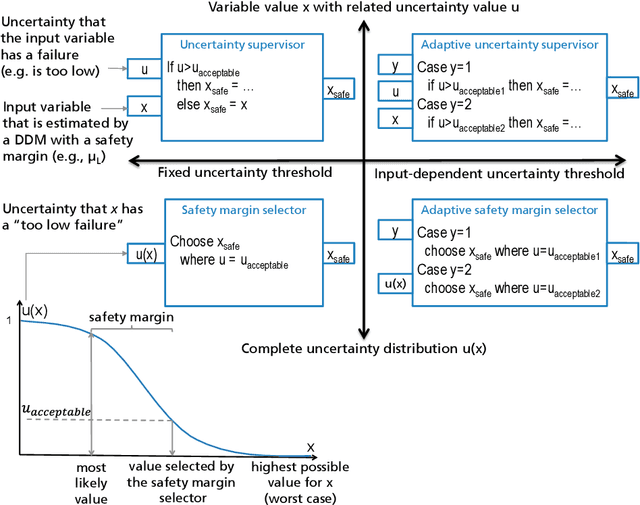
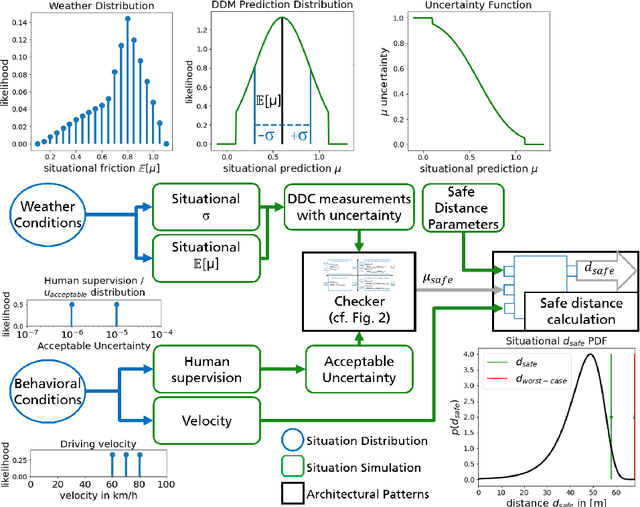
Data-driven models (DDM) based on machine learning and other AI techniques play an important role in the perception of increasingly autonomous systems. Due to the merely implicit definition of their behavior mainly based on the data used for training, DDM outputs are subject to uncertainty. This poses a challenge with respect to the realization of safety-critical perception tasks by means of DDMs. A promising approach to tackling this challenge is to estimate the uncertainty in the current situation during operation and adapt the system behavior accordingly. In previous work, we focused on runtime estimation of uncertainty and discussed approaches for handling uncertainty estimations. In this paper, we present additional architectural patterns for handling uncertainty. Furthermore, we evaluate the four patterns qualitatively and quantitatively with respect to safety and performance gains. For the quantitative evaluation, we consider a distance controller for vehicle platooning where performance gains are measured by considering how much the distance can be reduced in different operational situations. We conclude that the consideration of context information of the driving situation makes it possible to accept more or less uncertainty depending on the inherent risk of the situation, which results in performance gains.
Integrating Testing and Operation-related Quantitative Evidences in Assurance Cases to Argue Safety of Data-Driven AI/ML Components
Feb 10, 2022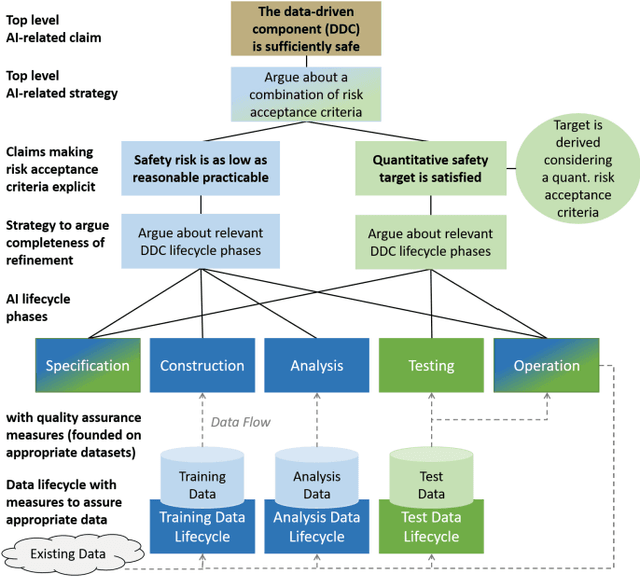
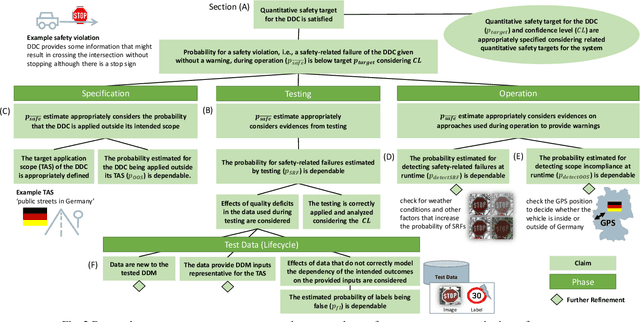
In the future, AI will increasingly find its way into systems that can potentially cause physical harm to humans. For such safety-critical systems, it must be demonstrated that their residual risk does not exceed what is acceptable. This includes, in particular, the AI components that are part of such systems' safety-related functions. Assurance cases are an intensively discussed option today for specifying a sound and comprehensive safety argument to demonstrate a system's safety. In previous work, it has been suggested to argue safety for AI components by structuring assurance cases based on two complementary risk acceptance criteria. One of these criteria is used to derive quantitative targets regarding the AI. The argumentation structures commonly proposed to show the achievement of such quantitative targets, however, focus on failure rates from statistical testing. Further important aspects are only considered in a qualitative manner -- if at all. In contrast, this paper proposes a more holistic argumentation structure for having achieved the target, namely a structure that integrates test results with runtime aspects and the impact of scope compliance and test data quality in a quantitative manner. We elaborate different argumentation options, present the underlying mathematical considerations, and discuss resulting implications for their practical application. Using the proposed argumentation structure might not only increase the integrity of assurance cases but may also allow claims on quantitative targets that would not be justifiable otherwise.
A Study on Mitigating Hard Boundaries of Decision-Tree-based Uncertainty Estimates for AI Models
Jan 10, 2022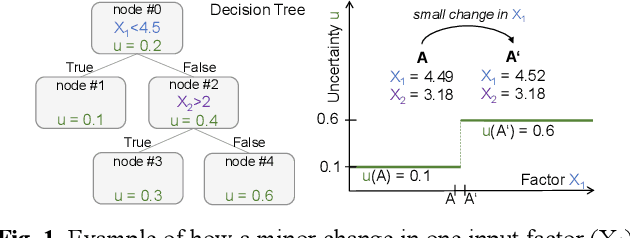



Outcomes of data-driven AI models cannot be assumed to be always correct. To estimate the uncertainty in these outcomes, the uncertainty wrapper framework has been proposed, which considers uncertainties related to model fit, input quality, and scope compliance. Uncertainty wrappers use a decision tree approach to cluster input quality related uncertainties, assigning inputs strictly to distinct uncertainty clusters. Hence, a slight variation in only one feature may lead to a cluster assignment with a significantly different uncertainty. Our objective is to replace this with an approach that mitigates hard decision boundaries of these assignments while preserving interpretability, runtime complexity, and prediction performance. Five approaches were selected as candidates and integrated into the uncertainty wrapper framework. For the evaluation based on the Brier score, datasets for a pedestrian detection use case were generated using the CARLA simulator and YOLOv3. All integrated approaches achieved a softening, i.e., smoothing, of uncertainty estimation. Yet, compared to decision trees, they are not so easy to interpret and have higher runtime complexity. Moreover, some components of the Brier score impaired while others improved. Most promising regarding the Brier score were random forests. In conclusion, softening hard decision tree boundaries appears to be a trade-off decision.
Towards a Common Testing Terminology for Software Engineering and Artificial Intelligence Experts
Sep 06, 2021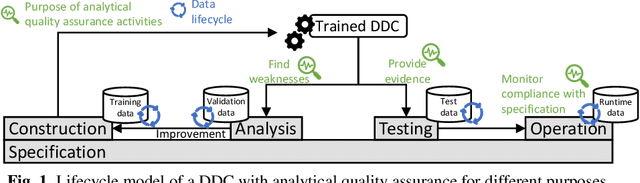
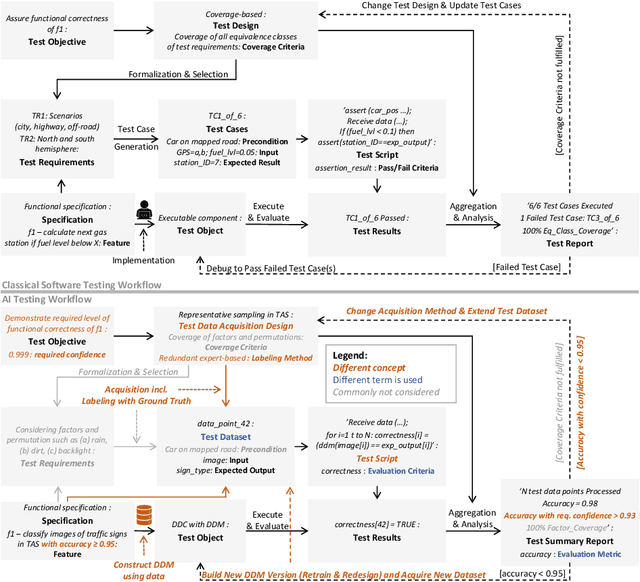
Analytical quality assurance, especially testing, is an integral part of software-intensive system development. With the increased usage of Artificial Intelligence (AI) and Machine Learning (ML) as part of such systems, this becomes more difficult as well-understood software testing approaches cannot be applied directly to the AI-enabled parts of the system. The required adaptation of classical testing approaches and development of new concepts for AI would benefit from a deeper understanding and exchange between AI and software engineering experts. A major obstacle on this way, we see in the different terminologies used in the two communities. As we consider a mutual understanding of the testing terminology as a key, this paper contributes a mapping between the most important concepts from classical software testing and AI testing. In the mapping, we highlight differences in relevance and naming of the mapped concepts.
Towards Identifying and Managing Sources of Uncertainty in AI and Machine Learning Models - An Overview
Nov 28, 2018

Quantifying and managing uncertainties that occur when data-driven models such as those provided by AI and machine learning methods are applied is crucial. This whitepaper provides a brief motivation and first overview of the state of the art in identifying and quantifying sources of uncertainty for data-driven components as well as means for analyzing their impact.