 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepQuali: Initial results of a study on the use of large language models for assessing the quality of user stories
Feb 09, 2026Generative artificial intelligence (GAI), specifically large language models (LLMs), are increasingly used in software engineering, mainly for coding tasks. However, requirements engineering - particularly requirements validation - has seen limited application of GAI. The current focus of using GAI for requirements is on eliciting, transforming, and classifying requirements, not on quality assessment. We propose and evaluate the LLM-based (GPT-4o) approach "DeepQuali", for assessing and improving requirements quality in agile software development. We applied it to projects in two small companies, where we compared LLM-based quality assessments with expert judgments. Experts also participated in walkthroughs of the solution, provided feedback, and rated their acceptance of the approach. Experts largely agreed with the LLM's quality assessments, especially regarding overall ratings and explanations. However, they did not always agree with the other experts on detailed ratings, suggesting that expertise and experience may influence judgments. Experts recognized the usefulness of the approach but criticized the lack of integration into their workflow. LLMs show potential in supporting software engineers with the quality assessment and improvement of requirements. The explicit use of quality models and explanatory feedback increases acceptance.
Deep Learning-based Codes for Wiretap Fading Channels
Sep 13, 2024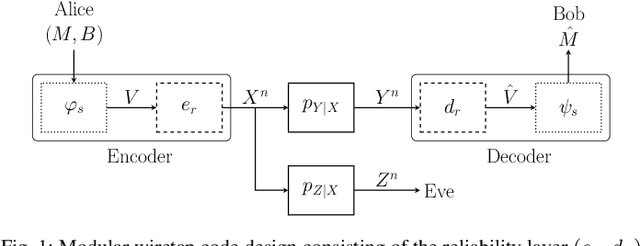



The wiretap channel is a well-studied problem in the physical layer security (PLS) literature. Although it is proven that the decoding error probability and information leakage can be made arbitrarily small in the asymptotic regime, further research on finite-blocklength codes is required on the path towards practical, secure communications systems. This work provides the first experimental characterization of a deep learning-based, finite-blocklength code construction for multi-tap fading wiretap channels without channel state information (CSI). In addition to the evaluation of the average probability of error and information leakage, we illustrate the influence of (i) the number of fading taps, (ii) differing variances of the fading coefficients and (iii) the seed selection for the hash function-based security layer.
Operationalizing Assurance Cases for Data Scientists: A Showcase of Concepts and Tooling in the Context of Test Data Quality for Machine Learning
Dec 08, 2023Assurance Cases (ACs) are an established approach in safety engineering to argue quality claims in a structured way. In the context of quality assurance for Machine Learning (ML)-based software components, ACs are also being discussed and appear promising. Tools for operationalizing ACs do exist, yet mainly focus on supporting safety engineers on the system level. However, assuring the quality of an ML component within the system is commonly the responsibility of data scientists, who are usually less familiar with these tools. To address this gap, we propose a framework to support the operationalization of ACs for ML components based on technologies that data scientists use on a daily basis: Python and Jupyter Notebook. Our aim is to make the process of creating ML-related evidence in ACs more effective. Results from the application of the framework, documented through notebooks, can be integrated into existing AC tools. We illustrate the application of the framework on an example excerpt concerned with the quality of the test data.
Badgers: generating data quality deficits with Python
Jul 10, 2023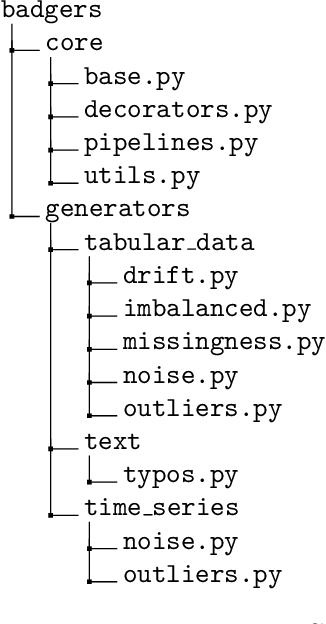


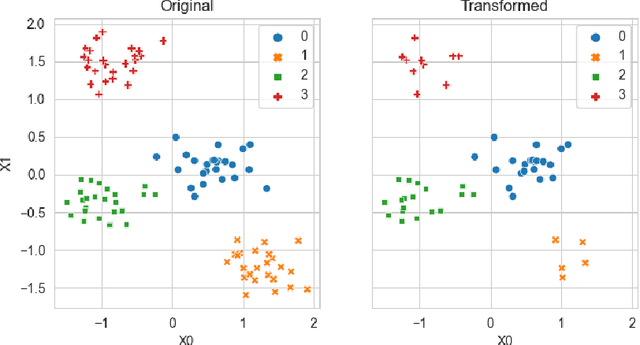
Generating context specific data quality deficits is necessary to experimentally assess data quality of data-driven (artificial intelligence (AI) or machine learning (ML)) applications. In this paper we present badgers, an extensible open-source Python library to generate data quality deficits (outliers, imbalanced data, drift, etc.) for different modalities (tabular data, time-series, text, etc.). The documentation is accessible at https://fraunhofer-iese.github.io/badgers/ and the source code at https://github.com/Fraunhofer-IESE/badgers