 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepQuali: Initial results of a study on the use of large language models for assessing the quality of user stories
Feb 09, 2026Generative artificial intelligence (GAI), specifically large language models (LLMs), are increasingly used in software engineering, mainly for coding tasks. However, requirements engineering - particularly requirements validation - has seen limited application of GAI. The current focus of using GAI for requirements is on eliciting, transforming, and classifying requirements, not on quality assessment. We propose and evaluate the LLM-based (GPT-4o) approach "DeepQuali", for assessing and improving requirements quality in agile software development. We applied it to projects in two small companies, where we compared LLM-based quality assessments with expert judgments. Experts also participated in walkthroughs of the solution, provided feedback, and rated their acceptance of the approach. Experts largely agreed with the LLM's quality assessments, especially regarding overall ratings and explanations. However, they did not always agree with the other experts on detailed ratings, suggesting that expertise and experience may influence judgments. Experts recognized the usefulness of the approach but criticized the lack of integration into their workflow. LLMs show potential in supporting software engineers with the quality assessment and improvement of requirements. The explicit use of quality models and explanatory feedback increases acceptance.
Evaluation of large language models for assessing code maintainability
Jan 23, 2024Increased availability of open-source software repositories and recent advances in code analysis using large language models (LLMs) has triggered a wave of new work to automate software engineering tasks that were previously very difficult to automate. In this paper, we investigate a recent line of work that hypothesises that comparing the probability of code generated by LLMs with the probability the current code would have had can indicate potential quality problems. We investigate the association between the cross-entropy of code generated by ten different models (based on GPT2 and Llama2) and the following quality aspects: readability, understandability, complexity, modularisation, and overall maintainability assessed by experts and available in an benchmark dataset. Our results show that, controlling for the number of logical lines of codes (LLOC), cross-entropy computed by LLMs is indeed a predictor of maintainability on a class level (the higher the cross-entropy the lower the maintainability). However, this relation is reversed when one does not control for LLOC (e.g., comparing small classes with longer ones). Furthermore, while the complexity of LLMs affects the range of cross-entropy (smaller models tend to have a wider range of cross-entropy), this plays a significant role in predicting maintainability aspects. Our study limits itself on ten different pretrained models (based on GPT2 and Llama2) and on maintainability aspects collected by Schnappinger et al. When controlling for logical lines of code (LLOC), cross-entropy is a predictor of maintainability. However, while related work has shown the potential usefulness of cross-entropy at the level of tokens or short sequences, at the class level this criterion alone may prove insufficient to predict maintainability and further research is needed to make best use of this information in practice.
Badgers: generating data quality deficits with Python
Jul 10, 2023


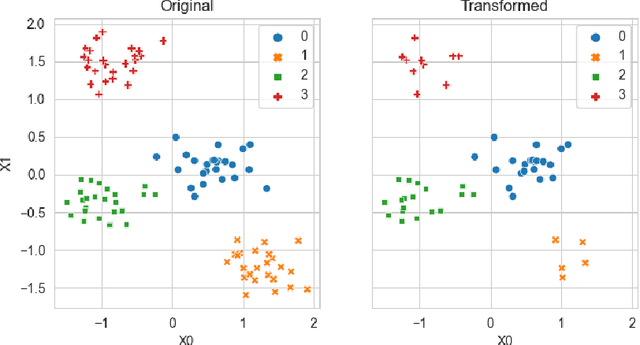
Generating context specific data quality deficits is necessary to experimentally assess data quality of data-driven (artificial intelligence (AI) or machine learning (ML)) applications. In this paper we present badgers, an extensible open-source Python library to generate data quality deficits (outliers, imbalanced data, drift, etc.) for different modalities (tabular data, time-series, text, etc.). The documentation is accessible at https://fraunhofer-iese.github.io/badgers/ and the source code at https://github.com/Fraunhofer-IESE/badgers
Building AI Innovation Labs together with Companies
Mar 16, 2022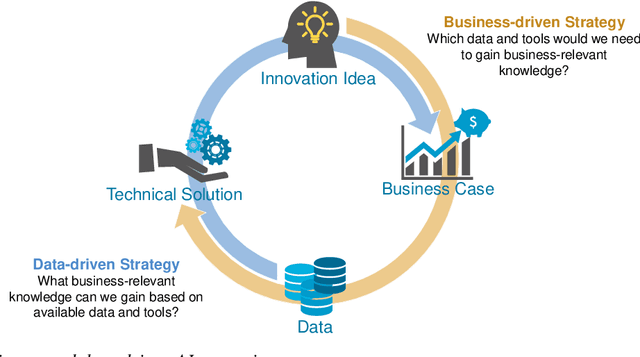
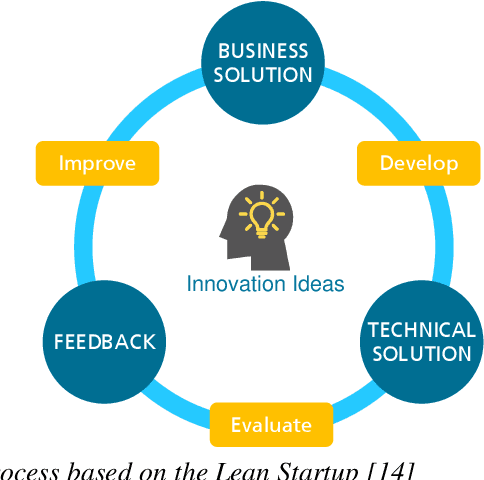
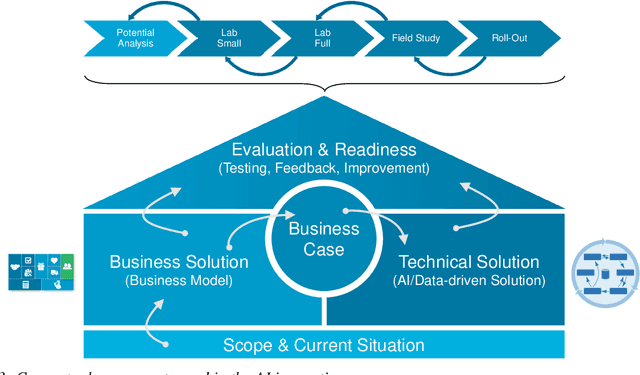
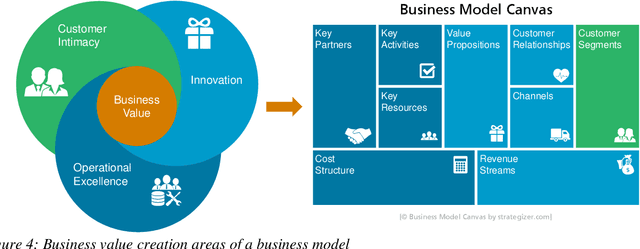
In the future, most companies will be confronted with the topic of Artificial Intelligence (AI) and will have to decide on their strategy in this regards. Currently, a lot of companies are thinking about whether and how AI and the usage of data will impact their business model and what potential use cases could look like. One of the biggest challenges lies in coming up with innovative solution ideas with a clear business value. This requires business competencies on the one hand and technical competencies in AI and data analytics on the other hand. In this article, we present the concept of AI innovation labs and demonstrate a comprehensive framework, from coming up with the right ideas to incrementally implementing and evaluating them regarding their business value and their feasibility based on a company's capabilities. The concept is the result of nine years of working on data-driven innovations with companies from various domains. Furthermore, we share some lessons learned from its practical applications. Even though a lot of technical publications can be found in the literature regarding the development of AI models and many consultancy companies provide corresponding services for building AI innovations, we found very few publications sharing details about what an end-to-end framework could look like.
Software Engineering for AI-Based Systems: A Survey
May 05, 2021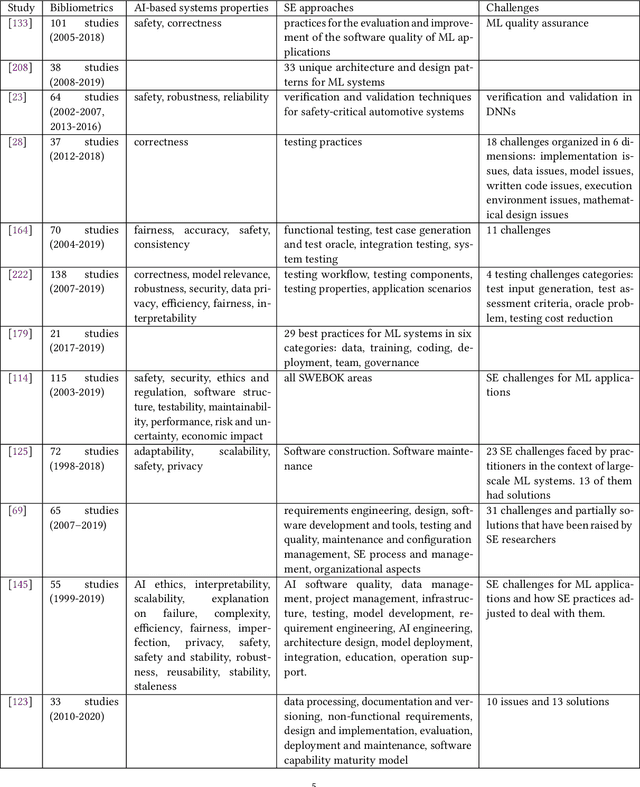
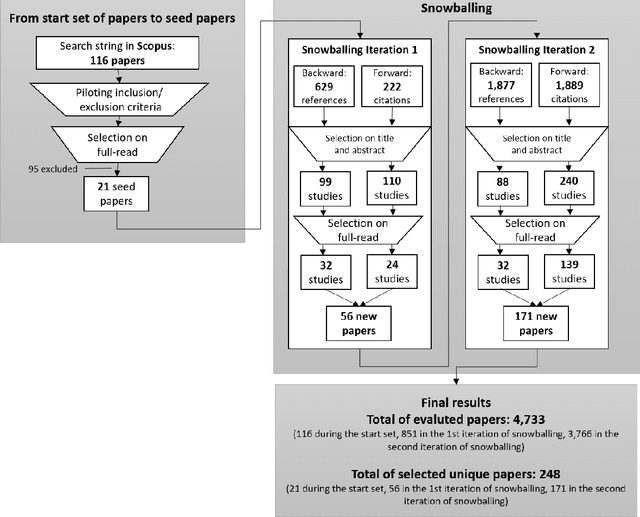

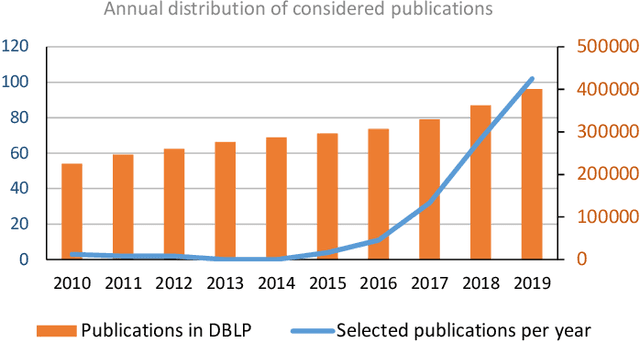
AI-based systems are software systems with functionalities enabled by at least one AI component (e.g., for image- and speech-recognition, and autonomous driving). AI-based systems are becoming pervasive in society due to advances in AI. However, there is limited synthesized knowledge on Software Engineering (SE) approaches for building, operating, and maintaining AI-based systems. To collect and analyze state-of-the-art knowledge about SE for AI-based systems, we conducted a systematic mapping study. We considered 248 studies published between January 2010 and March 2020. SE for AI-based systems is an emerging research area, where more than 2/3 of the studies have been published since 2018. The most studied properties of AI-based systems are dependability and safety. We identified multiple SE approaches for AI-based systems, which we classified according to the SWEBOK areas. Studies related to software testing and software quality are very prevalent, while areas like software maintenance seem neglected. Data-related issues are the most recurrent challenges. Our results are valuable for: researchers, to quickly understand the state of the art and learn which topics need more research; practitioners, to learn about the approaches and challenges that SE entails for AI-based systems; and, educators, to bridge the gap among SE and AI in their curricula.
Research Directions for Developing and Operating Artificial Intelligence Models in Trustworthy Autonomous Systems
Mar 11, 2020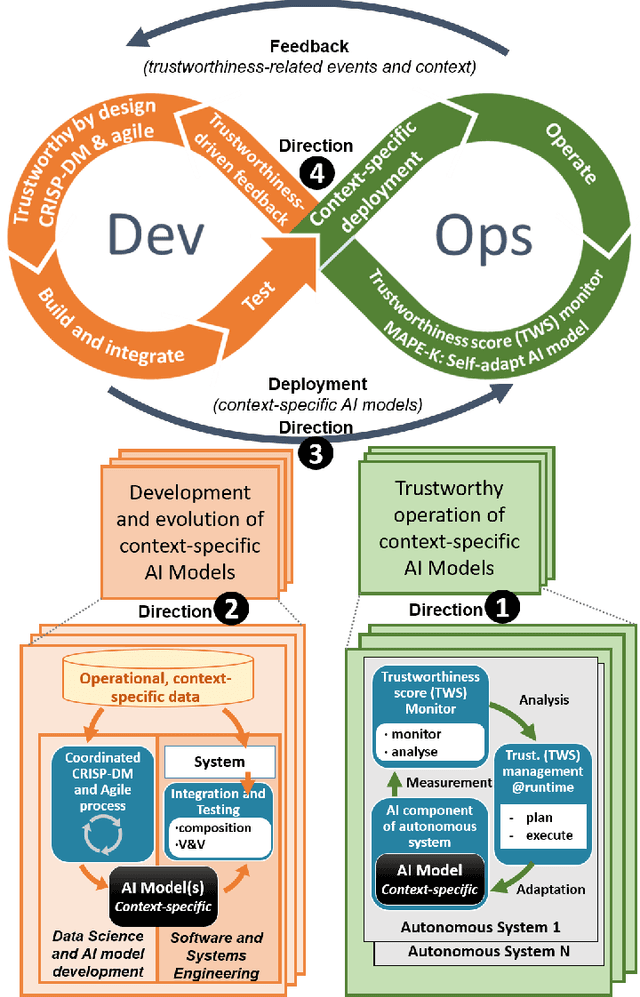
Context: Autonomous Systems (ASs) are becoming increasingly pervasive in today's society. One reason lies in the emergence of sophisticated Artificial Intelligence (AI) solutions that boost the ability of ASs to self-adapt in increasingly complex and dynamic environments. Companies dealing with AI models in ASs face several problems, such as users' lack of trust in adverse or unknown conditions, and gaps between systems engineering and AI model development and evolution in a continuously changing operational environment. Objective: This vision paper aims to close the gap between the development and operation of trustworthy AI-based ASs by defining a process that coordinates both activities. Method: We synthesize the main challenges of AI-based ASs in industrial settings. To overcome such challenges, we propose a novel, holistic DevOps approach and reflect on the research efforts required to put it into practice. Results: The approach sets up five critical research directions: (a) a trustworthiness score to monitor operational AI-based ASs and identify self-adaptation needs in critical situations; (b) an integrated agile process for the development and continuous evolution of AI models; (c) an infrastructure for gathering key feedback required to address the trustworthiness of AI models at operation time; (d) continuous and seamless deployment of different context-specific instances of AI models in a distributed setting of ASs; and (e) a holistic and effective DevOps-based lifecycle for AI-based ASs. Conclusions: An approach supporting the continuous delivery of evolving AI models and their operation in ASs under adverse conditions would support companies in increasing users' trust in their products.