 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Software Engineering: A Vision and Roadmap
May 04, 2026Software engineering increasingly involves making high-stakes decisions under uncertainty, using signals from code, field data, and socio-technical processes. Recent AI-driven support (e.g., anomaly detection, predictive analytics, AIOps, as well as LLM-based agents) has amplified engineers' ability to detect patterns and synthesize content and recommendations, but many critical questions are interventional or counterfactual: What is the expected impact of changing a load-balancing strategy? Would an outage have been avoided under a different release plan? Correlational models answer "what tends to co-occur"; they struggle to answer "what would happen if we act." We propose Causal Software Engineering (CSE) as a future paradigm in which causal models and causal reasoning systematically inform activities across the software lifecycle, augmenting existing practices with explicit assumptions, uncertainty-aware effect estimates, and counterfactual diagnosis. We outline (i) a causal-first workflow view spanning development and operations, (ii) a staged roadmap for tools and organizational adoption, and (iii) an evaluation and benchmark agenda for measuring progress.
Evaluation of large language models for assessing code maintainability
Jan 23, 2024Increased availability of open-source software repositories and recent advances in code analysis using large language models (LLMs) has triggered a wave of new work to automate software engineering tasks that were previously very difficult to automate. In this paper, we investigate a recent line of work that hypothesises that comparing the probability of code generated by LLMs with the probability the current code would have had can indicate potential quality problems. We investigate the association between the cross-entropy of code generated by ten different models (based on GPT2 and Llama2) and the following quality aspects: readability, understandability, complexity, modularisation, and overall maintainability assessed by experts and available in an benchmark dataset. Our results show that, controlling for the number of logical lines of codes (LLOC), cross-entropy computed by LLMs is indeed a predictor of maintainability on a class level (the higher the cross-entropy the lower the maintainability). However, this relation is reversed when one does not control for LLOC (e.g., comparing small classes with longer ones). Furthermore, while the complexity of LLMs affects the range of cross-entropy (smaller models tend to have a wider range of cross-entropy), this plays a significant role in predicting maintainability aspects. Our study limits itself on ten different pretrained models (based on GPT2 and Llama2) and on maintainability aspects collected by Schnappinger et al. When controlling for logical lines of code (LLOC), cross-entropy is a predictor of maintainability. However, while related work has shown the potential usefulness of cross-entropy at the level of tokens or short sequences, at the class level this criterion alone may prove insufficient to predict maintainability and further research is needed to make best use of this information in practice.
Badgers: generating data quality deficits with Python
Jul 10, 2023


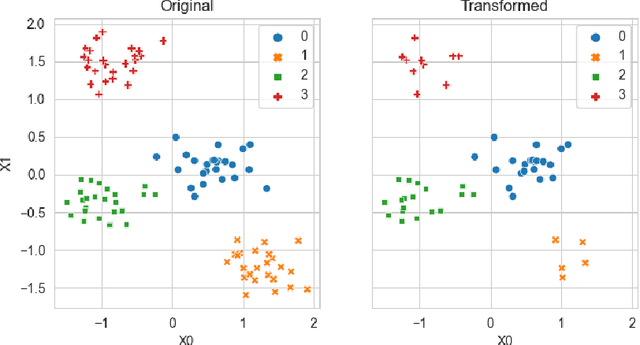
Generating context specific data quality deficits is necessary to experimentally assess data quality of data-driven (artificial intelligence (AI) or machine learning (ML)) applications. In this paper we present badgers, an extensible open-source Python library to generate data quality deficits (outliers, imbalanced data, drift, etc.) for different modalities (tabular data, time-series, text, etc.). The documentation is accessible at https://fraunhofer-iese.github.io/badgers/ and the source code at https://github.com/Fraunhofer-IESE/badgers
Applications of statistical causal inference in software engineering
Nov 21, 2022This paper reviews existing work in software engineering that applies statistical causal inference methods. These methods aim at estimating causal effects from observational data. The review covers 32 papers published between 2010 and 2022. Our results show that the application of statistical causal inference methods is relatively recent and that the corresponding research community remains relatively fragmented.
Software Engineering for AI-Based Systems: A Survey
May 05, 2021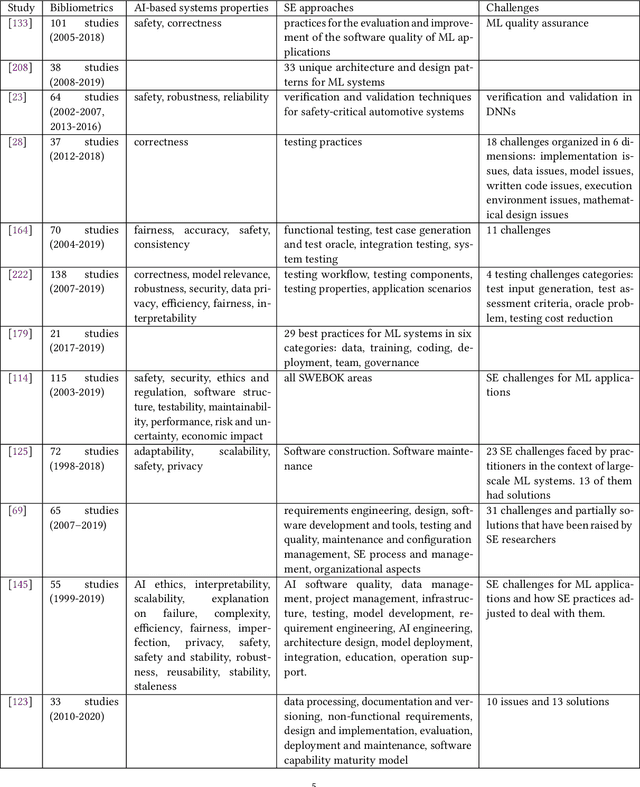
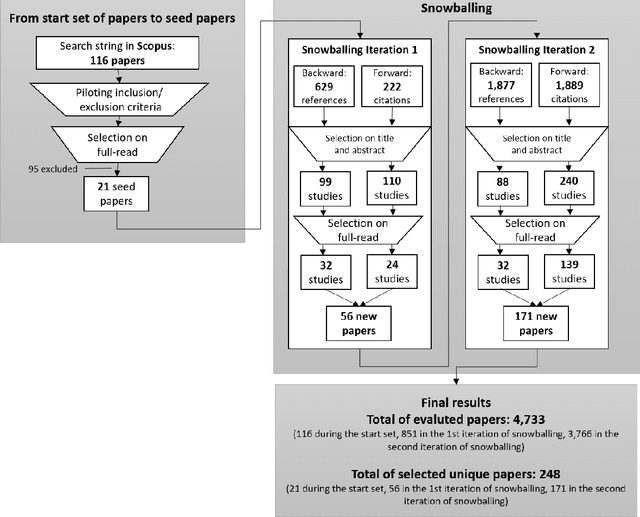

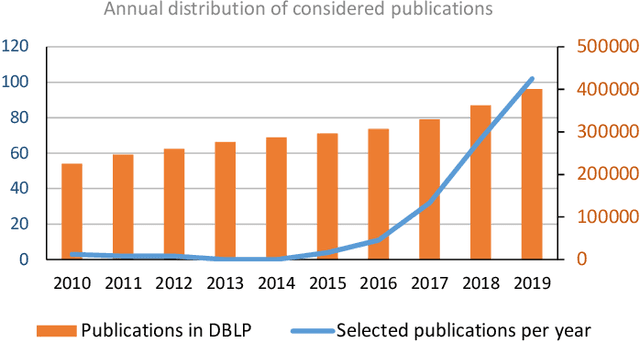
AI-based systems are software systems with functionalities enabled by at least one AI component (e.g., for image- and speech-recognition, and autonomous driving). AI-based systems are becoming pervasive in society due to advances in AI. However, there is limited synthesized knowledge on Software Engineering (SE) approaches for building, operating, and maintaining AI-based systems. To collect and analyze state-of-the-art knowledge about SE for AI-based systems, we conducted a systematic mapping study. We considered 248 studies published between January 2010 and March 2020. SE for AI-based systems is an emerging research area, where more than 2/3 of the studies have been published since 2018. The most studied properties of AI-based systems are dependability and safety. We identified multiple SE approaches for AI-based systems, which we classified according to the SWEBOK areas. Studies related to software testing and software quality are very prevalent, while areas like software maintenance seem neglected. Data-related issues are the most recurrent challenges. Our results are valuable for: researchers, to quickly understand the state of the art and learn which topics need more research; practitioners, to learn about the approaches and challenges that SE entails for AI-based systems; and, educators, to bridge the gap among SE and AI in their curricula.
Towards Guidelines for Assessing Qualities of Machine Learning Systems
Aug 25, 2020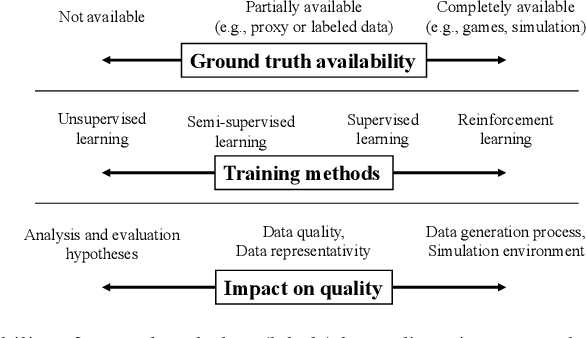
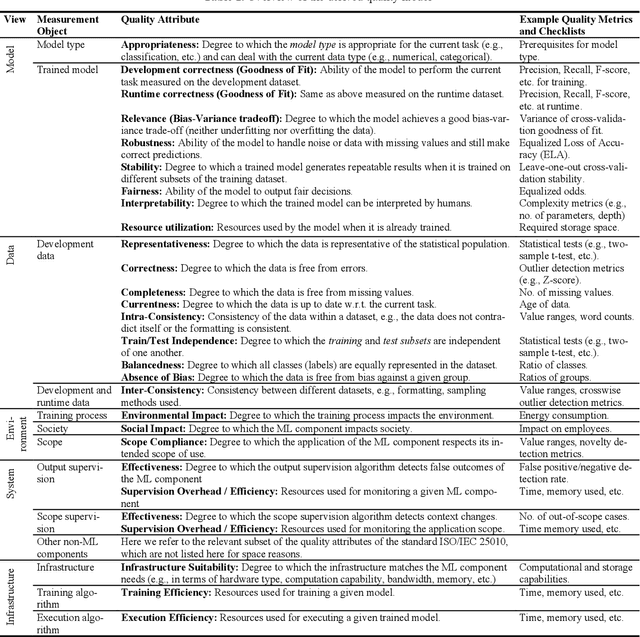
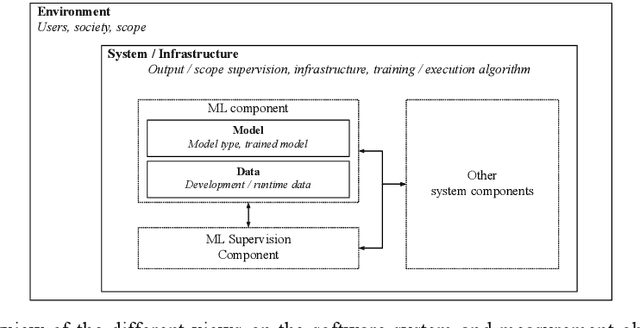
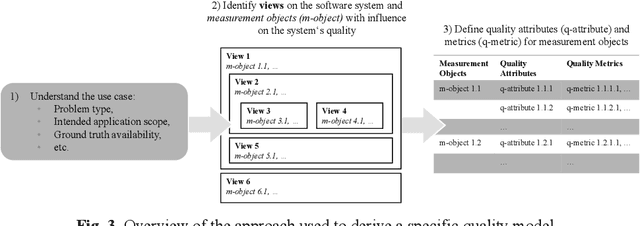
Nowadays, systems containing components based on machine learning (ML) methods are becoming more widespread. In order to ensure the intended behavior of a software system, there are standards that define necessary quality aspects of the system and its components (such as ISO/IEC 25010). Due to the different nature of ML, we have to adjust quality aspects or add additional ones (such as trustworthiness) and be very precise about which aspect is really relevant for which object of interest (such as completeness of training data), and how to objectively assess adherence to quality requirements. In this article, we present the construction of a quality model (i.e., evaluation objects, quality aspects, and metrics) for an ML system based on an industrial use case. This quality model enables practitioners to specify and assess quality requirements for such kinds of ML systems objectively. In the future, we want to learn how the term quality differs between different types of ML systems and come up with general guidelines for specifying and assessing qualities of ML systems.
* Has been accepted at the 13th International Conference on the Quality of Information and Communications Technology QUATIC2020 (https://2020.quatic.org/). QUATIC 2020 proceedings will be included in a volume of Springer CCIS Series (Communications in Computer and Information Science)