 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-H-Embodiment: A Large-Scale Dataset for Enabling Foundation Models in Medical Robotics
Apr 22, 2026Autonomous medical robots hold promise to improve patient outcomes, reduce provider workload, democratize access to care, and enable superhuman precision. However, autonomous medical robotics has been limited by a fundamental data problem: existing medical robotic datasets are small, single-embodiment, and rarely shared openly, restricting the development of foundation models that the field needs to advance. We introduce Open-H-Embodiment, the largest open dataset of medical robotic video with synchronized kinematics to date, spanning more than 49 institutions and multiple robotic platforms including the CMR Versius, Intuitive Surgical's da Vinci, da Vinci Research Kit (dVRK), Rob Surgical BiTrack, Virtual Incision's MIRA, Moon Surgical Maestro, and a variety of custom systems, spanning surgical manipulation, robotic ultrasound, and endoscopy procedures. We demonstrate the research enabled by this dataset through two foundation models. GR00T-H is the first open foundation vision-language-action model for medical robotics, which is the only evaluated model to achieve full end-to-end task completion on a structured suturing benchmark (25% of trials vs. 0% for all others) and achieves 64% average success across a 29-step ex vivo suturing sequence. We also train Cosmos-H-Surgical-Simulator, the first action-conditioned world model to enable multi-embodiment surgical simulation from a single checkpoint, spanning nine robotic platforms and supporting in silico policy evaluation and synthetic data generation for the medical domain. These results suggest that open, large-scale medical robot data collection can serve as critical infrastructure for the research community, enabling advances in robot learning, world modeling, and beyond.
A Multi-Robot Cooperation Framework for Sewing Personalized Stent Grafts
Nov 08, 2017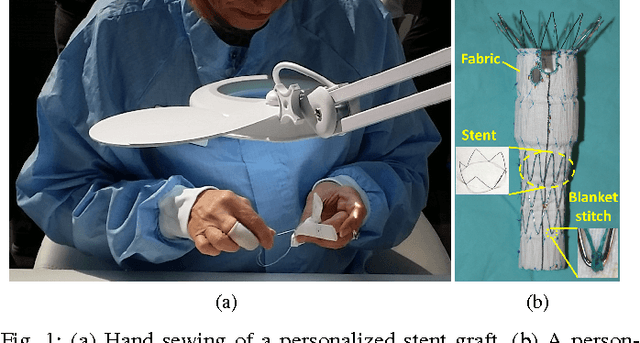

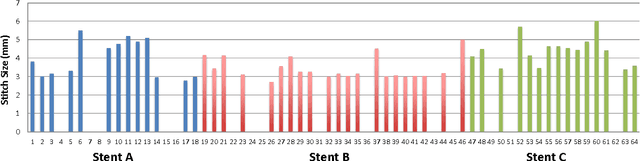

This paper presents a multi-robot system for manufacturing personalized medical stent grafts. The proposed system adopts a modular design, which includes: a (personalized) mandrel module, a bimanual sewing module, and a vision module. The mandrel module incorporates the personalized geometry of patients, while the bimanual sewing module adopts a learning-by-demonstration approach to transfer human hand-sewing skills to the robots. The human demonstrations were firstly observed by the vision module and then encoded using a statistical model to generate the reference motion trajectories. During autonomous robot sewing, the vision module plays the role of coordinating multi-robot collaboration. Experiment results show that the robots can adapt to generalized stent designs. The proposed system can also be used for other manipulation tasks, especially for flexible production of customized products and where bimanual or multi-robot cooperation is required.
A Vision-Guided Multi-Robot Cooperation Framework for Learning-by-Demonstration and Task Reproduction
Jun 01, 2017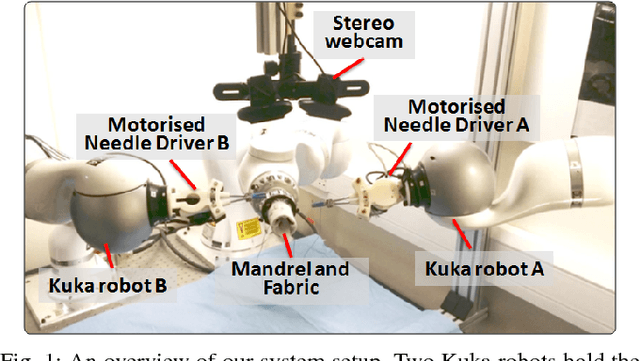
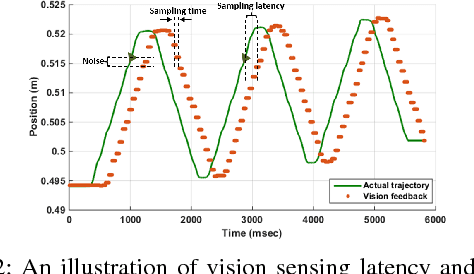
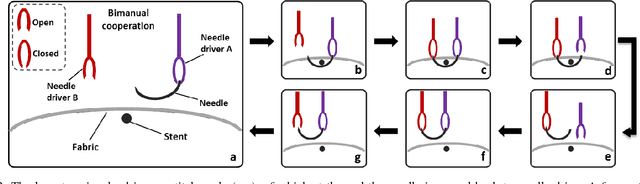

This paper presents a vision-based learning-by-demonstration approach to enable robots to learn and complete a manipulation task cooperatively. With this method, a vision system is involved in both the task demonstration and reproduction stages. An expert first demonstrates how to use tools to perform a task, while the tool motion is observed using a vision system. The demonstrations are then encoded using a statistical model to generate a reference motion trajectory. Equipped with the same tools and the learned model, the robot is guided by vision to reproduce the task. The task performance was evaluated in terms of both accuracy and speed. However, simply increasing the robot's speed could decrease the reproduction accuracy. To this end, a dual-rate Kalman filter is employed to compensate for latency between the robot and vision system. More importantly, the sampling rates of the reference trajectory and the robot speed are optimised adaptively according to the learned motion model. We demonstrate the effectiveness of our approach by performing two tasks: a trajectory reproduction task and a bimanual sewing task. We show that using our vision-based approach, the robots can conduct effective learning by demonstrations and perform accurate and fast task reproduction. The proposed approach is generalisable to other manipulation tasks, where bimanual or multi-robot cooperation is required.
Self-Supervised Siamese Learning on Stereo Image Pairs for Depth Estimation in Robotic Surgery
May 17, 2017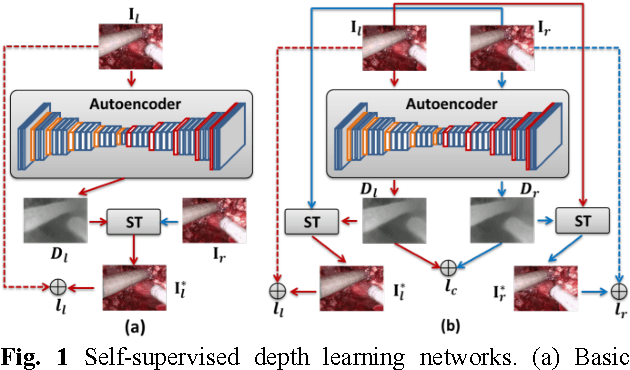
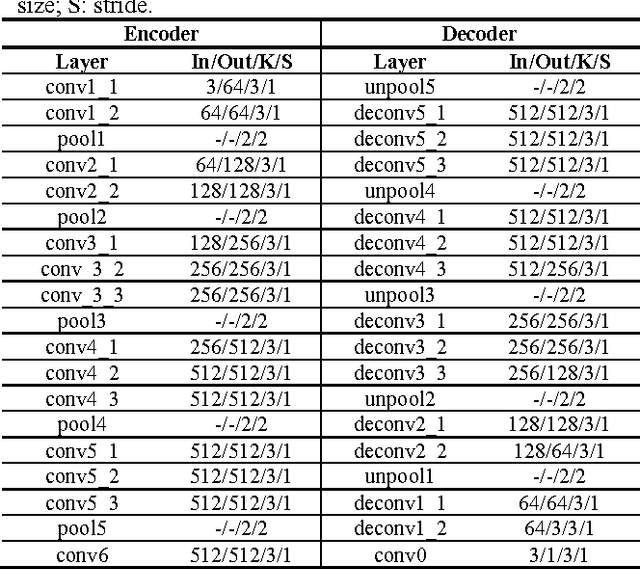
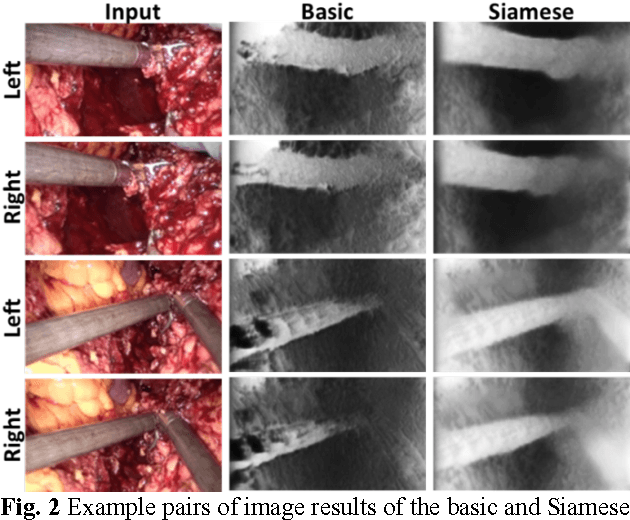

Robotic surgery has become a powerful tool for performing minimally invasive procedures, providing advantages in dexterity, precision, and 3D vision, over traditional surgery. One popular robotic system is the da Vinci surgical platform, which allows preoperative information to be incorporated into live procedures using Augmented Reality (AR). Scene depth estimation is a prerequisite for AR, as accurate registration requires 3D correspondences between preoperative and intraoperative organ models. In the past decade, there has been much progress on depth estimation for surgical scenes, such as using monocular or binocular laparoscopes [1,2]. More recently, advances in deep learning have enabled depth estimation via Convolutional Neural Networks (CNNs) [3], but training requires a large image dataset with ground truth depths. Inspired by [4], we propose a deep learning framework for surgical scene depth estimation using self-supervision for scalable data acquisition. Our framework consists of an autoencoder for depth prediction, and a differentiable spatial transformer for training the autoencoder on stereo image pairs without ground truth depths. Validation was conducted on stereo videos collected in robotic partial nephrectomy.
Motion-Compensated Autonomous Scanning for Tumour Localisation using Intraoperative Ultrasound
May 16, 2017



Intraoperative ultrasound facilitates localisation of tumour boundaries during minimally invasive procedures. Autonomous ultrasound scanning systems have been recently proposed to improve scanning accuracy and reduce surgeons' cognitive load. However, current methods mainly consider static scanning environments typically with the probe pressing against the tissue surface. In this work, a motion-compensated autonomous ultrasound scanning system using the da Vinci Research Kit (dVRK) is proposed. An optimal scanning trajectory is generated considering both the tissue surface shape and the ultrasound transducer dimensions. A robust vision-based approach is proposed to learn the underlying tissue motion characteristics. The learned motion model is then incorporated into the visual servoing framework. The proposed system has been validated with both phantom and ex vivo experiments using the ground truth motion data for comparison.
Robust Image Descriptors for Real-Time Inter-Examination Retargeting in Gastrointestinal Endoscopy
Oct 30, 2016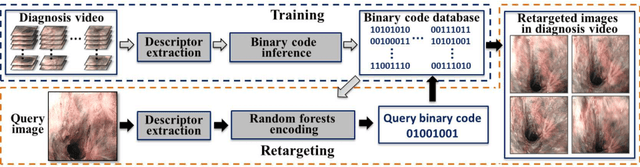

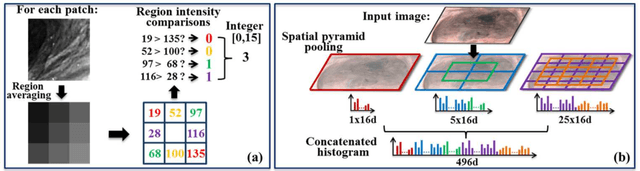
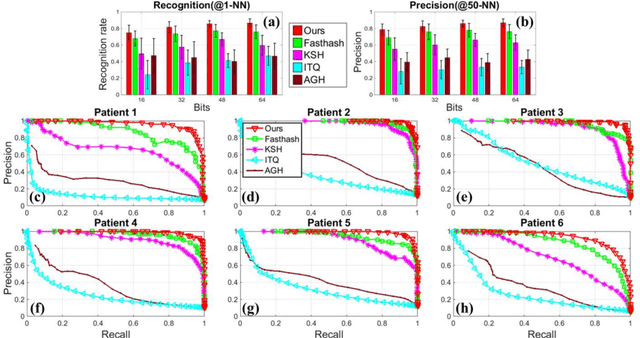
For early diagnosis of malignancies in the gastrointestinal tract, surveillance endoscopy is increasingly used to monitor abnormal tissue changes in serial examinations of the same patient. Despite successes with optical biopsy for in vivo and in situ tissue characterisation, biopsy retargeting for serial examinations is challenging because tissue may change in appearance between examinations. In this paper, we propose an inter-examination retargeting framework for optical biopsy, based on an image descriptor designed for matching between endoscopic scenes over significant time intervals. Each scene is described by a hierarchy of regional intensity comparisons at various scales, offering tolerance to long-term change in tissue appearance whilst remaining discriminative. Binary coding is then used to compress the descriptor via a novel random forests approach, providing fast comparisons in Hamming space and real-time retargeting. Extensive validation conducted on 13 in vivo gastrointestinal videos, collected from six patients, show that our approach outperforms state-of-the-art methods.
Real-time 3D Tracking of Articulated Tools for Robotic Surgery
Oct 30, 2016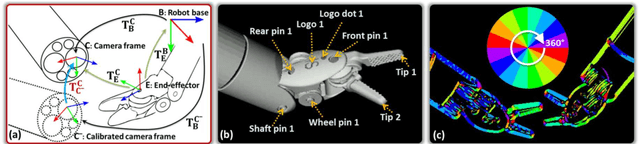
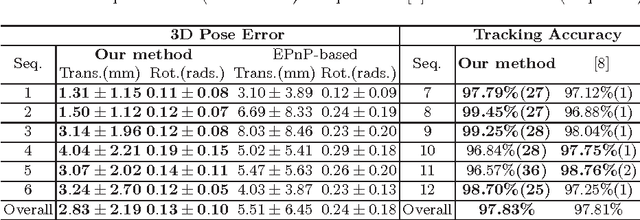
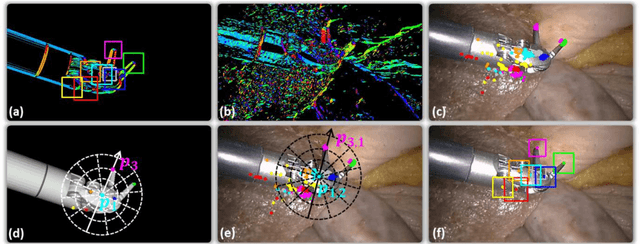
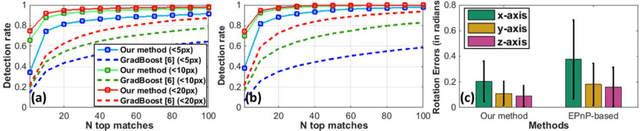
In robotic surgery, tool tracking is important for providing safe tool-tissue interaction and facilitating surgical skills assessment. Despite recent advances in tool tracking, existing approaches are faced with major difficulties in real-time tracking of articulated tools. Most algorithms are tailored for offline processing with pre-recorded videos. In this paper, we propose a real-time 3D tracking method for articulated tools in robotic surgery. The proposed method is based on the CAD model of the tools as well as robot kinematics to generate online part-based templates for efficient 2D matching and 3D pose estimation. A robust verification approach is incorporated to reject outliers in 2D detections, which is then followed by fusing inliers with robot kinematic readings for 3D pose estimation of the tool. The proposed method has been validated with phantom data, as well as ex vivo and in vivo experiments. The results derived clearly demonstrate the performance advantage of the proposed method when compared to the state-of-the-art.
Autonomous Scanning for Endomicroscopic Mosaicing and 3D Fusion
Oct 21, 2016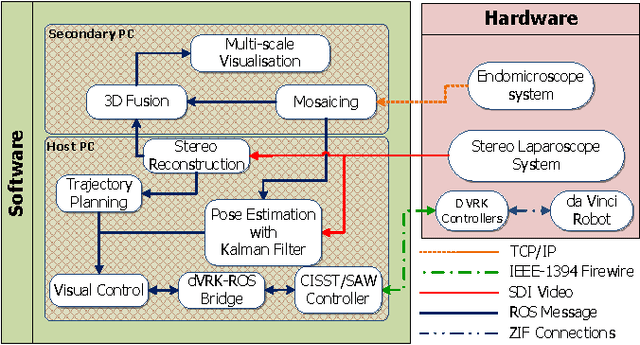
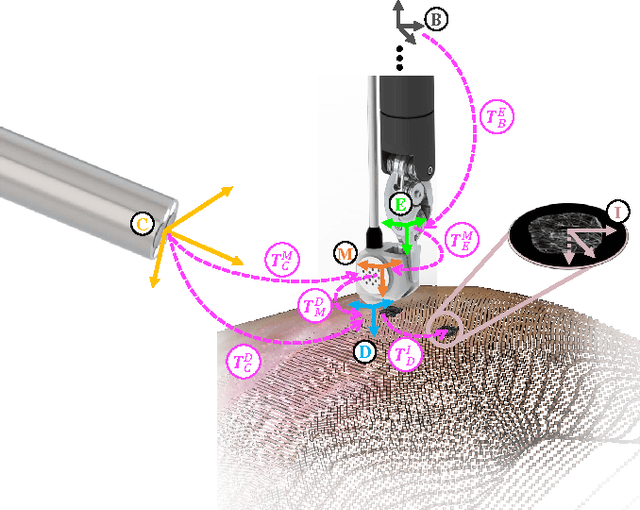
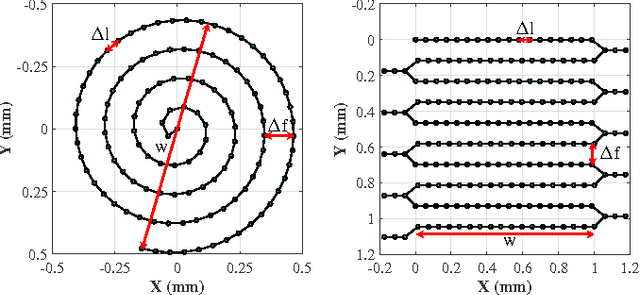
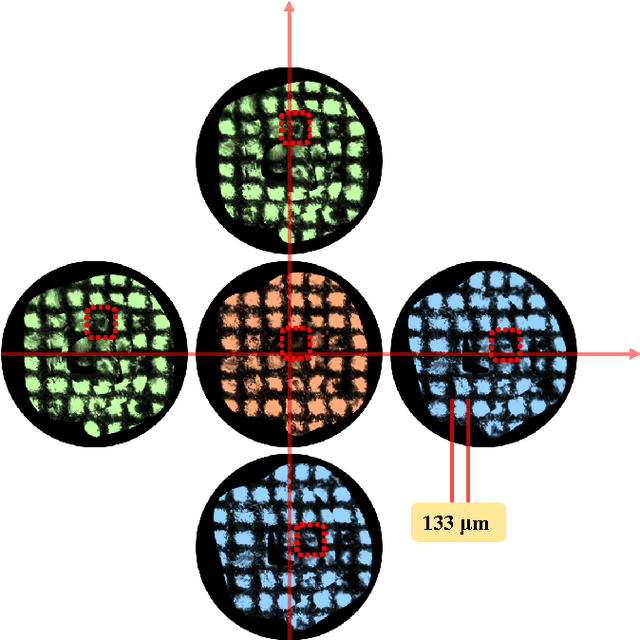
Robotic-assisted Minimally Invasive Surgery (RMIS) can benefit from the automation of common, repetitive or well-defined but ergonomically difficult tasks. One such task is the scanning of a pick-up endomicroscopy probe over a complex, undulating tissue surface in order to enhance the effective field-of-view through video mosaicing. In this paper, the da Vinci surgical robot, through the dVRK framework, is used for autonomous scanning and 2D mosaicing over a user-defined region of interest. To achieve the level of precision required for high quality large-area mosaic generation, which relies on sufficient overlap between consecutive image frames, visual servoing is performed using a tracking marker attached to the probe. The resulting sub-millimetre accuracy of the probe motion allows for the generation of large endomicroscopy mo- saics with minimal intervention from the surgeon. It also allows the probe to be maintained in an orientation perpendicular to the local tissue surface, providing optimal imaging results. Images are streamed from the endomicroscope and overlaid live onto the surgeons view, while 2D mosaics are generated in real-time, and fused into a 3D stereo reconstruction of the surgical scene, thus providing intuitive visualisation and fusion of the multi-scale images. The system therefore offers significant potential to enhance surgical procedures, by providing the operator with cellular-scale information over a larger area than could typically be achieved by manual scanning.