 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automatic 3D Shape Instantiation for Deployed Stent Grafts: 2D Multiple-class and Class-imbalance Marker Segmentation with Equally-weighted Focal U-Net
Jul 31, 2018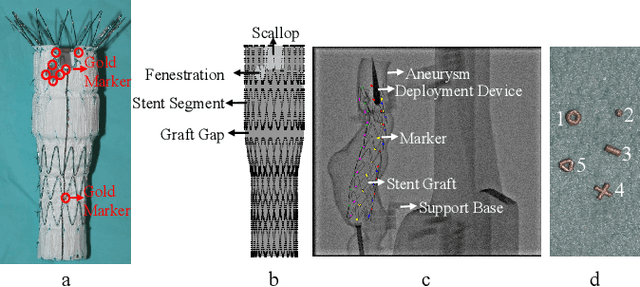
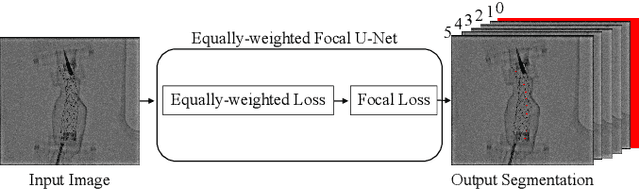
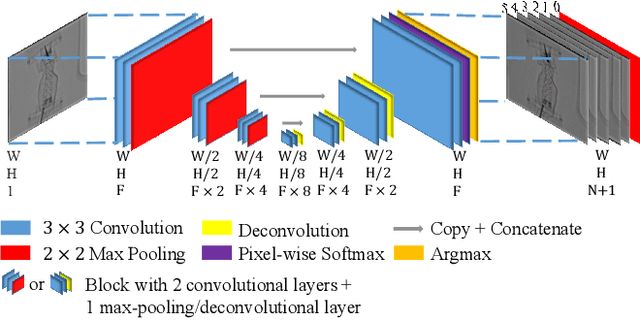

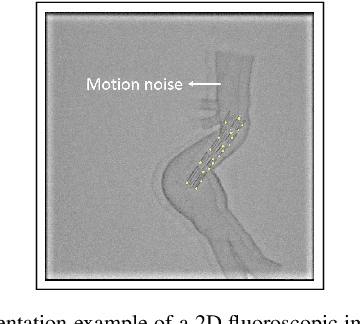
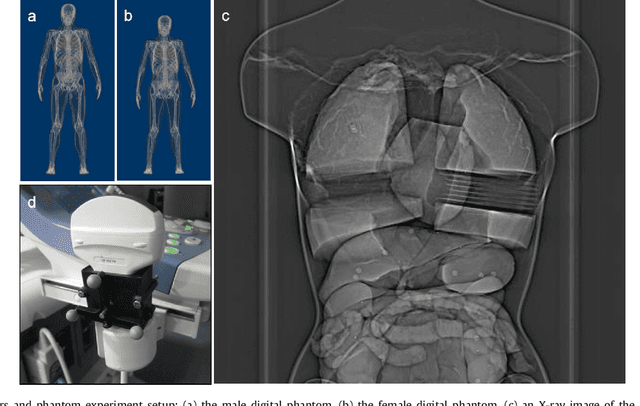
Robot-assisted Fenestrated Endovascular Aortic Repair (FEVAR) is currently navigated by 2D fluoroscopy which is insufficiently informative. Previously, a semi-automatic 3D shape instantiation method was developed to instantiate the 3D shape of a main, deployed, and fenestrated stent graft from a single fluoroscopy projection in real-time, which could help 3D FEVAR navigation and robotic path planning. This proposed semi-automatic method was based on the Robust Perspective-5-Point (RP5P) method, graft gap interpolation and semi-automatic multiple-class marker center determination. In this paper, an automatic 3D shape instantiation could be achieved by automatic multiple-class marker segmentation and hence automatic multiple-class marker center determination. Firstly, the markers were designed into five different shapes. Then, Equally-weighted Focal U-Net was proposed to segment the fluoroscopy projections of customized markers into five classes and hence to determine the marker centers. The proposed Equally-weighted Focal U-Net utilized U-Net as the network architecture, equally-weighted loss function for initial marker segmentation, and then equally-weighted focal loss function for improving the initial marker segmentation. This proposed network outperformed traditional Weighted U-Net on the class-imbalance segmentation in this paper with reducing one hyper-parameter - the weight. An overall mean Intersection over Union (mIoU) of 0.6943 was achieved on 78 testing images, where 81.01% markers were segmented with a center position error <1.6mm. Comparable accuracy of 3D shape instantiation was also achieved and stated. The data, trained models and TensorFlow codes are available on-line.
Real-time 3D Shape Instantiation from Single Fluoroscopy Projection for Fenestrated Stent Graft Deployment
Jan 08, 2018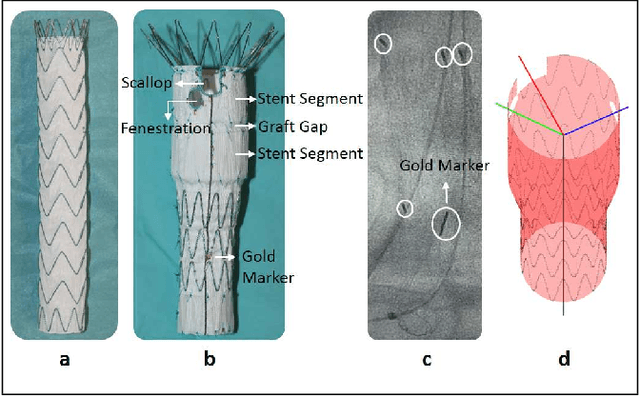
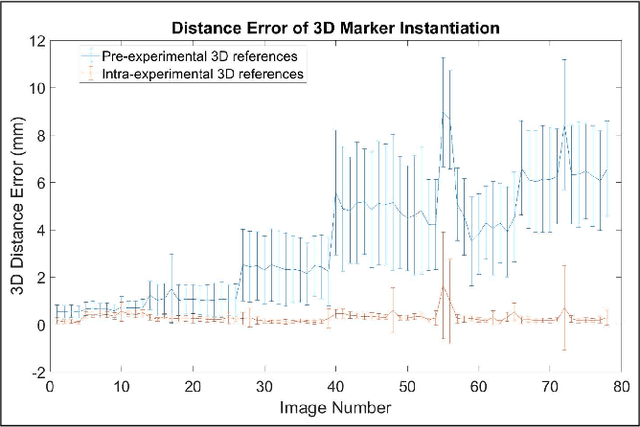
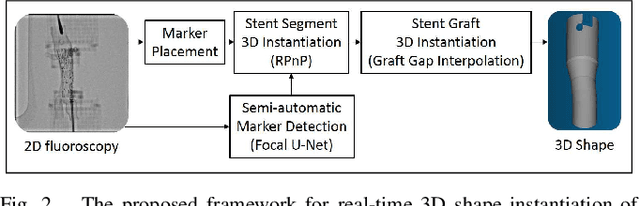
Robot-assisted deployment of fenestrated stent grafts in Fenestrated Endovascular Aortic Repair (FEVAR) requires accurate geometrical alignment. Currently, this process is guided by 2D fluoroscopy, which is uninformative and error prone. In this paper, a real-time framework is proposed to instantiate the 3D shape of a fenestrated stent graft based on only a single low-dose 2D fluoroscopic image. Firstly, the fenestrated stent graft was placed with markers. Secondly, the 3D pose of each stent segment was instantiated by the RPnP (Robust Perspective-n-Point) method. Thirdly, the 3D shape of the whole stent graft was instantiated via graft gap interpolation. Focal-Unet was proposed to segment the markers from 2D fluoroscopic images to achieve semi-automatic marker detection. The proposed framework was validated on five patient-specific 3D printed phantoms of aortic aneurysms and three stent grafts with new marker placements, showing an average distance error of 1-3mm and an average angle error of 4 degree.
* 7 pages, 10 figures
A Real-time and Registration-free Framework for Dynamic Shape Instantiation
Dec 30, 2017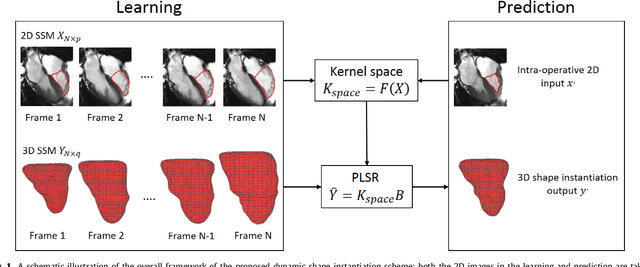
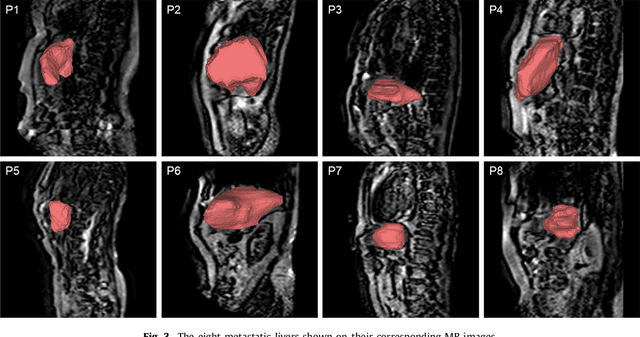
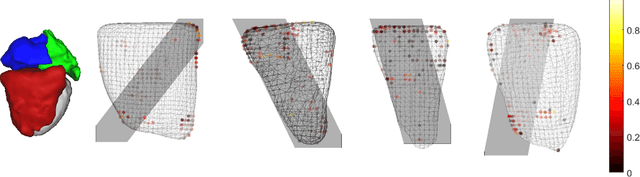
Real-time 3D navigation during minimally invasive procedures is an essential yet challenging task, especially when considerable tissue motion is involved. To balance image acquisition speed and resolution, only 2D images or low-resolution 3D volumes can be used clinically. In this paper, a real-time and registration-free framework for dynamic shape instantiation, generalizable to multiple anatomical applications, is proposed to instantiate high-resolution 3D shapes of an organ from a single 2D image intra-operatively. Firstly, an approximate optimal scan plane was determined by analyzing the pre-operative 3D statistical shape model (SSM) of the anatomy with sparse principal component analysis (SPCA) and considering practical constraints . Secondly, kernel partial least squares regression (KPLSR) was used to learn the relationship between the pre-operative 3D SSM and a synchronized 2D SSM constructed from 2D images obtained at the approximate optimal scan plane. Finally, the derived relationship was applied to the new intra-operative 2D image obtained at the same scan plane to predict the high-resolution 3D shape intra-operatively. A major feature of the proposed framework is that no extra registration between the pre-operative 3D SSM and the synchronized 2D SSM is required. Detailed validation was performed on studies including the liver and right ventricle (RV) of the heart. The derived results (mean accuracy of 2.19mm on patients and computation speed of 1ms) demonstrate its potential clinical value for real-time, high-resolution, dynamic and 3D interventional guidance.
* 35 Pages, 11 figures
A Multi-Robot Cooperation Framework for Sewing Personalized Stent Grafts
Nov 08, 2017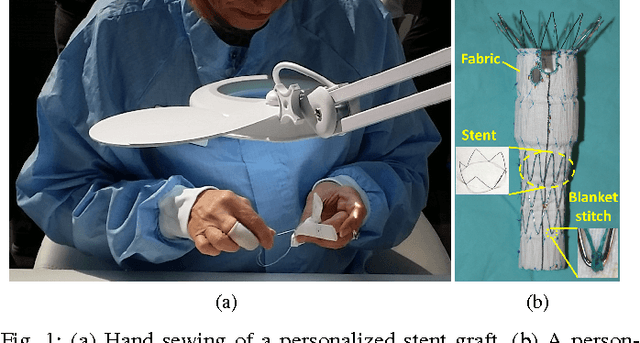

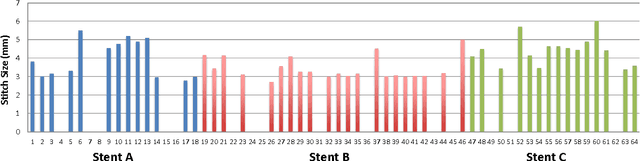

This paper presents a multi-robot system for manufacturing personalized medical stent grafts. The proposed system adopts a modular design, which includes: a (personalized) mandrel module, a bimanual sewing module, and a vision module. The mandrel module incorporates the personalized geometry of patients, while the bimanual sewing module adopts a learning-by-demonstration approach to transfer human hand-sewing skills to the robots. The human demonstrations were firstly observed by the vision module and then encoded using a statistical model to generate the reference motion trajectories. During autonomous robot sewing, the vision module plays the role of coordinating multi-robot collaboration. Experiment results show that the robots can adapt to generalized stent designs. The proposed system can also be used for other manipulation tasks, especially for flexible production of customized products and where bimanual or multi-robot cooperation is required.
A Vision-Guided Multi-Robot Cooperation Framework for Learning-by-Demonstration and Task Reproduction
Jun 01, 2017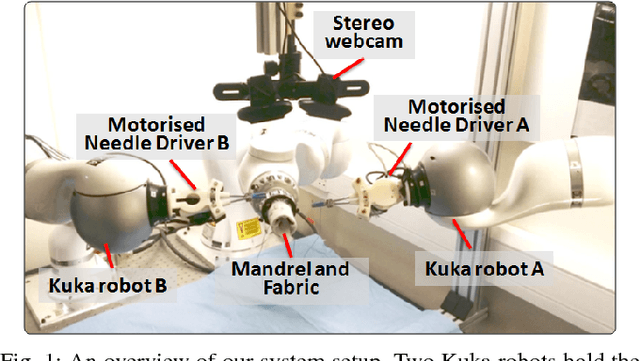
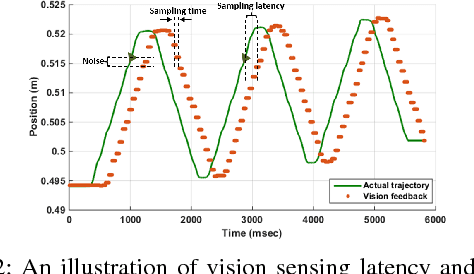
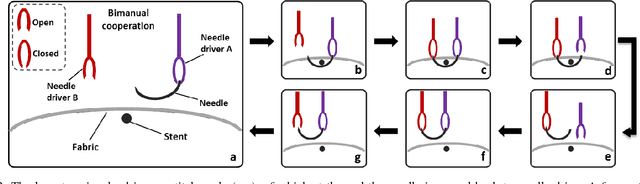

This paper presents a vision-based learning-by-demonstration approach to enable robots to learn and complete a manipulation task cooperatively. With this method, a vision system is involved in both the task demonstration and reproduction stages. An expert first demonstrates how to use tools to perform a task, while the tool motion is observed using a vision system. The demonstrations are then encoded using a statistical model to generate a reference motion trajectory. Equipped with the same tools and the learned model, the robot is guided by vision to reproduce the task. The task performance was evaluated in terms of both accuracy and speed. However, simply increasing the robot's speed could decrease the reproduction accuracy. To this end, a dual-rate Kalman filter is employed to compensate for latency between the robot and vision system. More importantly, the sampling rates of the reference trajectory and the robot speed are optimised adaptively according to the learned motion model. We demonstrate the effectiveness of our approach by performing two tasks: a trajectory reproduction task and a bimanual sewing task. We show that using our vision-based approach, the robots can conduct effective learning by demonstrations and perform accurate and fast task reproduction. The proposed approach is generalisable to other manipulation tasks, where bimanual or multi-robot cooperation is required.