 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexFruit: Dexterous Manipulation and Gaussian Splatting Inspection of Fruit
Aug 09, 2025DexFruit is a robotic manipulation framework that enables gentle, autonomous handling of fragile fruit and precise evaluation of damage. Many fruits are fragile and prone to bruising, thus requiring humans to manually harvest them with care. In this work, we demonstrate by using optical tactile sensing, autonomous manipulation of fruit with minimal damage can be achieved. We show that our tactile informed diffusion policies outperform baselines in both reduced bruising and pick-and-place success rate across three fruits: strawberries, tomatoes, and blackberries. In addition, we introduce FruitSplat, a novel technique to represent and quantify visual damage in high-resolution 3D representation via 3D Gaussian Splatting (3DGS). Existing metrics for measuring damage lack quantitative rigor or require expensive equipment. With FruitSplat, we distill a 2D strawberry mask as well as a 2D bruise segmentation mask into the 3DGS representation. Furthermore, this representation is modular and general, compatible with any relevant 2D model. Overall, we demonstrate a 92% grasping policy success rate, up to a 20% reduction in visual bruising, and up to an 31% improvement in grasp success rate on challenging fruit compared to our baselines across our three tested fruits. We rigorously evaluate this result with over 630 trials. Please checkout our website at https://dex-fruit.github.io .
TensorTouch: Calibration of Tactile Sensors for High Resolution Stress Tensor and Deformation for Dexterous Manipulation
Jun 09, 2025Advanced dexterous manipulation involving multiple simultaneous contacts across different surfaces, like pinching coins from ground or manipulating intertwined objects, remains challenging for robotic systems. Such tasks exceed the capabilities of vision and proprioception alone, requiring high-resolution tactile sensing with calibrated physical metrics. Raw optical tactile sensor images, while information-rich, lack interpretability and cross-sensor transferability, limiting their real-world utility. TensorTouch addresses this challenge by integrating finite element analysis with deep learning to extract comprehensive contact information from optical tactile sensors, including stress tensors, deformation fields, and force distributions at pixel-level resolution. The TensorTouch framework achieves sub-millimeter position accuracy and precise force estimation while supporting large sensor deformations crucial for manipulating soft objects. Experimental validation demonstrates 90% success in selectively grasping one of two strings based on detected motion, enabling new contact-rich manipulation capabilities previously inaccessible to robotic systems.
J-PARSE: Jacobian-based Projection Algorithm for Resolving Singularities Effectively in Inverse Kinematic Control of Serial Manipulators
May 01, 2025J-PARSE is a method for smooth first-order inverse kinematic control of a serial manipulator near kinematic singularities. The commanded end-effector velocity is interpreted component-wise, according to the available mobility in each dimension of the task space. First, a substitute "Safety" Jacobian matrix is created, keeping the aspect ratio of the manipulability ellipsoid above a threshold value. The desired motion is then projected onto non-singular and singular directions, and the latter projection scaled down by a factor informed by the threshold value. A right-inverse of the non-singular Safety Jacobian is applied to the modified command. In the absence of joint limits and collisions, this ensures smooth transition into and out of low-rank poses, guaranteeing asymptotic stability for target poses within the workspace, and stability for those outside. Velocity control with J-PARSE is benchmarked against the Least-Squares and Damped Least-Squares inversions of the Jacobian, and shows high accuracy in reaching and leaving singular target poses. By expanding the available workspace of manipulators, the method finds applications in servoing, teleoperation, and learning.
Next Best Sense: Guiding Vision and Touch with FisherRF for 3D Gaussian Splatting
Oct 07, 2024



We propose a framework for active next best view and touch selection for robotic manipulators using 3D Gaussian Splatting (3DGS). 3DGS is emerging as a useful explicit 3D scene representation for robotics, as it has the ability to represent scenes in a both photorealistic and geometrically accurate manner. However, in real-world, online robotic scenes where the number of views is limited given efficiency requirements, random view selection for 3DGS becomes impractical as views are often overlapping and redundant. We address this issue by proposing an end-to-end online training and active view selection pipeline, which enhances the performance of 3DGS in few-view robotics settings. We first elevate the performance of few-shot 3DGS with a novel semantic depth alignment method using Segment Anything Model 2 (SAM2) that we supplement with Pearson depth and surface normal loss to improve color and depth reconstruction of real-world scenes. We then extend FisherRF, a next-best-view selection method for 3DGS, to select views and touch poses based on depth uncertainty. We perform online view selection on a real robot system during live 3DGS training. We motivate our improvements to few-shot GS scenes, and extend depth-based FisherRF to them, where we demonstrate both qualitative and quantitative improvements on challenging robot scenes. For more information, please see our project page at https://armlabstanford.github.io/next-best-sense.
Touch-GS: Visual-Tactile Supervised 3D Gaussian Splatting
Mar 18, 2024In this work, we propose a novel method to supervise 3D Gaussian Splatting (3DGS) scenes using optical tactile sensors. Optical tactile sensors have become widespread in their use in robotics for manipulation and object representation; however, raw optical tactile sensor data is unsuitable to directly supervise a 3DGS scene. Our representation leverages a Gaussian Process Implicit Surface to implicitly represent the object, combining many touches into a unified representation with uncertainty. We merge this model with a monocular depth estimation network, which is aligned in a two stage process, coarsely aligning with a depth camera and then finely adjusting to match our touch data. For every training image, our method produces a corresponding fused depth and uncertainty map. Utilizing this additional information, we propose a new loss function, variance weighted depth supervised loss, for training the 3DGS scene model. We leverage the DenseTact optical tactile sensor and RealSense RGB-D camera to show that combining touch and vision in this manner leads to quantitatively and qualitatively better results than vision or touch alone in a few-view scene syntheses on opaque as well as on reflective and transparent objects. Please see our project page at http://armlabstanford.github.io/touch-gs
Contact Anticipation for Physical Human-Robot Interaction with Robotic Manipulators using Onboard Proximity Sensors
Nov 16, 2021
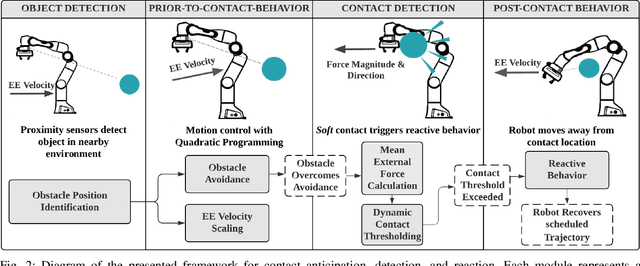

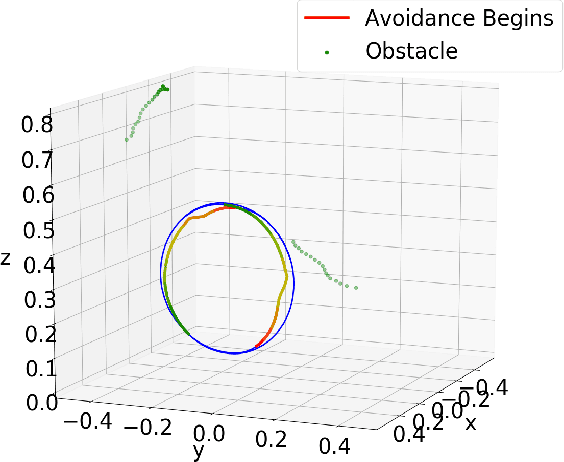
In this paper, we present a framework that unites obstacle avoidance and deliberate physical interaction for robotic manipulators. As humans and robots begin to coexist in work and household environments, pure collision avoidance is insufficient, as human-robot contact is inevitable and, in some situations, desired. Our work enables manipulators to anticipate, detect, and act on contact. To achieve this, we allow limited deviation from the robot's original trajectory through velocity reduction and motion restrictions. Then, if contact occurs, a robot can detect it and maneuver based on a novel dynamic contact thresholding algorithm. The core contribution of this work is dynamic contact thresholding, which allows a manipulator with onboard proximity sensors to track nearby objects and reduce contact forces in anticipation of a collision. Our framework elicits natural behavior during physical human-robot interaction. We evaluate our system on a variety of scenarios using the Franka Emika Panda robot arm; collectively, our results demonstrate that our contribution is not only able to avoid and react on contact, but also anticipate it.
Self-Contained Kinematic Calibration of a Novel Whole-Body Artificial Skin for Human-Robot Collaboration
Oct 27, 2021
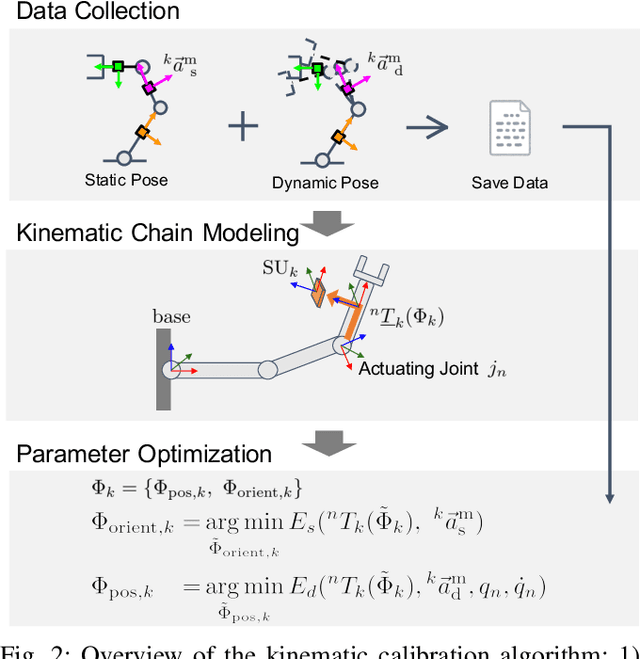
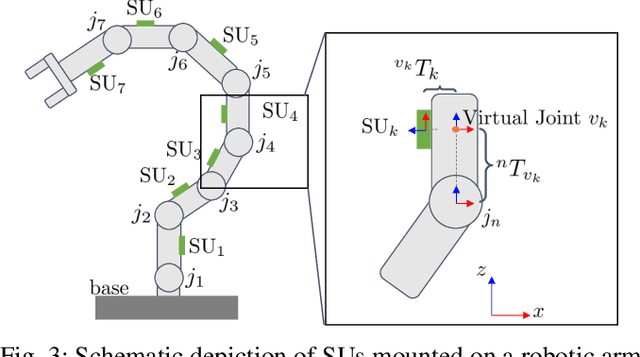
In this paper, we present an accelerometer-based kinematic calibration algorithm to accurately estimate the pose of multiple sensor units distributed along a robot body. Our approach is self-contained, can be used on any robot provided with a Denavit-Hartenberg kinematic model, and on any skin equipped with Inertial Measurement Units (IMUs). To validate the proposed method, we first conduct extensive experimentation in simulation and demonstrate a sub-cm positional error from ground truth data --an improvement of six times with respect to prior work; subsequently, we then perform a real-world evaluation on a seven degrees-of-freedom collaborative platform. For this purpose, we additionally introduce a novel design for a stand-alone artificial skin equipped with an IMU for use with the proposed algorithm and a proximity sensor for sensing distance to nearby objects. In conclusion, in this work, we demonstrate seamless integration between a novel hardware design, an accurate calibration method, and preliminary work on applications: the high positional accuracy effectively enables to locate distributed proximity data and allows for a distributed avoidance controller to safely avoid obstacles and people without the need of additional sensing.
Volumetric Data Fusion of External Depth and Onboard Proximity Data For Occluded Space Reduction
Oct 21, 2021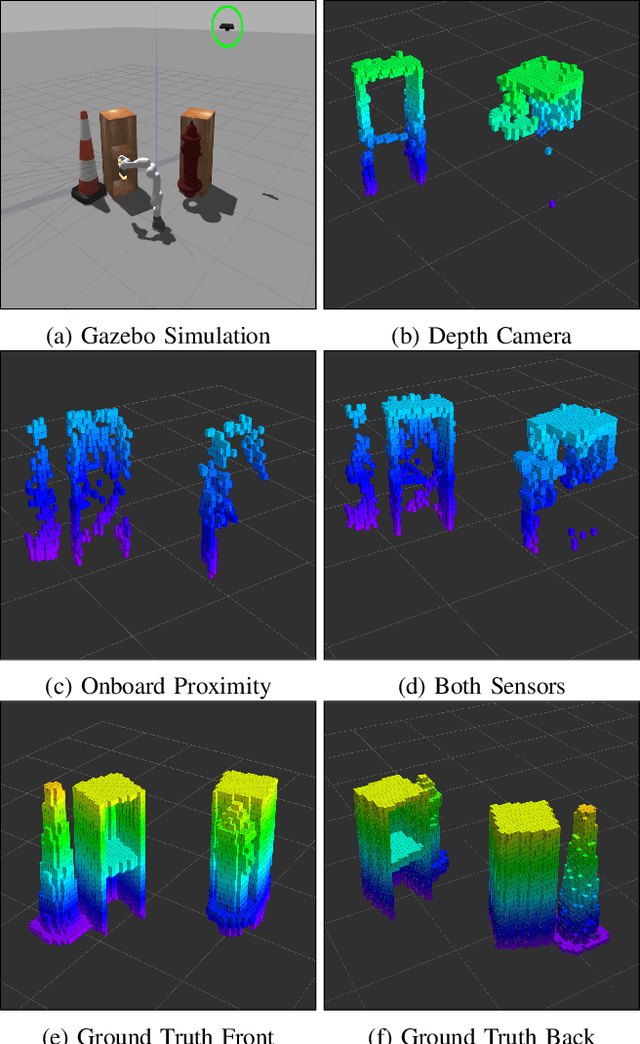
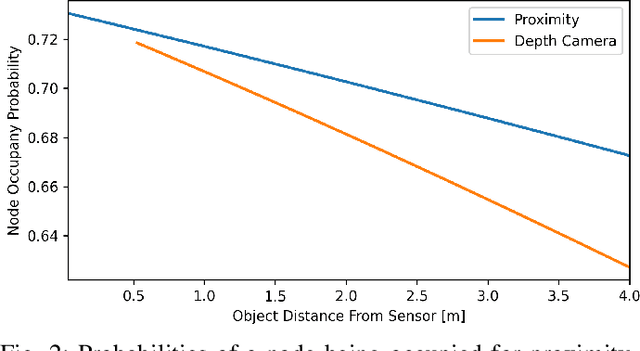
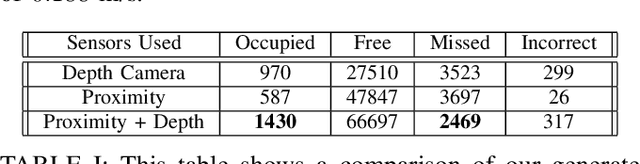
In this work, we present a method for a probabilistic fusion of external depth and onboard proximity data to form a volumetric 3-D map of a robot's environment. We extend the Octomap framework to update a representation of the area around the robot, dependent on each sensor's optimal range of operation. Areas otherwise occluded from an external view are sensed with onboard sensors to construct a more comprehensive map of a robot's nearby space. Our simulated results show that a more accurate map with less occlusions can be generated by fusing external depth and onboard proximity data.