 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHIRO: Soft Hierarchical Reinforcement Learning
Dec 24, 2022Hierarchical Reinforcement Learning (HRL) algorithms have been demonstrated to perform well on high-dimensional decision making and robotic control tasks. However, because they solely optimize for rewards, the agent tends to search the same space redundantly. This problem reduces the speed of learning and achieved reward. In this work, we present an Off-Policy HRL algorithm that maximizes entropy for efficient exploration. The algorithm learns a temporally abstracted low-level policy and is able to explore broadly through the addition of entropy to the high-level. The novelty of this work is the theoretical motivation of adding entropy to the RL objective in the HRL setting. We empirically show that the entropy can be added to both levels if the Kullback-Leibler (KL) divergence between consecutive updates of the low-level policy is sufficiently small. We performed an ablative study to analyze the effects of entropy on hierarchy, in which adding entropy to high-level emerged as the most desirable configuration. Furthermore, a higher temperature in the low-level leads to Q-value overestimation and increases the stochasticity of the environment that the high-level operates on, making learning more challenging. Our method, SHIRO, surpasses state-of-the-art performance on a range of simulated robotic control benchmark tasks and requires minimal tuning.
Self-Contained Kinematic Calibration of a Novel Whole-Body Artificial Skin for Human-Robot Collaboration
Oct 27, 2021
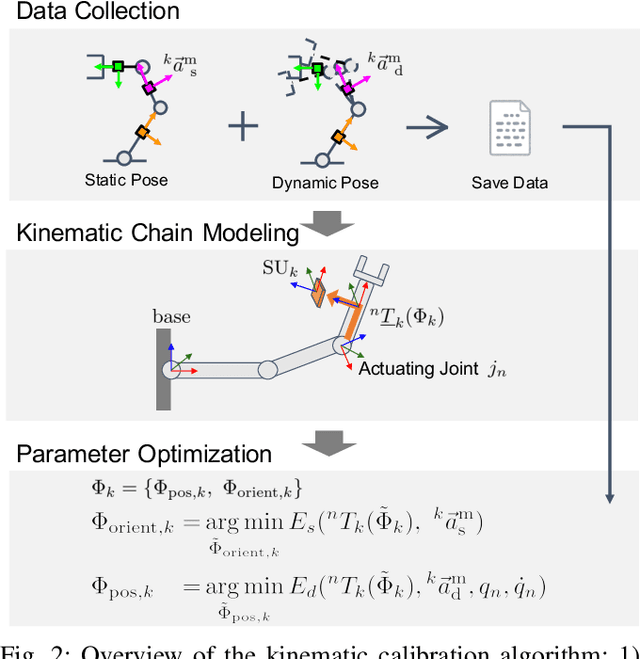
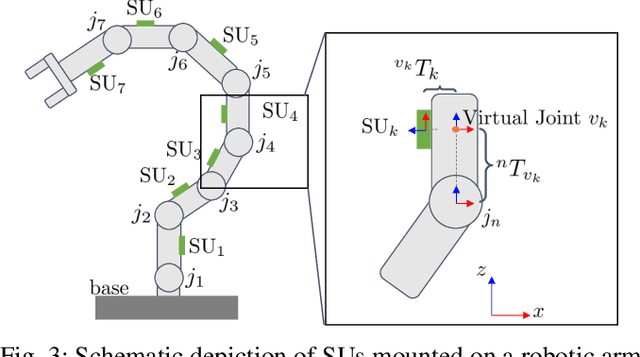
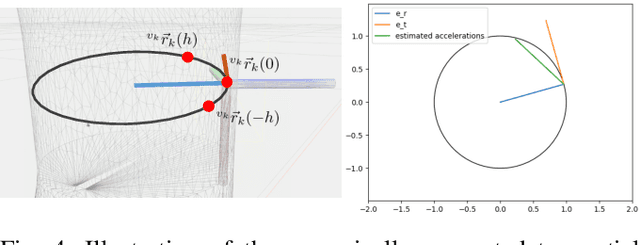
In this paper, we present an accelerometer-based kinematic calibration algorithm to accurately estimate the pose of multiple sensor units distributed along a robot body. Our approach is self-contained, can be used on any robot provided with a Denavit-Hartenberg kinematic model, and on any skin equipped with Inertial Measurement Units (IMUs). To validate the proposed method, we first conduct extensive experimentation in simulation and demonstrate a sub-cm positional error from ground truth data --an improvement of six times with respect to prior work; subsequently, we then perform a real-world evaluation on a seven degrees-of-freedom collaborative platform. For this purpose, we additionally introduce a novel design for a stand-alone artificial skin equipped with an IMU for use with the proposed algorithm and a proximity sensor for sensing distance to nearby objects. In conclusion, in this work, we demonstrate seamless integration between a novel hardware design, an accurate calibration method, and preliminary work on applications: the high positional accuracy effectively enables to locate distributed proximity data and allows for a distributed avoidance controller to safely avoid obstacles and people without the need of additional sensing.