 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSustainable Transfer Learning for Adaptive Robot Skills
Apr 08, 2026Learning robot skills from scratch is often time-consuming, while reusing data promotes sustainability and improves sample efficiency. This study investigates policy transfer across different robotic platforms, focusing on peg-in-hole task using reinforcement learning (RL). Policy training is carried out on two different robots. Their policies are transferred and evaluated for zero-shot, fine-tuning, and training from scratch. Results indicate that zero-shot transfer leads to lower success rates and relatively longer task execution times, while fine-tuning significantly improves performance with fewer training time-steps. These findings highlight that policy transfer with adaptation techniques improves sample efficiency and generalization, reducing the need for extensive retraining and supporting sustainable robotic learning.
* Published in RAAD 2025 (Springer). 7 pages, 5 figures
Learning-Based Strategy for Composite Robot Assembly Skill Adaptation
Apr 08, 2026Contact-rich robotic skills remain challenging for industrial robots due to tight geometric tolerances, frictional variability, and uncertain contact dynamics, particularly when using position-controlled manipulators. This paper presents a reusable and encapsulated skill-based strategy for peg-in-hole assembly, in which adaptation is achieved through Residual Reinforcement Learning (RRL). The assembly process is represented using composite skills with explicit pre-, post-, and invariant conditions, enabling modularity, reusability, and well-defined execution semantics across task variations. Safety and sample efficiency are promoted through RRL by restricting adaptation to residual refinements within each skill during contact-rich interactions, while the overall skill structure and execution flow remain invariant. The proposed approach is evaluated in MuJoCo simulation on a UR5e robot equipped with a Robotiq gripper and trained using SAC and JAX. Results demonstrate that the proposed formulation enables robust execution of assembly skills, highlighting its suitability for industrial automation.
Towards Robust Federated Image Classification: An Empirical Study of Weight Selection Strategies in Manufacturing
Aug 21, 2024
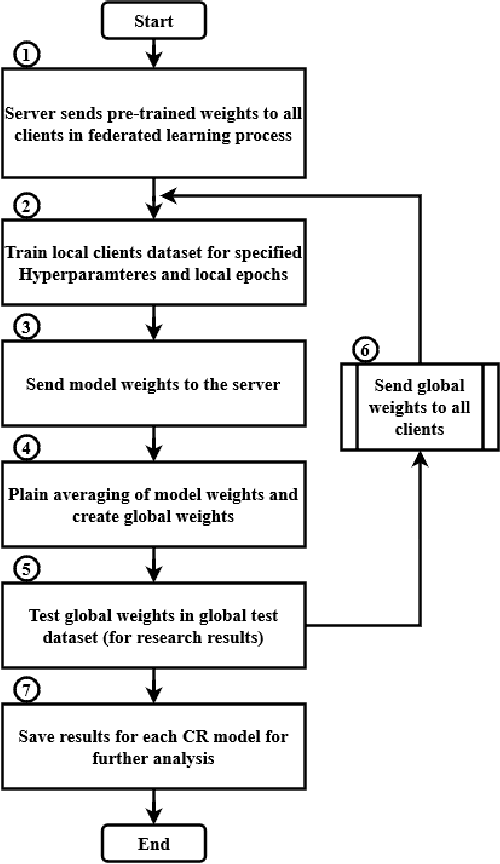
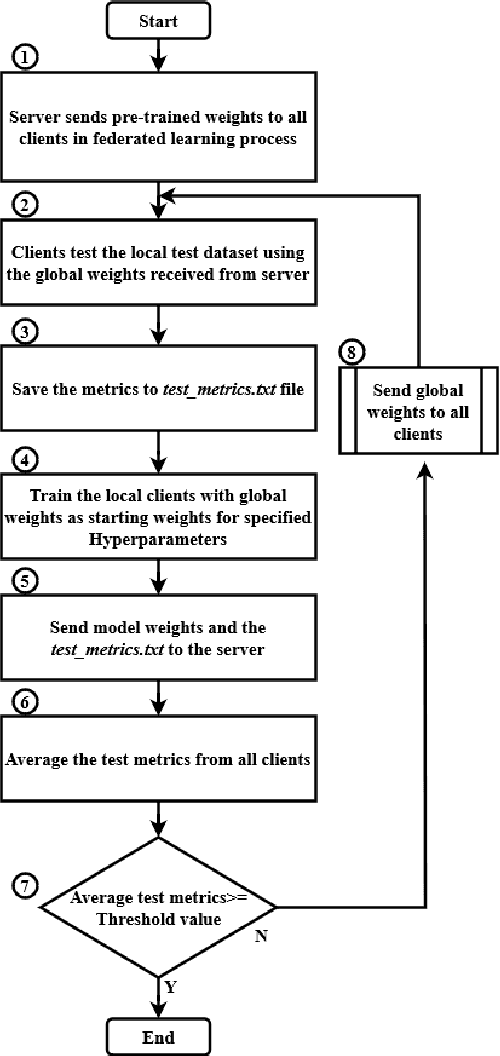

In the realm of Federated Learning (FL), particularly within the manufacturing sector, the strategy for selecting client weights for server aggregation is pivotal for model performance. This study investigates the comparative effectiveness of two weight selection strategies: Final Epoch Weight Selection (FEWS) and Optimal Epoch Weight Selection (OEWS). Designed for manufacturing contexts where collaboration typically involves a limited number of partners (two to four clients), our research focuses on federated image classification tasks. We employ various neural network architectures, including EfficientNet, ResNet, and VGG, to assess the impact of these weight selection strategies on model convergence and robustness. Our research aims to determine whether FEWS or OEWS enhances the global FL model's performance across communication rounds (CRs). Through empirical analysis and rigorous experimentation, we seek to provide valuable insights for optimizing FL implementations in manufacturing, ensuring that collaborative efforts yield the most effective and reliable models with a limited number of participating clients. The findings from this study are expected to refine FL practices significantly in manufacturing, thereby enhancing the efficiency and performance of collaborative machine learning endeavors in this vital sector.
Seamless Integration: Sampling Strategies in Federated Learning Systems
Aug 20, 2024

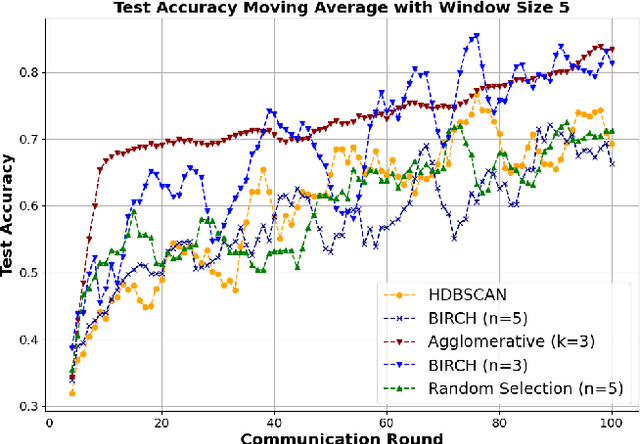

Federated Learning (FL) represents a paradigm shift in the field of machine learning, offering an approach for a decentralized training of models across a multitude of devices while maintaining the privacy of local data. However, the dynamic nature of FL systems, characterized by the ongoing incorporation of new clients with potentially diverse data distributions and computational capabilities, poses a significant challenge to the stability and efficiency of these distributed learning networks. The seamless integration of new clients is imperative to sustain and enhance the performance and robustness of FL systems. This paper looks into the complexities of integrating new clients into existing FL systems and explores how data heterogeneity and varying data distribution (not independent and identically distributed) among them can affect model training, system efficiency, scalability and stability. Despite these challenges, the integration of new clients into FL systems presents opportunities to enhance data diversity, improve learning performance, and leverage distributed computational power. In contrast to other fields of application such as the distributed optimization of word predictions on Gboard (where federated learning once originated), there are usually only a few clients in the production environment, which is why information from each new client becomes all the more valuable. This paper outlines strategies for effective client selection strategies and solutions for ensuring system scalability and stability. Using the example of images from optical quality inspection, it offers insights into practical approaches. In conclusion, this paper proposes that addressing the challenges presented by new client integration is crucial to the advancement and efficiency of distributed learning networks, thus paving the way for the adoption of Federated Learning in production environments.
Enhancing Object Detection with Hybrid dataset in Manufacturing Environments: Comparing Federated Learning to Conventional Techniques
Aug 16, 2024



Federated Learning (FL) has garnered significant attention in manufacturing for its robust model development and privacy-preserving capabilities. This paper contributes to research focused on the robustness of FL models in object detection, hereby presenting a comparative study with conventional techniques using a hybrid dataset for small object detection. Our findings demonstrate the superior performance of FL over centralized training models and different deep learning techniques when tested on test data recorded in a different environment with a variety of object viewpoints, lighting conditions, cluttered backgrounds, etc. These results highlight the potential of FL in achieving robust global models that perform efficiently even in unseen environments. The study provides valuable insights for deploying resilient object detection models in manufacturing environments.
Enhancing Object Detection Performance for Small Objects through Synthetic Data Generation and Proportional Class-Balancing Technique: A Comparative Study in Industrial Scenarios
Jan 29, 2024



Object Detection (OD) has proven to be a significant computer vision method in extracting localized class information and has multiple applications in the industry. Although many of the state-of-the-art (SOTA) OD models perform well on medium and large sized objects, they seem to under perform on small objects. In most of the industrial use cases, it is difficult to collect and annotate data for small objects, as it is time-consuming and prone to human errors. Additionally, those datasets are likely to be unbalanced and often result in an inefficient model convergence. To tackle this challenge, this study presents a novel approach that injects additional data points to improve the performance of the OD models. Using synthetic data generation, the difficulties in data collection and annotations for small object data points can be minimized and to create a dataset with balanced distribution. This paper discusses the effects of a simple proportional class-balancing technique, to enable better anchor matching of the OD models. A comparison was carried out on the performances of the SOTA OD models: YOLOv5, YOLOv7 and SSD, for combinations of real and synthetic datasets within an industrial use case.
State Derivative Normalization for Continuous-Time Deep Neural Networks
Jan 05, 2024
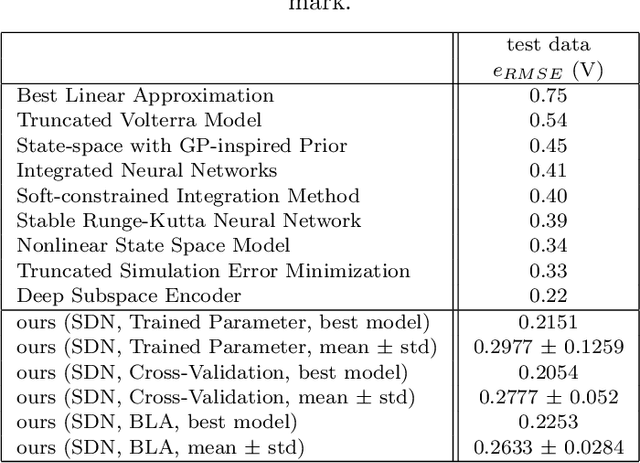


The importance of proper data normalization for deep neural networks is well known. However, in continuous-time state-space model estimation, it has been observed that improper normalization of either the hidden state or hidden state derivative of the model estimate, or even of the time interval can lead to numerical and optimization challenges with deep learning based methods. This results in a reduced model quality. In this contribution, we show that these three normalization tasks are inherently coupled. Due to the existence of this coupling, we propose a solution to all three normalization challenges by introducing a normalization constant at the state derivative level. We show that the appropriate choice of the normalization constant is related to the dynamics of the to-be-identified system and we derive multiple methods of obtaining an effective normalization constant. We compare and discuss all the normalization strategies on a benchmark problem based on experimental data from a cascaded tanks system and compare our results with other methods of the identification literature.
Federated K-Means Clustering via Dual Decomposition-based Distributed Optimization
Jul 25, 2023The use of distributed optimization in machine learning can be motivated either by the resulting preservation of privacy or the increase in computational efficiency. On the one hand, training data might be stored across multiple devices. Training a global model within a network where each node only has access to its confidential data requires the use of distributed algorithms. Even if the data is not confidential, sharing it might be prohibitive due to bandwidth limitations. On the other hand, the ever-increasing amount of available data leads to large-scale machine learning problems. By splitting the training process across multiple nodes its efficiency can be significantly increased. This paper aims to demonstrate how dual decomposition can be applied for distributed training of $ K $-means clustering problems. After an overview of distributed and federated machine learning, the mixed-integer quadratically constrained programming-based formulation of the $ K $-means clustering training problem is presented. The training can be performed in a distributed manner by splitting the data across different nodes and linking these nodes through consensus constraints. Finally, the performance of the subgradient method, the bundle trust method, and the quasi-Newton dual ascent algorithm are evaluated on a set of benchmark problems. While the mixed-integer programming-based formulation of the clustering problems suffers from weak integer relaxations, the presented approach can potentially be used to enable an efficient solution in the future, both in a central and distributed setting.
Federated Ensemble YOLOv5 - A Better Generalized Object Detection Algorithm
Jun 30, 2023

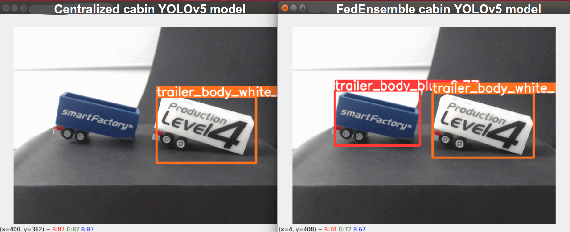

Federated learning (FL) has gained significant traction as a privacy-preserving algorithm, but the underlying resembles of federated learning algorithm like Federated averaging (FED Avg) or Federated SGD (FED SGD) to ensemble learning algorithms has not been fully explored. The purpose of this paper is to examine the application of FL to object detection as a method to enhance generalizability, and to compare its performance against a centralized training approach for an object detection algorithm. Specifically, we investigate the performance of a YOLOv5 model trained using FL across multiple clients and employ a random sampling strategy without replacement, so each client holds a portion of the same dataset used for centralized training. Our experimental results showcase the superior efficiency of the FL object detector's global model in generating accurate bounding boxes for unseen objects, with the test set being a mixture of objects from two distinct clients not represented in the training dataset. These findings suggest that FL can be viewed from an ensemble algorithm perspective, akin to a synergistic blend of Bagging and Boosting techniques. As a result, FL can be seen not only as a method to enhance privacy, but also as a method to enhance the performance of a machine learning model.
Federated Object Detection for Quality Inspection in Shared Production
Jun 30, 2023



Federated learning (FL) has emerged as a promising approach for training machine learning models on decentralized data without compromising data privacy. In this paper, we propose a FL algorithm for object detection in quality inspection tasks using YOLOv5 as the object detection algorithm and Federated Averaging (FedAvg) as the FL algorithm. We apply this approach to a manufacturing use-case where multiple factories/clients contribute data for training a global object detection model while preserving data privacy on a non-IID dataset. Our experiments demonstrate that our FL approach achieves better generalization performance on the overall clients' test dataset and generates improved bounding boxes around the objects compared to models trained using local clients' datasets. This work showcases the potential of FL for quality inspection tasks in the manufacturing industry and provides valuable insights into the performance and feasibility of utilizing YOLOv5 and FedAvg for federated object detection.