 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication of federated learning in manufacturing
Paper and Code
Aug 09, 2022

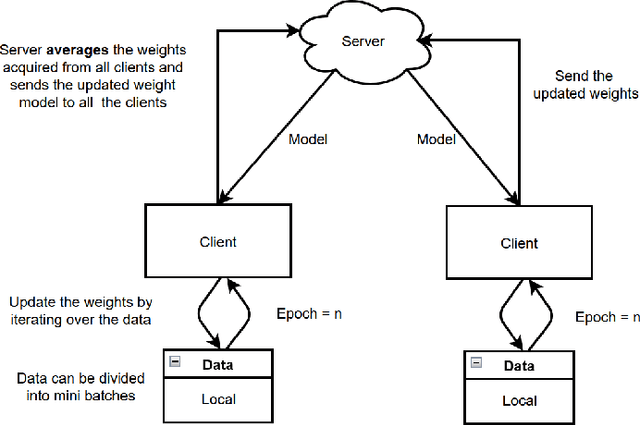

A vast amount of data is created every minute, both in the private sector and industry. Whereas it is often easy to get hold of data in the private entertainment sector, in the industrial production environment it is much more difficult due to laws, preservation of intellectual property, and other factors. However, most machine learning methods require a data source that is sufficient in terms of quantity and quality. A suitable way to bring both requirements together is federated learning where learning progress is aggregated, but everyone remains the owner of their data. Federate learning was first proposed by Google researchers in 2016 and is used for example in the improvement of Google's keyboard Gboard. In contrast to billions of android users, comparable machinery is only used by few companies. This paper examines which other constraints prevail in production and which federated learning approaches can be considered as a result.