 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Estimation and Generalization Bounds for Modern Deep Learning
Jun 11, 2026This thesis investigates how Bayesian principles can deepen our understanding of modern deep learning systems. While neural networks achieve remarkable predictive performance, their ability to generalize and to quantify uncertainty remains only partly understood. This thesis approaches this challenge from both methodological and theoretical angles: unifying Bayesian inference, function-space modeling, and large-deviation theory under a common probabilistic perspective. On the methodological side, the thesis introduces the Deep Variational Implicit Process (DVIP), a scalable Bayesian framework that extends implicit processes to deep architectures. Complementing this, two post-hoc methods -- the Variational Linearized Laplace Approximation (VaLLA) and the Fixed-Mean Gaussian Process (FMGP) -- are proposed to equip pretrained deterministic networks with calibrated uncertainty estimates. The theoretical contributions focus on one of the central open questions in modern machine learning: why do large, over-parameterized neural networks generalize so well? To address this, the thesis develops a unified probabilistic framework that connects three key mechanisms -- diversity, smoothness, and stochasticity -- within the language of PAC-Bayesian and large-deviation theory.
Flow-Transformed Implicit Processes for Function-Space Variational Inference
Jun 01, 2026Implicit-process priors define distributions over functions through flexible generative mechanisms, making them attractive for Bayesian function-space modelling. However, performing posterior inference with such priors is challenging because their induced function-space distributions are typically not available in closed form. One practical strategy is to approximate the prior using a finite collection of sampled functions, and then represent posterior functions as learned combinations of these samples. Existing approaches commonly place a Gaussian variational distribution over the combination weights. While tractable, this choice limits the shapes of posterior uncertainty that can be represented, especially when the true posterior is asymmetric, heavy-tailed, or multimodal. We propose Flow-Transformed Implicit Processes (FTIP), a variational inference method that makes this finite-dimensional function-space approximation more expressive. Instead of using a Gaussian distribution over the combination weights, FTIP uses a normalizing flow to define a richer variational distribution. This induces a flexible posterior distribution over functions while preserving tractable optimization. We train the model using a Black-Box α objective, allowing us to compare mass-covering and mode-seeking variational behaviour. Experiments show that FTIP captures asymmetric and multimodal posterior structure in function space that Gaussian coefficient approximations tend to smooth or collapse.
Improving the Linearized Laplace Approximation via Quadratic Approximations
Feb 03, 2026Deep neural networks (DNNs) often produce overconfident out-of-distribution predictions, motivating Bayesian uncertainty quantification. The Linearized Laplace Approximation (LLA) achieves this by linearizing the DNN and applying Laplace inference to the resulting model. Importantly, the linear model is also used for prediction. We argue this linearization in the posterior may degrade fidelity to the true Laplace approximation. To alleviate this problem, without increasing significantly the computational cost, we propose the Quadratic Laplace Approximation (QLA). QLA approximates each second order factor in the approximate Laplace log-posterior using a rank-one factor obtained via efficient power iterations. QLA is expected to yield a posterior precision closer to that of the full Laplace without forming the full Hessian, which is typically intractable. For prediction, QLA also uses the linearized model. Empirically, QLA yields modest yet consistent uncertainty estimation improvements over LLA on five regression datasets.
Scalable Linearized Laplace Approximation via Surrogate Neural Kernel
Jan 29, 2026We introduce a scalable method to approximate the kernel of the Linearized Laplace Approximation (LLA). For this, we use a surrogate deep neural network (DNN) that learns a compact feature representation whose inner product replicates the Neural Tangent Kernel (NTK). This avoids the need to compute large Jacobians. Training relies solely on efficient Jacobian-vector products, allowing to compute predictive uncertainty on large-scale pre-trained DNNs. Experimental results show similar or improved uncertainty estimation and calibration compared to existing LLA approximations. Notwithstanding, biasing the learned kernel significantly enhances out-of-distribution detection. This remarks the benefits of the proposed method for finding better kernels than the NTK in the context of LLA to compute prediction uncertainty given a pre-trained DNN.
Fixed-Mean Gaussian Processes for Post-hoc Bayesian Deep Learning
Dec 05, 2024Recently, there has been an increasing interest in performing post-hoc uncertainty estimation about the predictions of pre-trained deep neural networks (DNNs). Given a pre-trained DNN via back-propagation, these methods enhance the original network by adding output confidence measures, such as error bars, without compromising its initial accuracy. In this context, we introduce a novel family of sparse variational Gaussian processes (GPs), where the posterior mean is fixed to any continuous function when using a universal kernel. Specifically, we fix the mean of this GP to the output of the pre-trained DNN, allowing our approach to effectively fit the GP's predictive variances to estimate the DNN prediction uncertainty. Our approach leverages variational inference (VI) for efficient stochastic optimization, with training costs that remain independent of the number of training points, scaling efficiently to large datasets such as ImageNet. The proposed method, called fixed mean GP (FMGP), is architecture-agnostic, relying solely on the pre-trained model's outputs to adjust the predictive variances. Experimental results demonstrate that FMGP improves both uncertainty estimation and computational efficiency when compared to state-of-the-art methods.
PAC-Bayes-Chernoff bounds for unbounded losses
Jan 05, 2024We present a new high-probability PAC-Bayes oracle bound for unbounded losses. This result can be understood as a PAC-Bayes version of the Chernoff bound. The proof technique relies on uniformly bounding the tail of certain random variable based on the Cram\'er transform of the loss. We highlight two applications of our main result. First, we show that our bound solves the open problem of optimizing the free parameter on many PAC-Bayes bounds. Finally, we show that our approach allows working with flexible assumptions on the loss function, resulting in novel bounds that generalize previous ones and can be minimized to obtain Gibbs-like posteriors.
If there is no underfitting, there is no Cold Posterior Effect
Oct 02, 2023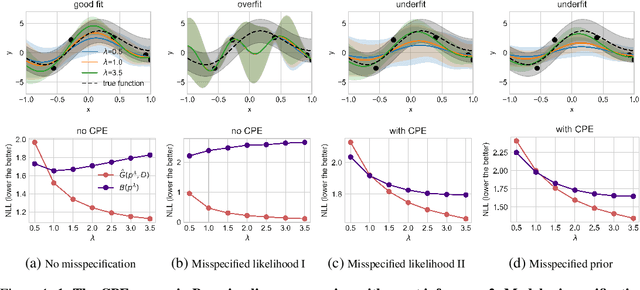
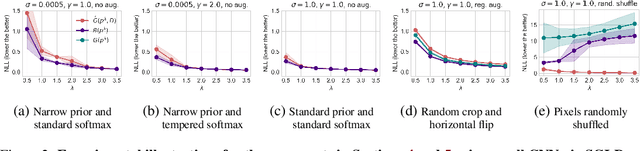
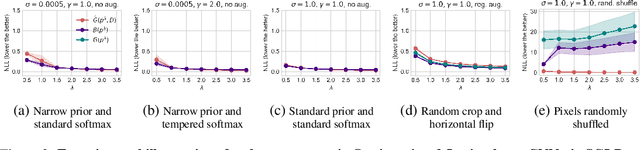
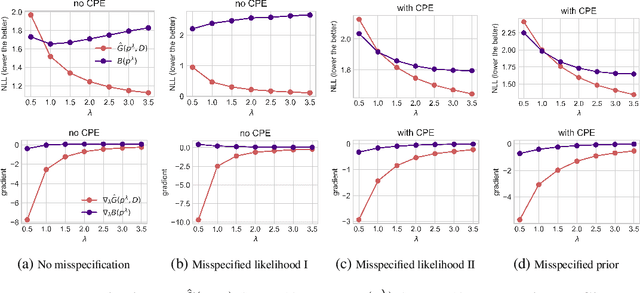
The cold posterior effect (CPE) (Wenzel et al., 2020) in Bayesian deep learning shows that, for posteriors with a temperature $T<1$, the resulting posterior predictive could have better performances than the Bayesian posterior ($T=1$). As the Bayesian posterior is known to be optimal under perfect model specification, many recent works have studied the presence of CPE as a model misspecification problem, arising from the prior and/or from the likelihood function. In this work, we provide a more nuanced understanding of the CPE as we show that misspecification leads to CPE only when the resulting Bayesian posterior underfits. In fact, we theoretically show that if there is no underfitting, there is no CPE.
Understanding Generalization in the Interpolation Regime using the Rate Function
Jun 19, 2023



In this paper, we present a novel characterization of the smoothness of a model based on basic principles of Large Deviation Theory. In contrast to prior work, where the smoothness of a model is normally characterized by a real value (e.g., the weights' norm), we show that smoothness can be described by a simple real-valued function. Based on this concept of smoothness, we propose an unifying theoretical explanation of why some interpolators generalize remarkably well and why a wide range of modern learning techniques (i.e., stochastic gradient descent, $\ell_2$-norm regularization, data augmentation, invariant architectures, and overparameterization) are able to find them. The emergent conclusion is that all these methods provide complimentary procedures that bias the optimizer to smoother interpolators, which, according to this theoretical analysis, are the ones with better generalization error.
Variational Linearized Laplace Approximation for Bayesian Deep Learning
Feb 24, 2023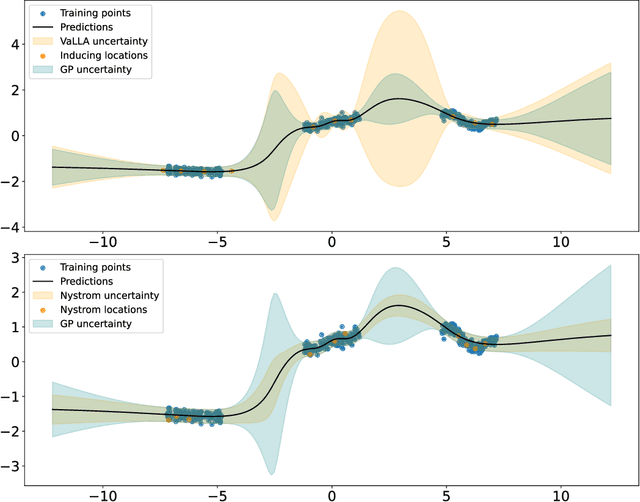
Pre-trained deep neural networks can be adapted to perform uncertainty estimation by transforming them into Bayesian neural networks via methods such as Laplace approximation (LA) or its linearized form (LLA), among others. To make these methods more tractable, the generalized Gauss-Newton (GGN) approximation is often used. However, due to complex inefficiency difficulties, both LA and LLA rely on further approximations, such as Kronecker-factored or diagonal approximate GGN matrices, which can affect the results. To address these issues, we propose a new method for scaling LLA using a variational sparse Gaussian Process (GP) approximation based on the dual RKHS of GPs. Our method retains the predictive mean of the original model while allowing for efficient stochastic optimization and scalability in both the number of parameters and the size of the training dataset. Moreover, its training cost is independent of the number of training points, improving over previously existing methods. Our preliminary experiments indicate that it outperforms already existing efficient variants of LLA, such as accelerated LLA (ELLA), based on the Nystr\"om approximation.
Correcting Model Bias with Sparse Implicit Processes
Aug 08, 2022
Model selection in machine learning (ML) is a crucial part of the Bayesian learning procedure. Model choice may impose strong biases on the resulting predictions, which can hinder the performance of methods such as Bayesian neural networks and neural samplers. On the other hand, newly proposed approaches for Bayesian ML exploit features of approximate inference in function space with implicit stochastic processes (a generalization of Gaussian processes). The approach of Sparse Implicit Processes (SIP) is particularly successful in this regard, since it is fully trainable and achieves flexible predictions. Here, we expand on the original experiments to show that SIP is capable of correcting model bias when the data generating mechanism differs strongly from the one implied by the model. We use synthetic datasets to show that SIP is capable of providing predictive distributions that reflect the data better than the exact predictions of the initial, but wrongly assumed model.