 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Linearized Laplace Approximation for Bayesian Deep Learning
Paper and Code
Feb 24, 2023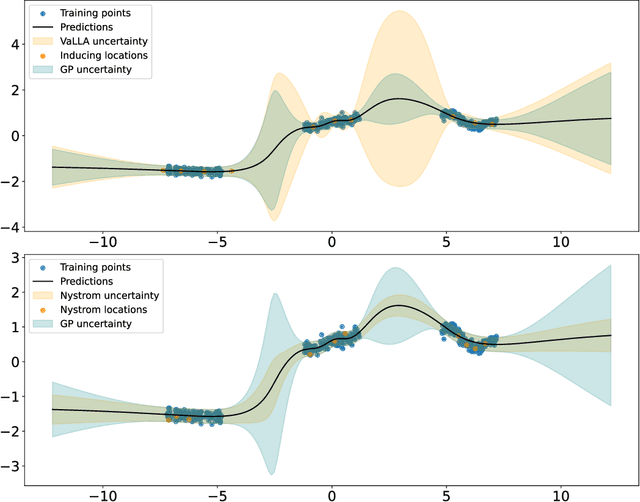
Pre-trained deep neural networks can be adapted to perform uncertainty estimation by transforming them into Bayesian neural networks via methods such as Laplace approximation (LA) or its linearized form (LLA), among others. To make these methods more tractable, the generalized Gauss-Newton (GGN) approximation is often used. However, due to complex inefficiency difficulties, both LA and LLA rely on further approximations, such as Kronecker-factored or diagonal approximate GGN matrices, which can affect the results. To address these issues, we propose a new method for scaling LLA using a variational sparse Gaussian Process (GP) approximation based on the dual RKHS of GPs. Our method retains the predictive mean of the original model while allowing for efficient stochastic optimization and scalability in both the number of parameters and the size of the training dataset. Moreover, its training cost is independent of the number of training points, improving over previously existing methods. Our preliminary experiments indicate that it outperforms already existing efficient variants of LLA, such as accelerated LLA (ELLA), based on the Nystr\"om approximation.