 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResearch Advances and New Paradigms for Biology-inspired Spiking Neural Networks
Aug 26, 2024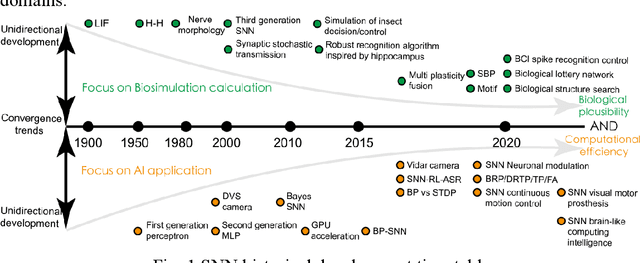


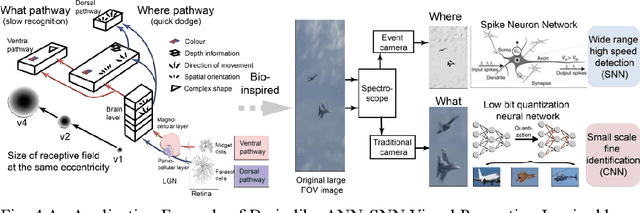
Spiking neural networks (SNNs) are gaining popularity in the computational simulation and artificial intelligence fields owing to their biological plausibility and computational efficiency. This paper explores the historical development of SNN and concludes that these two fields are intersecting and merging rapidly. Following the successful application of Dynamic Vision Sensors (DVS) and Dynamic Audio Sensors (DAS), SNNs have found some proper paradigms, such as continuous visual signal tracking, automatic speech recognition, and reinforcement learning for continuous control, that have extensively supported their key features, including spike encoding, neuronal heterogeneity, specific functional circuits, and multiscale plasticity. Compared to these real-world paradigms, the brain contains a spiking version of the biology-world paradigm, which exhibits a similar level of complexity and is usually considered a mirror of the real world. Considering the projected rapid development of invasive and parallel Brain-Computer Interface (BCI), as well as the new BCI-based paradigms that include online pattern recognition and stimulus control of biological spike trains, SNNs naturally leverage their advantages in energy efficiency, robustness, and flexibility. The biological brain has inspired the present study of SNNs and effective SNN machine-learning algorithms, which can help enhance neuroscience discoveries in the brain by applying them to the new BCI paradigm. Such two-way interactions with positive feedback can accelerate brain science research and brain-inspired intelligence technology.
A$^{3}$lign-DFER: Pioneering Comprehensive Dynamic Affective Alignment for Dynamic Facial Expression Recognition with CLIP
Mar 07, 2024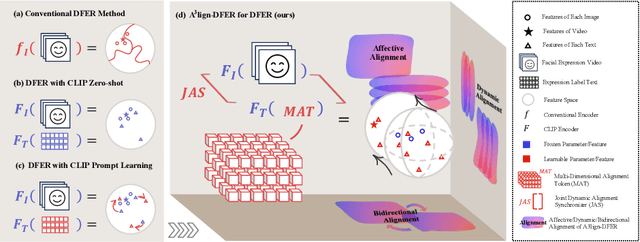
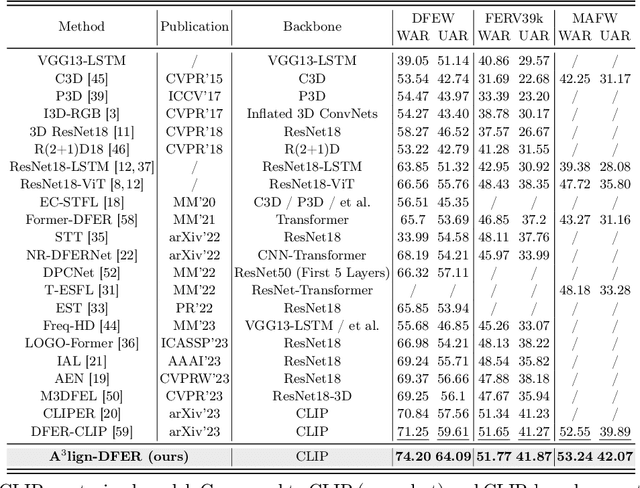
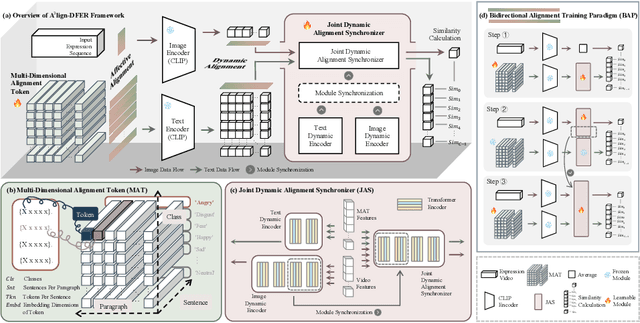
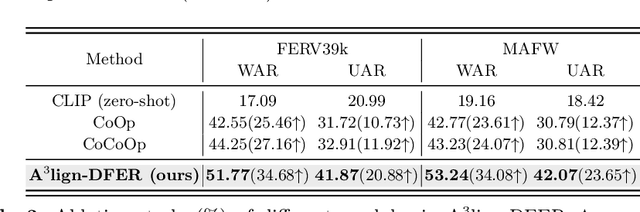
The performance of CLIP in dynamic facial expression recognition (DFER) task doesn't yield exceptional results as observed in other CLIP-based classification tasks. While CLIP's primary objective is to achieve alignment between images and text in the feature space, DFER poses challenges due to the abstract nature of text and the dynamic nature of video, making label representation limited and perfect alignment difficult. To address this issue, we have designed A$^{3}$lign-DFER, which introduces a new DFER labeling paradigm to comprehensively achieve alignment, thus enhancing CLIP's suitability for the DFER task. Specifically, our A$^{3}$lign-DFER method is designed with multiple modules that work together to obtain the most suitable expanded-dimensional embeddings for classification and to achieve alignment in three key aspects: affective, dynamic, and bidirectional. We replace the input label text with a learnable Multi-Dimensional Alignment Token (MAT), enabling alignment of text to facial expression video samples in both affective and dynamic dimensions. After CLIP feature extraction, we introduce the Joint Dynamic Alignment Synchronizer (JAS), further facilitating synchronization and alignment in the temporal dimension. Additionally, we implement a Bidirectional Alignment Training Paradigm (BAP) to ensure gradual and steady training of parameters for both modalities. Our insightful and concise A$^{3}$lign-DFER method achieves state-of-the-art results on multiple DFER datasets, including DFEW, FERV39k, and MAFW. Extensive ablation experiments and visualization studies demonstrate the effectiveness of A$^{3}$lign-DFER. The code will be available in the future.
ODE-based Recurrent Model-free Reinforcement Learning for POMDPs
Sep 25, 2023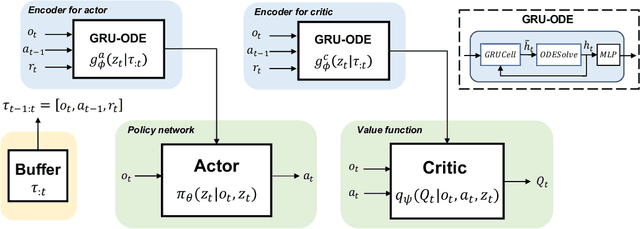
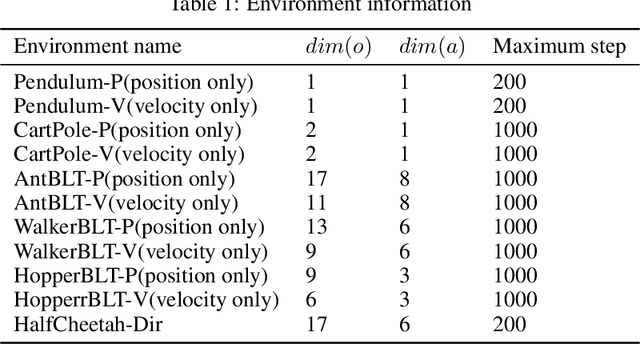
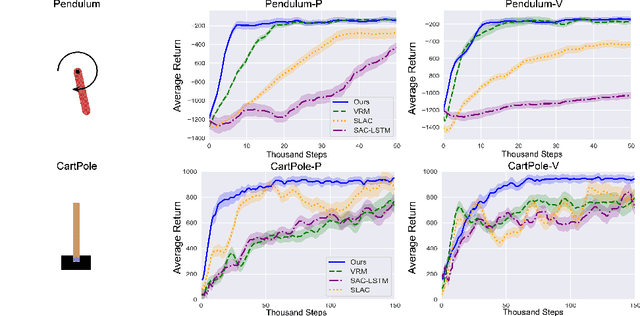
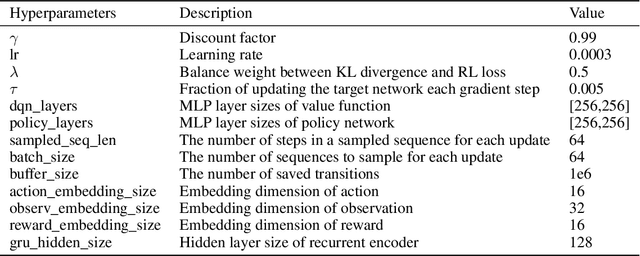
Neural ordinary differential equations (ODEs) are widely recognized as the standard for modeling physical mechanisms, which help to perform approximate inference in unknown physical or biological environments. In partially observable (PO) environments, how to infer unseen information from raw observations puzzled the agents. By using a recurrent policy with a compact context, context-based reinforcement learning provides a flexible way to extract unobservable information from historical transitions. To help the agent extract more dynamics-related information, we present a novel ODE-based recurrent model combines with model-free reinforcement learning (RL) framework to solve partially observable Markov decision processes (POMDPs). We experimentally demonstrate the efficacy of our methods across various PO continuous control and meta-RL tasks. Furthermore, our experiments illustrate that our method is robust against irregular observations, owing to the ability of ODEs to model irregularly-sampled time series.