 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussHDR: High Dynamic Range Gaussian Splatting via Learning Unified 3D and 2D Local Tone Mapping
Mar 13, 2025



High dynamic range (HDR) novel view synthesis (NVS) aims to reconstruct HDR scenes by leveraging multi-view low dynamic range (LDR) images captured at different exposure levels. Current training paradigms with 3D tone mapping often result in unstable HDR reconstruction, while training with 2D tone mapping reduces the model's capacity to fit LDR images. Additionally, the global tone mapper used in existing methods can impede the learning of both HDR and LDR representations. To address these challenges, we present GaussHDR, which unifies 3D and 2D local tone mapping through 3D Gaussian splatting. Specifically, we design a residual local tone mapper for both 3D and 2D tone mapping that accepts an additional context feature as input. We then propose combining the dual LDR rendering results from both 3D and 2D local tone mapping at the loss level. Finally, recognizing that different scenes may exhibit varying balances between the dual results, we introduce uncertainty learning and use the uncertainties for adaptive modulation. Extensive experiments demonstrate that GaussHDR significantly outperforms state-of-the-art methods in both synthetic and real-world scenarios.
SAFNet: Selective Alignment Fusion Network for Efficient HDR Imaging
Jul 23, 2024Multi-exposure High Dynamic Range (HDR) imaging is a challenging task when facing truncated texture and complex motion. Existing deep learning-based methods have achieved great success by either following the alignment and fusion pipeline or utilizing attention mechanism. However, the large computation cost and inference delay hinder them from deploying on resource limited devices. In this paper, to achieve better efficiency, a novel Selective Alignment Fusion Network (SAFNet) for HDR imaging is proposed. After extracting pyramid features, it jointly refines valuable area masks and cross-exposure motion in selected regions with shared decoders, and then fuses high quality HDR image in an explicit way. This approach can focus the model on finding valuable regions while estimating their easily detectable and meaningful motion. For further detail enhancement, a lightweight refine module is introduced which enjoys privileges from previous optical flow, selection masks and initial prediction. Moreover, to facilitate learning on samples with large motion, a new window partition cropping method is presented during training. Experiments on public and newly developed challenging datasets show that proposed SAFNet not only exceeds previous SOTA competitors quantitatively and qualitatively, but also runs order of magnitude faster. Code and dataset is available at https://github.com/ltkong218/SAFNet.
Mono-ViFI: A Unified Learning Framework for Self-supervised Single- and Multi-frame Monocular Depth Estimation
Jul 19, 2024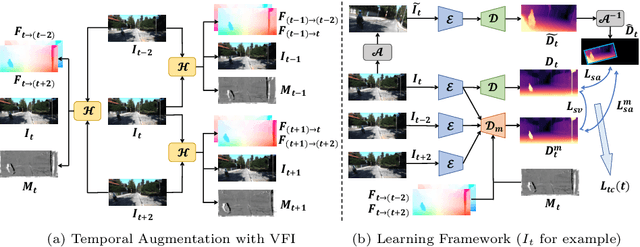
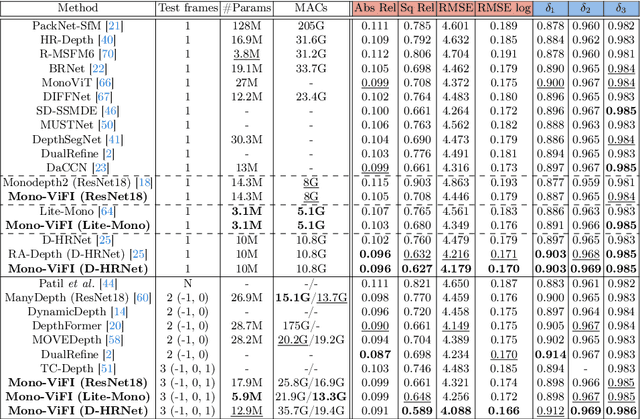
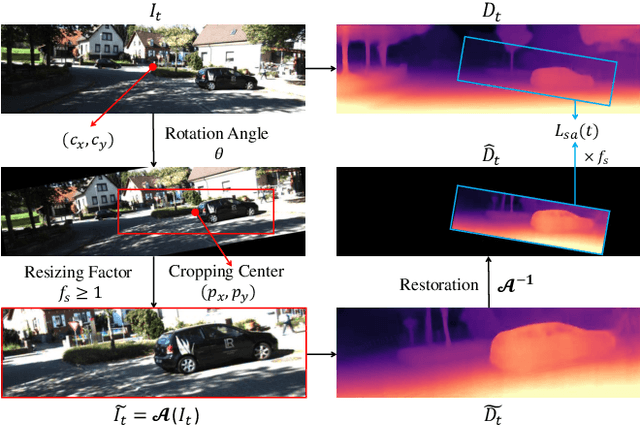
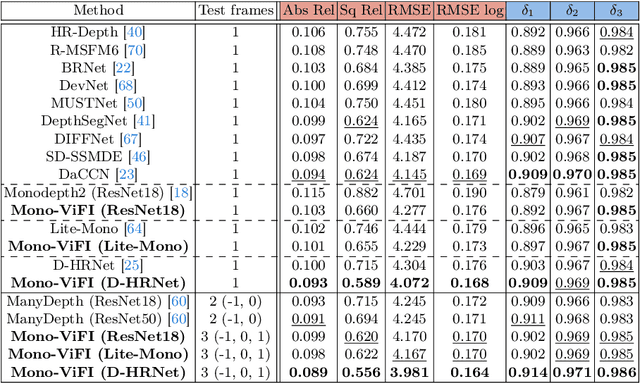
Self-supervised monocular depth estimation has gathered notable interest since it can liberate training from dependency on depth annotations. In monocular video training case, recent methods only conduct view synthesis between existing camera views, leading to insufficient guidance. To tackle this, we try to synthesize more virtual camera views by flow-based video frame interpolation (VFI), termed as temporal augmentation. For multi-frame inference, to sidestep the problem of dynamic objects encountered by explicit geometry-based methods like ManyDepth, we return to the feature fusion paradigm and design a VFI-assisted multi-frame fusion module to align and aggregate multi-frame features, using motion and occlusion information obtained by the flow-based VFI model. Finally, we construct a unified self-supervised learning framework, named Mono-ViFI, to bilaterally connect single- and multi-frame depth. In this framework, spatial data augmentation through image affine transformation is incorporated for data diversity, along with a triplet depth consistency loss for regularization. The single- and multi-frame models can share weights, making our framework compact and memory-efficient. Extensive experiments demonstrate that our method can bring significant improvements to current advanced architectures. Source code is available at https://github.com/LiuJF1226/Mono-ViFI.
Dynamic Frame Interpolation in Wavelet Domain
Sep 21, 2023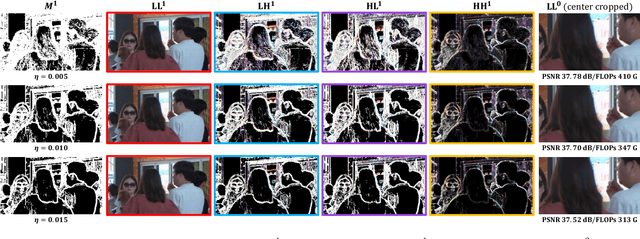

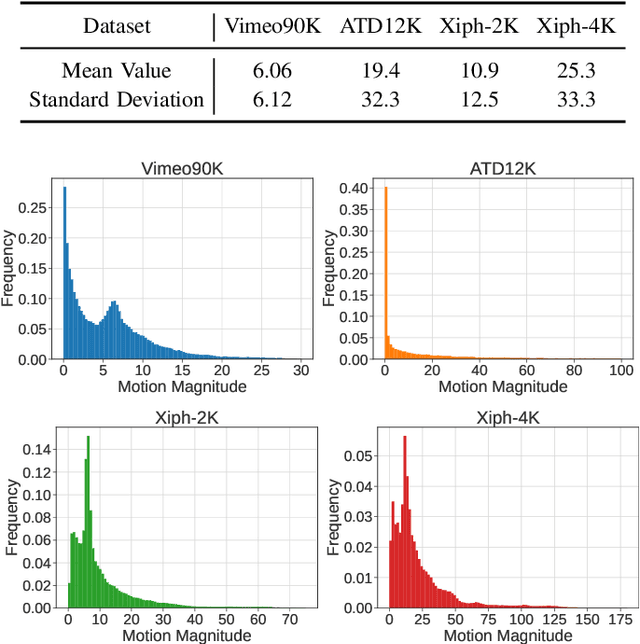

Video frame interpolation is an important low-level vision task, which can increase frame rate for more fluent visual experience. Existing methods have achieved great success by employing advanced motion models and synthesis networks. However, the spatial redundancy when synthesizing the target frame has not been fully explored, that can result in lots of inefficient computation. On the other hand, the computation compression degree in frame interpolation is highly dependent on both texture distribution and scene motion, which demands to understand the spatial-temporal information of each input frame pair for a better compression degree selection. In this work, we propose a novel two-stage frame interpolation framework termed WaveletVFI to address above problems. It first estimates intermediate optical flow with a lightweight motion perception network, and then a wavelet synthesis network uses flow aligned context features to predict multi-scale wavelet coefficients with sparse convolution for efficient target frame reconstruction, where the sparse valid masks that control computation in each scale are determined by a crucial threshold ratio. Instead of setting a fixed value like previous methods, we find that embedding a classifier in the motion perception network to learn a dynamic threshold for each sample can achieve more computation reduction with almost no loss of accuracy. On the common high resolution and animation frame interpolation benchmarks, proposed WaveletVFI can reduce computation up to 40% while maintaining similar accuracy, making it perform more efficiently against other state-of-the-arts. Code is available at https://github.com/ltkong218/WaveletVFI.
Towards Better Data Exploitation In Self-Supervised Monocular Depth Estimation
Sep 11, 2023



Depth estimation plays an important role in the robotic perception system. Self-supervised monocular paradigm has gained significant attention since it can free training from the reliance on depth annotations. Despite recent advancements, existing self-supervised methods still underutilize the available training data, limiting their generalization ability. In this paper, we take two data augmentation techniques, namely Resizing-Cropping and Splitting-Permuting, to fully exploit the potential of training datasets. Specifically, the original image and the generated two augmented images are fed into the training pipeline simultaneously and we leverage them to conduct self-distillation. Additionally, we introduce the detail-enhanced DepthNet with an extra full-scale branch in the encoder and a grid decoder to enhance the restoration of fine details in depth maps. Experimental results demonstrate our method can achieve state-of-the-art performance on the KITTI benchmark, with both raw ground truth and improved ground truth. Moreover, our models also show superior generalization performance when transferring to Make3D and NYUv2 datasets. Our codes are available at https://github.com/Sauf4896/BDEdepth.
Progressive Motion Context Refine Network for Efficient Video Frame Interpolation
Nov 11, 2022Recently, flow-based frame interpolation methods have achieved great success by first modeling optical flow between target and input frames, and then building synthesis network for target frame generation. However, above cascaded architecture can lead to large model size and inference delay, hindering them from mobile and real-time applications. To solve this problem, we propose a novel Progressive Motion Context Refine Network (PMCRNet) to predict motion fields and image context jointly for higher efficiency. Different from others that directly synthesize target frame from deep feature, we explore to simplify frame interpolation task by borrowing existing texture from adjacent input frames, which means that decoder in each pyramid level of our PMCRNet only needs to update easier intermediate optical flow, occlusion merge mask and image residual. Moreover, we introduce a new annealed multi-scale reconstruction loss to better guide the learning process of this efficient PMCRNet. Experiments on multiple benchmarks show that proposed approaches not only achieve favorable quantitative and qualitative results but also reduces current model size and running time significantly.
MDFlow: Unsupervised Optical Flow Learning by Reliable Mutual Knowledge Distillation
Nov 11, 2022Recent works have shown that optical flow can be learned by deep networks from unlabelled image pairs based on brightness constancy assumption and smoothness prior. Current approaches additionally impose an augmentation regularization term for continual self-supervision, which has been proved to be effective on difficult matching regions. However, this method also amplify the inevitable mismatch in unsupervised setting, blocking the learning process towards optimal solution. To break the dilemma, we propose a novel mutual distillation framework to transfer reliable knowledge back and forth between the teacher and student networks for alternate improvement. Concretely, taking estimation of off-the-shelf unsupervised approach as pseudo labels, our insight locates at defining a confidence selection mechanism to extract relative good matches, and then add diverse data augmentation for distilling adequate and reliable knowledge from teacher to student. Thanks to the decouple nature of our method, we can choose a stronger student architecture for sufficient learning. Finally, better student prediction is adopted to transfer knowledge back to the efficient teacher without additional costs in real deployment. Rather than formulating it as a supervised task, we find that introducing an extra unsupervised term for multi-target learning achieves best final results. Extensive experiments show that our approach, termed MDFlow, achieves state-of-the-art real-time accuracy and generalization ability on challenging benchmarks. Code is available at https://github.com/ltkong218/MDFlow.
ATCA: an Arc Trajectory Based Model with Curvature Attention for Video Frame Interpolation
Aug 01, 2022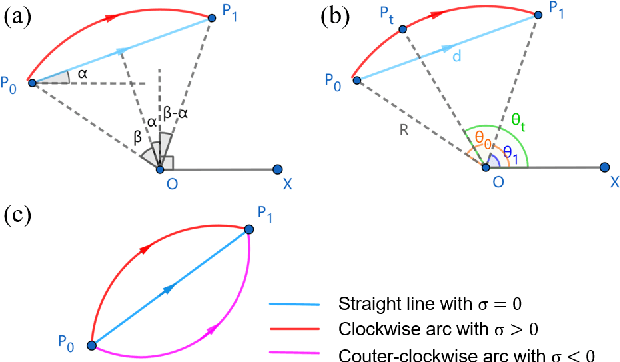
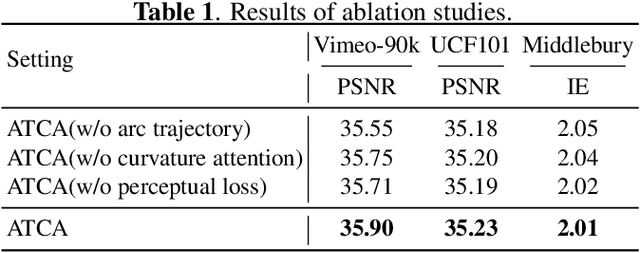
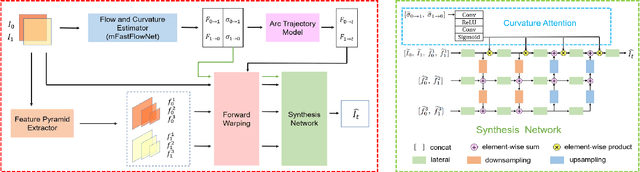
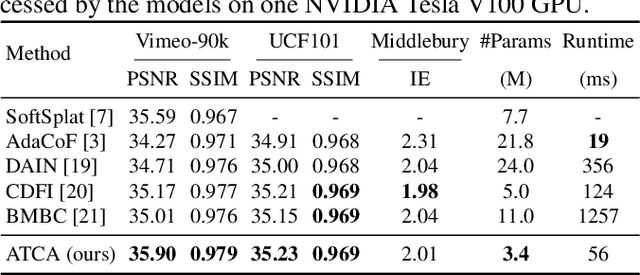
Video frame interpolation is a classic and challenging low-level computer vision task. Recently, deep learning based methods have achieved impressive results, and it has been proven that optical flow based methods can synthesize frames with higher quality. However, most flow-based methods assume a line trajectory with a constant velocity between two input frames. Only a little work enforces predictions with curvilinear trajectory, but this requires more than two frames as input to estimate the acceleration, which takes more time and memory to execute. To address this problem, we propose an arc trajectory based model (ATCA), which learns motion prior from only two consecutive frames and also is lightweight. Experiments show that our approach performs better than many SOTA methods with fewer parameters and faster inference speed.
IFRNet: Intermediate Feature Refine Network for Efficient Frame Interpolation
May 29, 2022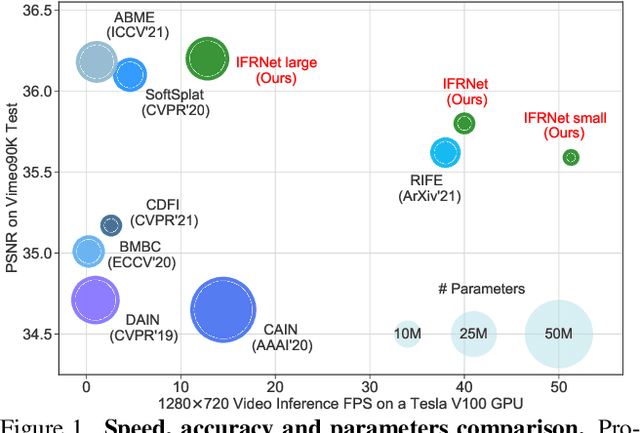
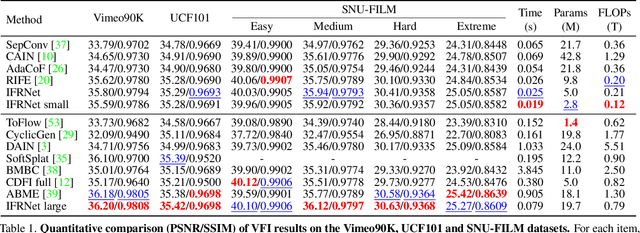

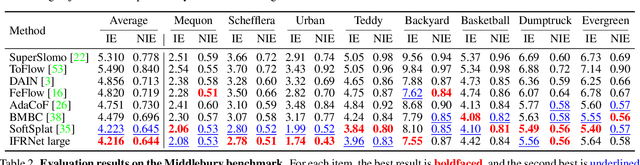
Prevailing video frame interpolation algorithms, that generate the intermediate frames from consecutive inputs, typically rely on complex model architectures with heavy parameters or large delay, hindering them from diverse real-time applications. In this work, we devise an efficient encoder-decoder based network, termed IFRNet, for fast intermediate frame synthesizing. It first extracts pyramid features from given inputs, and then refines the bilateral intermediate flow fields together with a powerful intermediate feature until generating the desired output. The gradually refined intermediate feature can not only facilitate intermediate flow estimation, but also compensate for contextual details, making IFRNet do not need additional synthesis or refinement module. To fully release its potential, we further propose a novel task-oriented optical flow distillation loss to focus on learning the useful teacher knowledge towards frame synthesizing. Meanwhile, a new geometry consistency regularization term is imposed on the gradually refined intermediate features to keep better structure layout. Experiments on various benchmarks demonstrate the excellent performance and fast inference speed of proposed approaches. Code is available at https://github.com/ltkong218/IFRNet.
FastFlowNet: A Lightweight Network for Fast Optical Flow Estimation
Mar 21, 2021
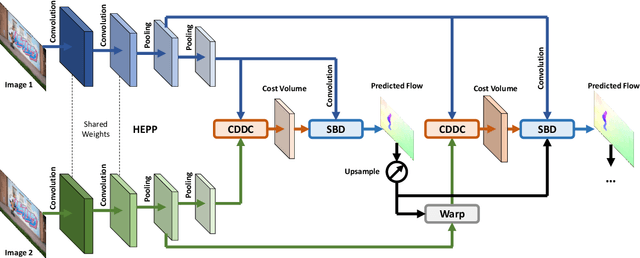
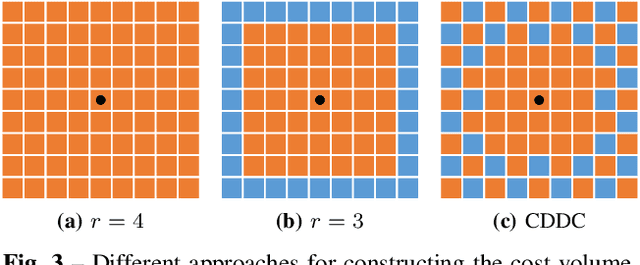
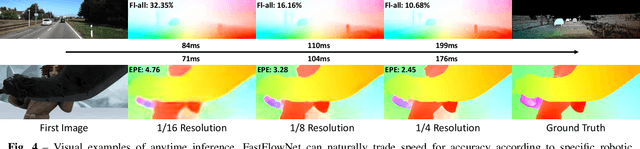
Dense optical flow estimation plays a key role in many robotic vision tasks. In the past few years, with the advent of deep learning, we have witnessed great progress in optical flow estimation. However, current networks often consist of a large number of parameters and require heavy computation costs, largely hindering its application on low power-consumption devices such as mobile phones. In this paper, we tackle this challenge and design a lightweight model for fast and accurate optical flow prediction. Our proposed FastFlowNet follows the widely-used coarse-to-fine paradigm with following innovations. First, a new head enhanced pooling pyramid (HEPP) feature extractor is employed to intensify high-resolution pyramid features while reducing parameters. Second, we introduce a new center dense dilated correlation (CDDC) layer for constructing compact cost volume that can keep large search radius with reduced computation burden. Third, an efficient shuffle block decoder (SBD) is implanted into each pyramid level to accelerate flow estimation with marginal drops in accuracy. Experiments on both synthetic Sintel data and real-world KITTI datasets demonstrate the effectiveness of the proposed approach, which needs only 1/10 computation of comparable networks to achieve on par accuracy. In particular, FastFlowNet only contains 1.37M parameters; and can execute at 90 FPS (with a single GTX 1080Ti) or 5.7 FPS (embedded Jetson TX2 GPU) on a pair of Sintel images of resolution 1024x436.