 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCDEMapper: Enhancing NIH Common Data Element Normalization using Large Language Models
Nov 30, 2024Common Data Elements (CDEs) standardize data collection and sharing across studies, enhancing data interoperability and improving research reproducibility. However, implementing CDEs presents challenges due to the broad range and variety of data elements. This study aims to develop an effective and efficient mapping tool to bridge the gap between local data elements and National Institutes of Health (NIH) CDEs. We propose CDEMapper, a large language model (LLM) powered mapping tool designed to assist in mapping local data elements to NIH CDEs. CDEMapper has three core modules: (1) CDE indexing and embeddings. NIH CDEs were indexed and embedded to support semantic search; (2) CDE recommendations. The tool combines Elasticsearch (BM25 similarity methods) with state of the art GPT services to recommend candidate CDEs and their permissible values; and (3) Human review. Users review and select the NIH CDEs and values that best match their data elements and value sets. We evaluate the tool recommendation accuracy against manually annotated mapping results. CDEMapper offers a publicly available, LLM-powered, and intuitive user interface that consolidates essential and advanced mapping services into a streamlined pipeline. It provides a step by step, quality assured mapping workflow designed with a user-centered approach. The evaluation results demonstrated that augmenting BM25 with GPT embeddings and a ranker consistently enhances CDEMapper mapping accuracy in three different mapping settings across four evaluation datasets. This work opens up the potential of using LLMs to assist with CDE recommendation and human curation when aligning local data elements with NIH CDEs. Additionally, this effort enhances clinical research data interoperability and helps researchers better understand the gaps between local data elements and NIH CDEs.
A Comparative Study of Recent Large Language Models on Generating Hospital Discharge Summaries for Lung Cancer Patients
Nov 06, 2024


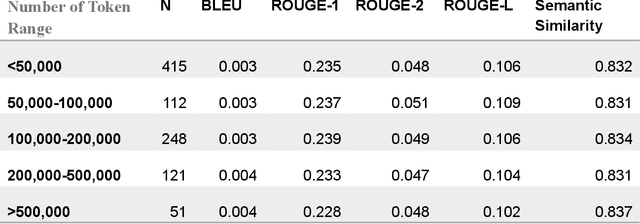
Generating discharge summaries is a crucial yet time-consuming task in clinical practice, essential for conveying pertinent patient information and facilitating continuity of care. Recent advancements in large language models (LLMs) have significantly enhanced their capability in understanding and summarizing complex medical texts. This research aims to explore how LLMs can alleviate the burden of manual summarization, streamline workflow efficiencies, and support informed decision-making in healthcare settings. Clinical notes from a cohort of 1,099 lung cancer patients were utilized, with a subset of 50 patients for testing purposes, and 102 patients used for model fine-tuning. This study evaluates the performance of multiple LLMs, including GPT-3.5, GPT-4, GPT-4o, and LLaMA 3 8b, in generating discharge summaries. Evaluation metrics included token-level analysis (BLEU, ROUGE-1, ROUGE-2, ROUGE-L) and semantic similarity scores between model-generated summaries and physician-written gold standards. LLaMA 3 8b was further tested on clinical notes of varying lengths to examine the stability of its performance. The study found notable variations in summarization capabilities among LLMs. GPT-4o and fine-tuned LLaMA 3 demonstrated superior token-level evaluation metrics, while LLaMA 3 consistently produced concise summaries across different input lengths. Semantic similarity scores indicated GPT-4o and LLaMA 3 as leading models in capturing clinical relevance. This study contributes insights into the efficacy of LLMs for generating discharge summaries, highlighting LLaMA 3's robust performance in maintaining clarity and relevance across varying clinical contexts. These findings underscore the potential of automated summarization tools to enhance documentation precision and efficiency, ultimately improving patient care and operational capability in healthcare settings.
Application of an ontology for model cards to generate computable artifacts for linking machine learning information from biomedical research
Mar 21, 2023



Model card reports provide a transparent description of machine learning models which includes information about their evaluation, limitations, intended use, etc. Federal health agencies have expressed an interest in model cards report for research studies using machine-learning based AI. Previously, we have developed an ontology model for model card reports to structure and formalize these reports. In this paper, we demonstrate a Java-based library (OWL API, FaCT++) that leverages our ontology to publish computable model card reports. We discuss future directions and other use cases that highlight applicability and feasibility of ontology-driven systems to support FAIR challenges.