 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of Recent Large Language Models on Generating Hospital Discharge Summaries for Lung Cancer Patients
Paper and Code
Nov 06, 2024


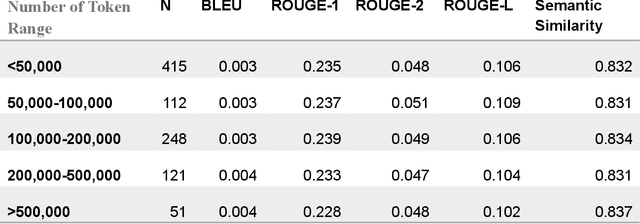
Generating discharge summaries is a crucial yet time-consuming task in clinical practice, essential for conveying pertinent patient information and facilitating continuity of care. Recent advancements in large language models (LLMs) have significantly enhanced their capability in understanding and summarizing complex medical texts. This research aims to explore how LLMs can alleviate the burden of manual summarization, streamline workflow efficiencies, and support informed decision-making in healthcare settings. Clinical notes from a cohort of 1,099 lung cancer patients were utilized, with a subset of 50 patients for testing purposes, and 102 patients used for model fine-tuning. This study evaluates the performance of multiple LLMs, including GPT-3.5, GPT-4, GPT-4o, and LLaMA 3 8b, in generating discharge summaries. Evaluation metrics included token-level analysis (BLEU, ROUGE-1, ROUGE-2, ROUGE-L) and semantic similarity scores between model-generated summaries and physician-written gold standards. LLaMA 3 8b was further tested on clinical notes of varying lengths to examine the stability of its performance. The study found notable variations in summarization capabilities among LLMs. GPT-4o and fine-tuned LLaMA 3 demonstrated superior token-level evaluation metrics, while LLaMA 3 consistently produced concise summaries across different input lengths. Semantic similarity scores indicated GPT-4o and LLaMA 3 as leading models in capturing clinical relevance. This study contributes insights into the efficacy of LLMs for generating discharge summaries, highlighting LLaMA 3's robust performance in maintaining clarity and relevance across varying clinical contexts. These findings underscore the potential of automated summarization tools to enhance documentation precision and efficiency, ultimately improving patient care and operational capability in healthcare settings.