 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedHQ: Hybrid Runtime Quantization for Federated Learning
May 17, 2025Federated Learning (FL) is a decentralized model training approach that preserves data privacy but struggles with low efficiency. Quantization, a powerful training optimization technique, has been widely explored for integration into FL. However, many studies fail to consider the distinct performance attribution between particular quantization strategies, such as post-training quantization (PTQ) or quantization-aware training (QAT). As a result, existing FL quantization methods rely solely on either PTQ or QAT, optimizing for speed or accuracy while compromising the other. To efficiently accelerate FL and maintain distributed convergence accuracy across various FL settings, this paper proposes a hybrid quantitation approach combining PTQ and QAT for FL systems. We conduct case studies to validate the effectiveness of using hybrid quantization in FL. To solve the difficulty of modeling speed and accuracy caused by device and data heterogeneity, we propose a hardware-related analysis and data-distribution-related analysis to help identify the trade-off boundaries for strategy selection. Based on these, we proposed a novel framework named FedHQ to automatically adopt optimal hybrid strategy allocation for FL systems. Specifically, FedHQ develops a coarse-grained global initialization and fine-grained ML-based adjustment to ensure efficiency and robustness. Experiments show that FedHQ achieves up to 2.47x times training acceleration and up to 11.15% accuracy improvement and negligible extra overhead.
MoQa: Rethinking MoE Quantization with Multi-stage Data-model Distribution Awareness
Mar 27, 2025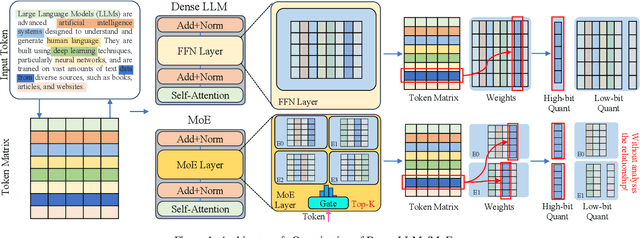
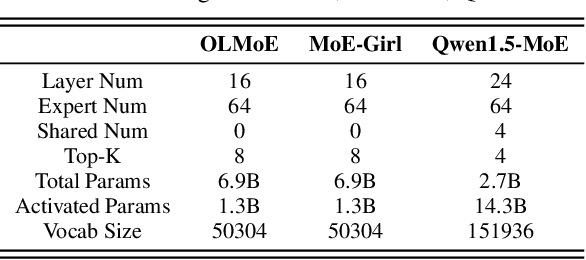

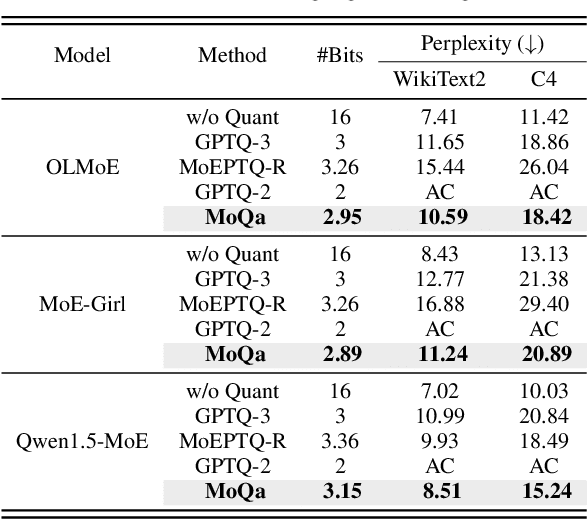
With the advances in artificial intelligence, Mix-of-Experts (MoE) has become the main form of Large Language Models (LLMs), and its demand for model compression is increasing. Quantization is an effective method that not only compresses the models but also significantly accelerates their performance. Existing quantization methods have gradually shifted the focus from parameter scaling to the analysis of data distributions. However, their analysis is designed for dense LLMs and relies on the simple one-model-all-data mapping, which is unsuitable for MoEs. This paper proposes a new quantization framework called MoQa. MoQa decouples the data-model distribution complexity of MoEs in multiple analysis stages, quantitively revealing the dynamics during sparse data activation, data-parameter mapping, and inter-expert correlations. Based on these, MoQa identifies particular experts' and parameters' significance with optimal data-model distribution awareness and proposes a series of fine-grained mix-quantization strategies adaptive to various data activation and expert combination scenarios. Moreover, MoQa discusses the limitations of existing quantization and analyzes the impact of each stage analysis, showing novel insights for MoE quantization. Experiments show that MoQa achieves a 1.69~2.18 perplexity decrease in language modeling tasks and a 1.58%~8.91% accuracy improvement in zero-shot inference tasks. We believe MoQa will play a role in future MoE construction, optimization, and compression.
OriGen:Enhancing RTL Code Generation with Code-to-Code Augmentation and Self-Reflection
Jul 23, 2024Recent studies have illuminated that Large Language Models (LLMs) exhibit substantial potential in the realm of RTL (Register Transfer Level) code generation, with notable advancements evidenced by commercial models such as GPT-4 and Claude3-Opus. Despite their proficiency, these commercial LLMs often raise concerns regarding privacy and security. Conversely, open-source LLMs, which offer solutions to these concerns, have inferior performance in RTL code generation tasks to commercial models due to the lack of highquality open-source RTL datasets. To address this issue, we introduce OriGen, a fully open-source framework featuring self-reflection capabilities and a dataset augmentation methodology for generating high-quality, large-scale RTL code. We propose a novel code-to-code augmentation methodology that leverages knowledge distillation to enhance the quality of the open-source RTL code datasets. Additionally, OriGen is capable of correcting syntactic errors by leveraging a self-reflection process based on feedback from the compiler. The self-reflection ability of the model is facilitated by a carefully constructed dataset, which comprises a comprehensive collection of samples. Experimental results demonstrate that OriGen remarkably outperforms other open-source alternatives in RTL code generation, surpassing the previous best-performing LLM by 9.8% on the VerilogEval-Human benchmark. Furthermore, OriGen exhibits superior capabilities in self-reflection and error rectification, surpassing GPT-4 by 18.1% on the benchmark designed to evaluate the capability of self-reflection.