 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoQa: Rethinking MoE Quantization with Multi-stage Data-model Distribution Awareness
Paper and Code
Mar 27, 2025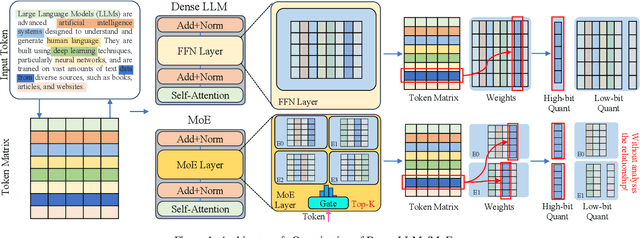
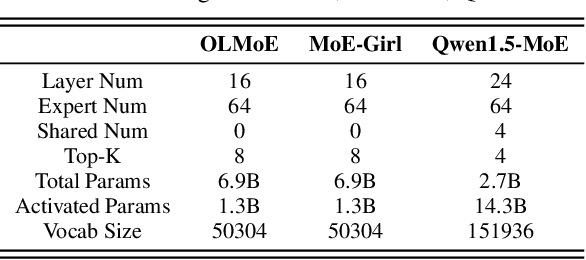

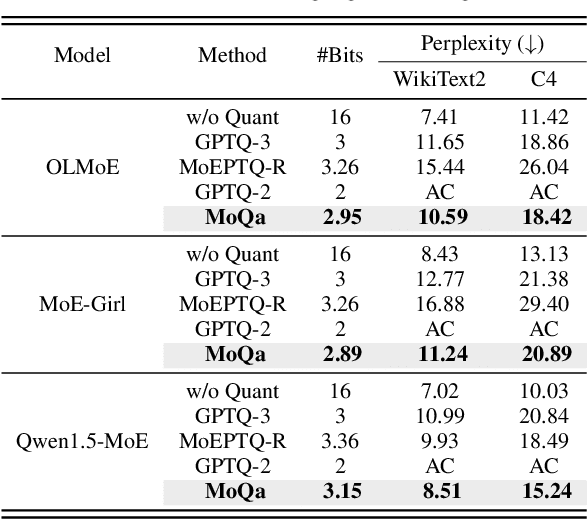
With the advances in artificial intelligence, Mix-of-Experts (MoE) has become the main form of Large Language Models (LLMs), and its demand for model compression is increasing. Quantization is an effective method that not only compresses the models but also significantly accelerates their performance. Existing quantization methods have gradually shifted the focus from parameter scaling to the analysis of data distributions. However, their analysis is designed for dense LLMs and relies on the simple one-model-all-data mapping, which is unsuitable for MoEs. This paper proposes a new quantization framework called MoQa. MoQa decouples the data-model distribution complexity of MoEs in multiple analysis stages, quantitively revealing the dynamics during sparse data activation, data-parameter mapping, and inter-expert correlations. Based on these, MoQa identifies particular experts' and parameters' significance with optimal data-model distribution awareness and proposes a series of fine-grained mix-quantization strategies adaptive to various data activation and expert combination scenarios. Moreover, MoQa discusses the limitations of existing quantization and analyzes the impact of each stage analysis, showing novel insights for MoE quantization. Experiments show that MoQa achieves a 1.69~2.18 perplexity decrease in language modeling tasks and a 1.58%~8.91% accuracy improvement in zero-shot inference tasks. We believe MoQa will play a role in future MoE construction, optimization, and compression.