 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDINO-X: A Unified Vision Model for Open-World Object Detection and Understanding
Nov 21, 2024



In this paper, we introduce DINO-X, which is a unified object-centric vision model developed by IDEA Research with the best open-world object detection performance to date. DINO-X employs the same Transformer-based encoder-decoder architecture as Grounding DINO 1.5 to pursue an object-level representation for open-world object understanding. To make long-tailed object detection easy, DINO-X extends its input options to support text prompt, visual prompt, and customized prompt. With such flexible prompt options, we develop a universal object prompt to support prompt-free open-world detection, making it possible to detect anything in an image without requiring users to provide any prompt. To enhance the model's core grounding capability, we have constructed a large-scale dataset with over 100 million high-quality grounding samples, referred to as Grounding-100M, for advancing the model's open-vocabulary detection performance. Pre-training on such a large-scale grounding dataset leads to a foundational object-level representation, which enables DINO-X to integrate multiple perception heads to simultaneously support multiple object perception and understanding tasks, including detection, segmentation, pose estimation, object captioning, object-based QA, etc. Experimental results demonstrate the superior performance of DINO-X. Specifically, the DINO-X Pro model achieves 56.0 AP, 59.8 AP, and 52.4 AP on the COCO, LVIS-minival, and LVIS-val zero-shot object detection benchmarks, respectively. Notably, it scores 63.3 AP and 56.5 AP on the rare classes of LVIS-minival and LVIS-val benchmarks, both improving the previous SOTA performance by 5.8 AP. Such a result underscores its significantly improved capacity for recognizing long-tailed objects.
Grounding DINO 1.5: Advance the "Edge" of Open-Set Object Detection
May 16, 2024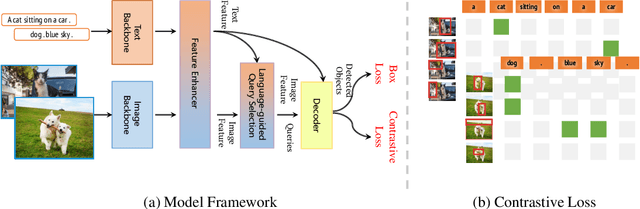
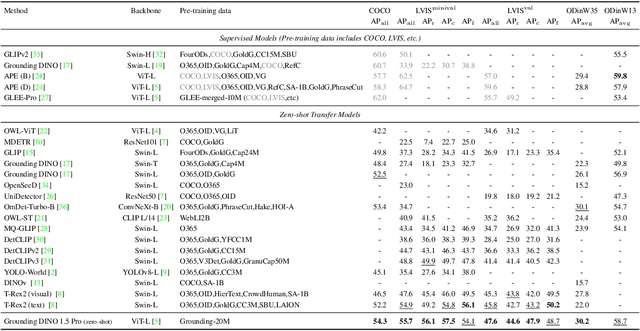
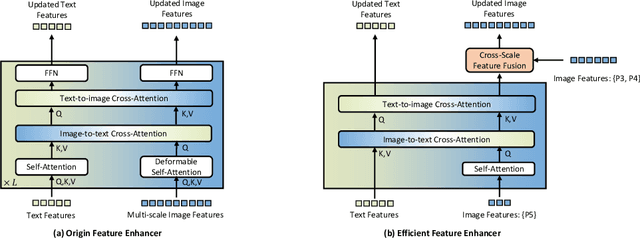

This paper introduces Grounding DINO 1.5, a suite of advanced open-set object detection models developed by IDEA Research, which aims to advance the "Edge" of open-set object detection. The suite encompasses two models: Grounding DINO 1.5 Pro, a high-performance model designed for stronger generalization capability across a wide range of scenarios, and Grounding DINO 1.5 Edge, an efficient model optimized for faster speed demanded in many applications requiring edge deployment. The Grounding DINO 1.5 Pro model advances its predecessor by scaling up the model architecture, integrating an enhanced vision backbone, and expanding the training dataset to over 20 million images with grounding annotations, thereby achieving a richer semantic understanding. The Grounding DINO 1.5 Edge model, while designed for efficiency with reduced feature scales, maintains robust detection capabilities by being trained on the same comprehensive dataset. Empirical results demonstrate the effectiveness of Grounding DINO 1.5, with the Grounding DINO 1.5 Pro model attaining a 54.3 AP on the COCO detection benchmark and a 55.7 AP on the LVIS-minival zero-shot transfer benchmark, setting new records for open-set object detection. Furthermore, the Grounding DINO 1.5 Edge model, when optimized with TensorRT, achieves a speed of 75.2 FPS while attaining a zero-shot performance of 36.2 AP on the LVIS-minival benchmark, making it more suitable for edge computing scenarios. Model examples and demos with API will be released at https://github.com/IDEA-Research/Grounding-DINO-1.5-API
T-Rex: Counting by Visual Prompting
Nov 22, 2023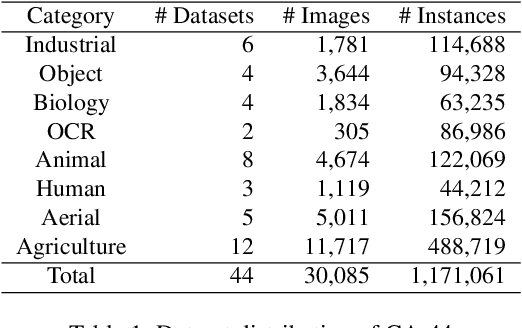

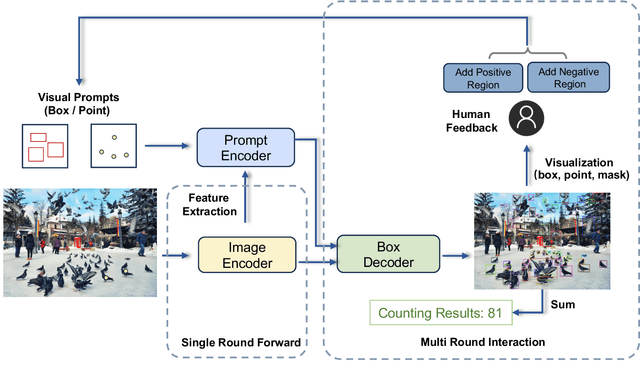
We introduce T-Rex, an interactive object counting model designed to first detect and then count any objects. We formulate object counting as an open-set object detection task with the integration of visual prompts. Users can specify the objects of interest by marking points or boxes on a reference image, and T-Rex then detects all objects with a similar pattern. Guided by the visual feedback from T-Rex, users can also interactively refine the counting results by prompting on missing or falsely-detected objects. T-Rex has achieved state-of-the-art performance on several class-agnostic counting benchmarks. To further exploit its potential, we established a new counting benchmark encompassing diverse scenarios and challenges. Both quantitative and qualitative results show that T-Rex possesses exceptional zero-shot counting capabilities. We also present various practical application scenarios for T-Rex, illustrating its potential in the realm of visual prompting.