 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGetting aligned on representational alignment
Nov 02, 2023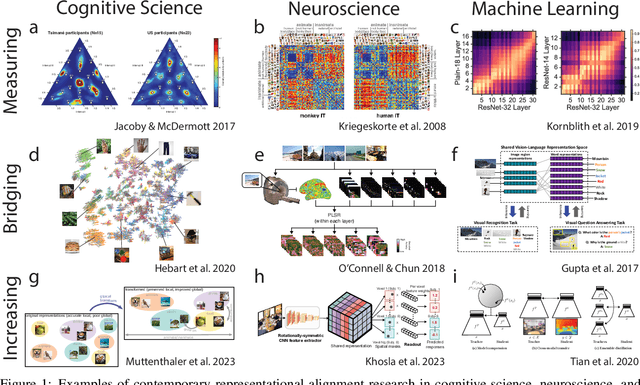
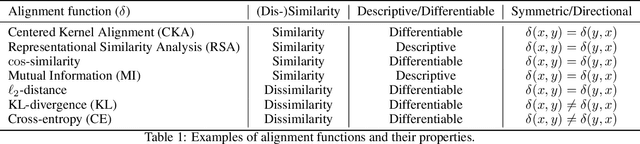
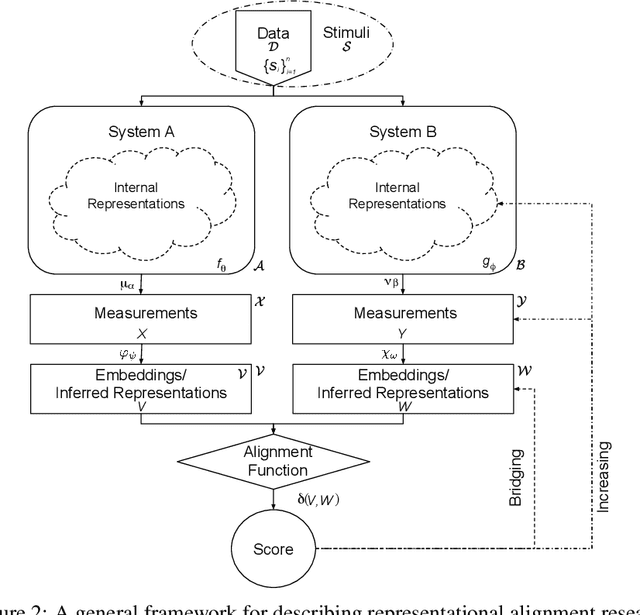
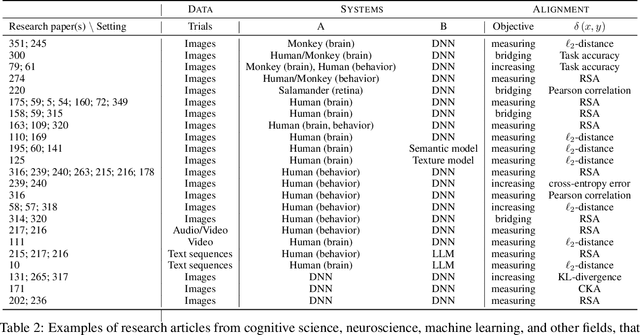
Biological and artificial information processing systems form representations that they can use to categorize, reason, plan, navigate, and make decisions. How can we measure the extent to which the representations formed by these diverse systems agree? Do similarities in representations then translate into similar behavior? How can a system's representations be modified to better match those of another system? These questions pertaining to the study of representational alignment are at the heart of some of the most active research areas in cognitive science, neuroscience, and machine learning. For example, cognitive scientists measure the representational alignment of multiple individuals to identify shared cognitive priors, neuroscientists align fMRI responses from multiple individuals into a shared representational space for group-level analyses, and ML researchers distill knowledge from teacher models into student models by increasing their alignment. Unfortunately, there is limited knowledge transfer between research communities interested in representational alignment, so progress in one field often ends up being rediscovered independently in another. Thus, greater cross-field communication would be advantageous. To improve communication between these fields, we propose a unifying framework that can serve as a common language between researchers studying representational alignment. We survey the literature from all three fields and demonstrate how prior work fits into this framework. Finally, we lay out open problems in representational alignment where progress can benefit all three of these fields. We hope that our work can catalyze cross-disciplinary collaboration and accelerate progress for all communities studying and developing information processing systems. We note that this is a working paper and encourage readers to reach out with their suggestions for future revisions.
On the Foundations of Shortcut Learning
Oct 24, 2023



Deep-learning models can extract a rich assortment of features from data. Which features a model uses depends not only on predictivity-how reliably a feature indicates train-set labels-but also on availability-how easily the feature can be extracted, or leveraged, from inputs. The literature on shortcut learning has noted examples in which models privilege one feature over another, for example texture over shape and image backgrounds over foreground objects. Here, we test hypotheses about which input properties are more available to a model, and systematically study how predictivity and availability interact to shape models' feature use. We construct a minimal, explicit generative framework for synthesizing classification datasets with two latent features that vary in predictivity and in factors we hypothesize to relate to availability, and quantify a model's shortcut bias-its over-reliance on the shortcut (more available, less predictive) feature at the expense of the core (less available, more predictive) feature. We find that linear models are relatively unbiased, but introducing a single hidden layer with ReLU or Tanh units yields a bias. Our empirical findings are consistent with a theoretical account based on Neural Tangent Kernels. Finally, we study how models used in practice trade off predictivity and availability in naturalistic datasets, discovering availability manipulations which increase models' degree of shortcut bias. Taken together, these findings suggest that the propensity to learn shortcut features is a fundamental characteristic of deep nonlinear architectures warranting systematic study given its role in shaping how models solve tasks.
What shapes feature representations? Exploring datasets, architectures, and training
Jun 22, 2020
In naturalistic learning problems, a model's input contains a wide range of features, some useful for the task at hand, and others not. Of the useful features, which ones does the model use? Of the task-irrelevant features, which ones does the model represent? Answers to these questions are important for understanding the basis of models' decisions, for example to ensure they are equitable and unbiased, as well as for building new models that learn versatile, adaptable representations useful beyond their original training task. We study these questions using synthetic datasets in which the task-relevance of different input features can be controlled directly. We find that when two features redundantly predict the label, the model preferentially represents one, and its preference reflects what was most linearly decodable from the untrained model. Over training, task-relevant features are enhanced, and task-irrelevant features are partially suppressed. Interestingly, in some cases, an easier, weakly predictive feature can suppress a more strongly predictive, but harder one. Additionally, models trained to recognize both easy and hard features learn representations most similar to models that use only the easy feature. Further, easy features lead to more consistent representations across model runs than do hard features. Finally, models have more in common with an untrained model than with models trained on a different task. Our results highlight the complex processes that determine which features a model represents.
Exploring the Origins and Prevalence of Texture Bias in Convolutional Neural Networks
Nov 20, 2019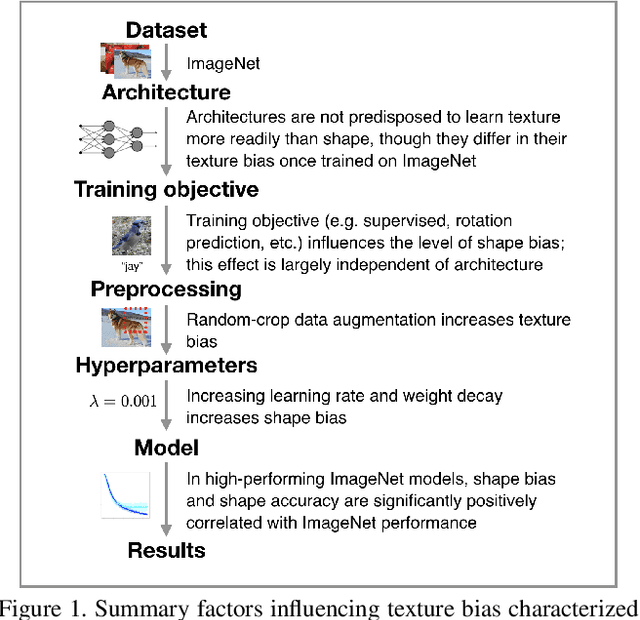

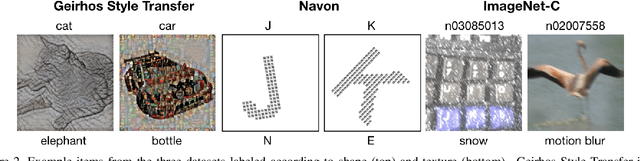

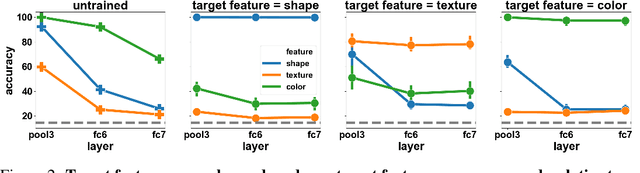
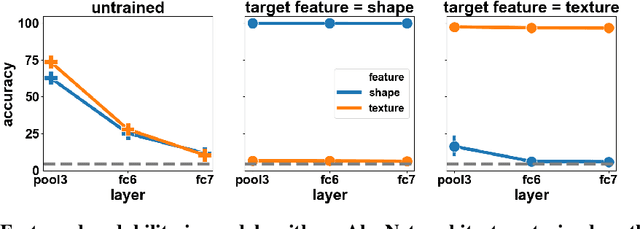
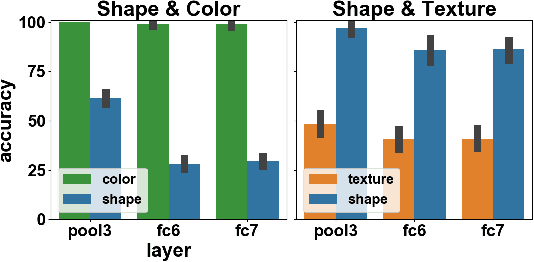
Recent work has indicated that, unlike humans, ImageNet-trained CNNs tend to classify images by texture rather than shape. How pervasive is this bias, and where does it come from? We find that, when trained on datasets of images with conflicting shape and texture, the inductive bias of CNNs often favors shape; in general, models learn shape at least as easily as texture. Moreover, although ImageNet training leads to classifier weights that classify ambiguous images according to texture, shape is decodable from the hidden representations of ImageNet networks. Turning to the question of the origin of texture bias, we identify consistent effects of task, architecture, preprocessing, and hyperparameters. Different self-supervised training objectives and different architectures have significant and largely independent effects on the shape bias of the learned representations. Among modern ImageNet architectures, we find that shape bias is positively correlated with ImageNet accuracy. Random-crop data augmentation encourages reliance on texture: Models trained without crops have lower accuracy but higher shape bias. Finally, hyperparameter combinations that yield similar accuracy are associated with vastly different levels of shape bias. Our results suggest general strategies to reduce texture bias in neural networks.