 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraffic4cast at NeurIPS 2022 -- Predict Dynamics along Graph Edges from Sparse Node Data: Whole City Traffic and ETA from Stationary Vehicle Detectors
Mar 14, 2023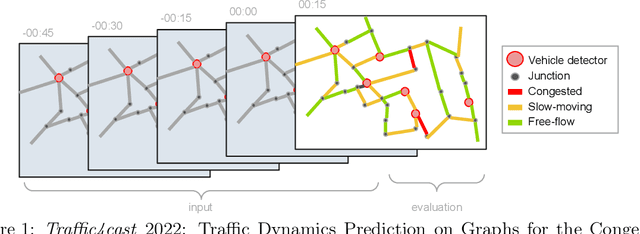
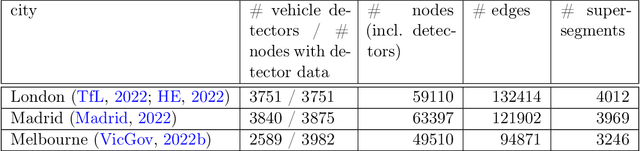
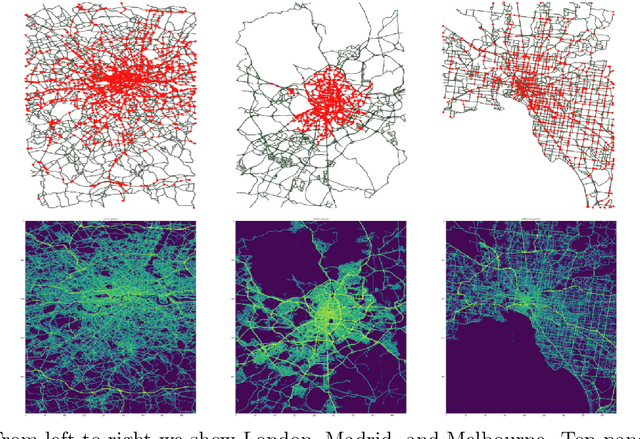
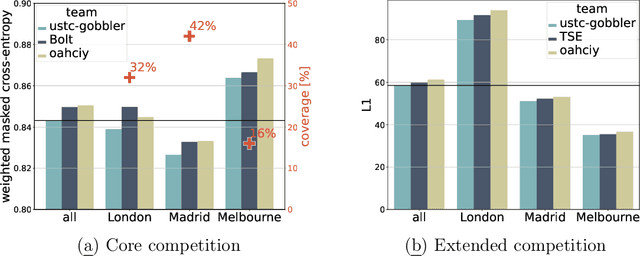
The global trends of urbanization and increased personal mobility force us to rethink the way we live and use urban space. The Traffic4cast competition series tackles this problem in a data-driven way, advancing the latest methods in machine learning for modeling complex spatial systems over time. In this edition, our dynamic road graph data combine information from road maps, $10^{12}$ probe data points, and stationary vehicle detectors in three cities over the span of two years. While stationary vehicle detectors are the most accurate way to capture traffic volume, they are only available in few locations. Traffic4cast 2022 explores models that have the ability to generalize loosely related temporal vertex data on just a few nodes to predict dynamic future traffic states on the edges of the entire road graph. In the core challenge, participants are invited to predict the likelihoods of three congestion classes derived from the speed levels in the GPS data for the entire road graph in three cities 15 min into the future. We only provide vehicle count data from spatially sparse stationary vehicle detectors in these three cities as model input for this task. The data are aggregated in 15 min time bins for one hour prior to the prediction time. For the extended challenge, participants are tasked to predict the average travel times on super-segments 15 min into the future - super-segments are longer sequences of road segments in the graph. The competition results provide an important advance in the prediction of complex city-wide traffic states just from publicly available sparse vehicle data and without the need for large amounts of real-time floating vehicle data.
Multi-task Learning for Sparse Traffic Forecasting
Nov 18, 2022Accurate traffic prediction is crucial to improve the performance of intelligent transportation systems. Previous traffic prediction tasks mainly focus on small and non-isolated traffic subsystems, while the Traffic4cast 2022 competition is dedicated to exploring the traffic state dynamics of entire cities. Given one hour of sparse loop count data only, the task is to predict the congestion classes for all road segments and the expected times of arrival along super-segments 15 minutes into the future. The sparsity of loop counter data and highly uncertain real-time traffic conditions make the competition challenging. For this reason, we propose a multi-task learning network that can simultaneously predict the congestion classes and the speed of each road segment. Specifically, we use clustering and neural network methods to learn the dynamic features of loop counter data. Then, we construct a graph with road segments as nodes and capture the spatial dependence between road segments based on a Graph Neural Network. Finally, we learn three measures, namely the congestion class, the speed value and the volume class, simultaneously through a multi-task learning module. For the extended competition, we use the predicted speeds to calculate the expected times of arrival along super-segments. Our method achieved excellent results on the dataset provided by the Traffic4cast Competition 2022, source code is available at https://github.com/OctopusLi/NeurIPS2022-traffic4cast.
XTQA: Span-Level Explanations of the Textbook Question Answering
Dec 17, 2020
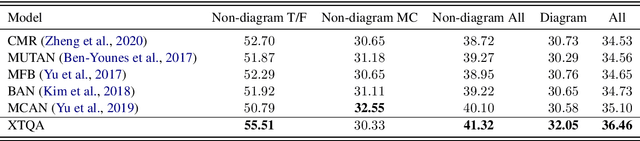
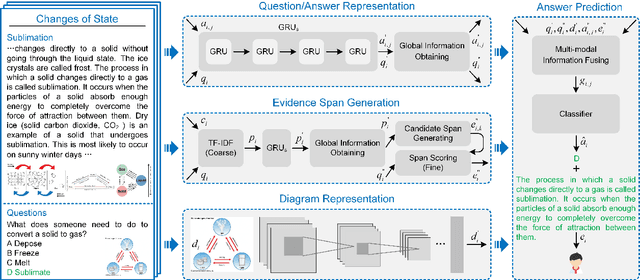
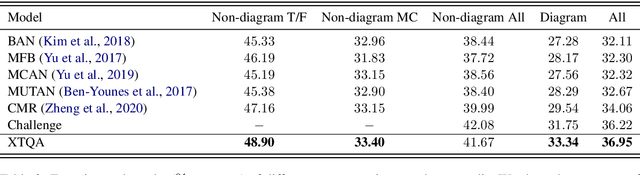
Textbook Question Answering (TQA) is a task that one should answer a diagram/non-diagram question given a large multi-modal context consisting of abundant essays and diagrams. We argue that the explainability of this task should place students as a key aspect to be considered. To address this issue, we devise a novel architecture towards span-level eXplanations of the TQA (XTQA) based on our proposed coarse-to-fine grained algorithm, which can provide not only the answers but also the span-level evidences to choose them for students. This algorithm first coarsely chooses top $M$ paragraphs relevant to questions using the TF-IDF method, and then chooses top $K$ evidence spans finely from all candidate spans within these paragraphs by computing the information gain of each span to questions. Experimental results shows that XTQA significantly improves the state-of-the-art performance compared with baselines. The source code is available at https://github.com/keep-smile-001/opentqa