 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTWLV-I: Analysis and Insights from Holistic Evaluation on Video Foundation Models
Aug 21, 2024In this work, we discuss evaluating video foundation models in a fair and robust manner. Unlike language or image foundation models, many video foundation models are evaluated with differing parameters (such as sampling rate, number of frames, pretraining steps, etc.), making fair and robust comparisons challenging. Therefore, we present a carefully designed evaluation framework for measuring two core capabilities of video comprehension: appearance and motion understanding. Our findings reveal that existing video foundation models, whether text-supervised like UMT or InternVideo2, or self-supervised like V-JEPA, exhibit limitations in at least one of these capabilities. As an alternative, we introduce TWLV-I, a new video foundation model that constructs robust visual representations for both motion- and appearance-based videos. Based on the average top-1 accuracy of linear probing on five action recognition benchmarks, pretrained only on publicly accessible datasets, our model shows a 4.6%p improvement compared to V-JEPA (ViT-L) and a 7.7%p improvement compared to UMT (ViT-L). Even when compared to much larger models, our model demonstrates a 7.2%p improvement compared to DFN (ViT-H), a 2.7%p improvement compared to V-JEPA~(ViT-H) and a 2.8%p improvement compared to InternVideo2 (ViT-g). We provide embedding vectors obtained by TWLV-I from videos of several commonly used video benchmarks, along with evaluation source code that can directly utilize these embeddings. The code is available on "https://github.com/twelvelabs-io/video-embeddings-evaluation-framework".
Pose-MUM : Reinforcing Key Points Relationship for Semi-Supervised Human Pose Estimation
Mar 15, 2022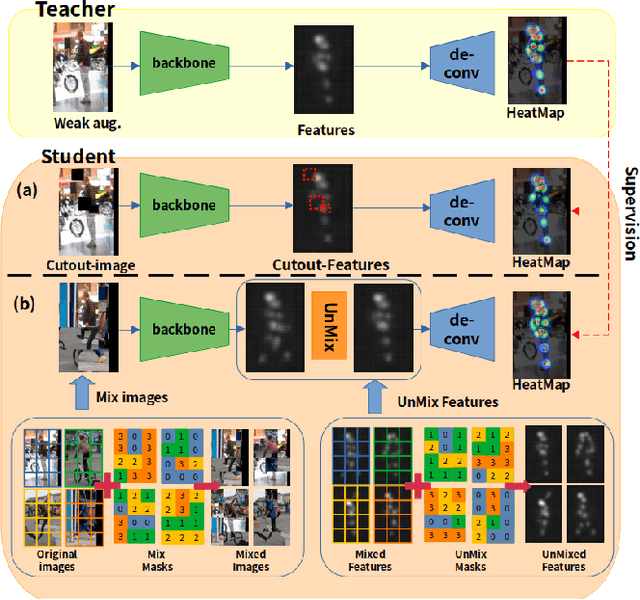
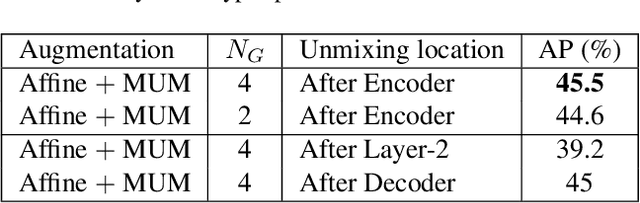

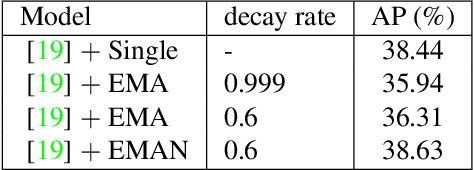
A well-designed strong-weak augmentation strategy and the stable teacher to generate reliable pseudo labels are essential in the teacher-student framework of semi-supervised learning (SSL). Considering these in mind, to suit the semi-supervised human pose estimation (SSHPE) task, we propose a novel approach referred to as Pose-MUM that modifies Mix/UnMix (MUM) augmentation. Like MUM in the dense prediction task, the proposed Pose-MUM makes strong-weak augmentation for pose estimation and leads the network to learn the relationship between each human key point much better than the conventional methods by adding the mixing process in intermediate layers in a stochastic manner. In addition, we employ the exponential-moving-average-normalization (EMAN) teacher, which is stable and well-suited to the SSL framework and furthermore boosts the performance. Extensive experiments on MS-COCO dataset show the superiority of our proposed method by consistently improving the performance over the previous methods following SSHPE benchmark.
MUM : Mix Image Tiles and UnMix Feature Tiles for Semi-Supervised Object Detection
Nov 22, 2021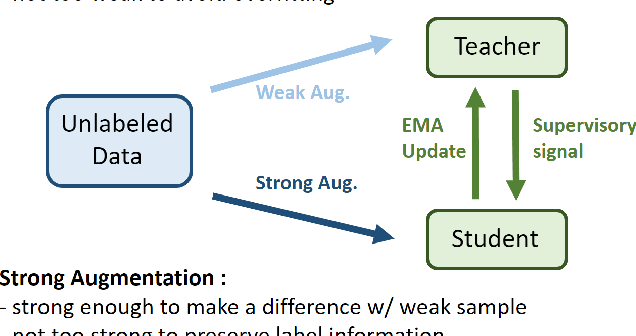
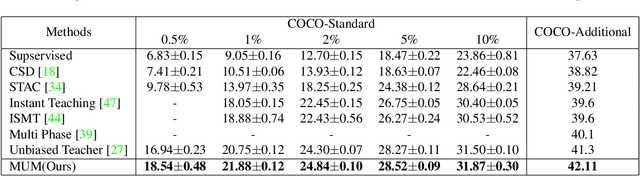
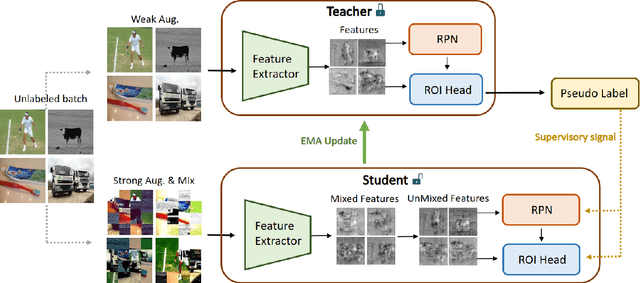
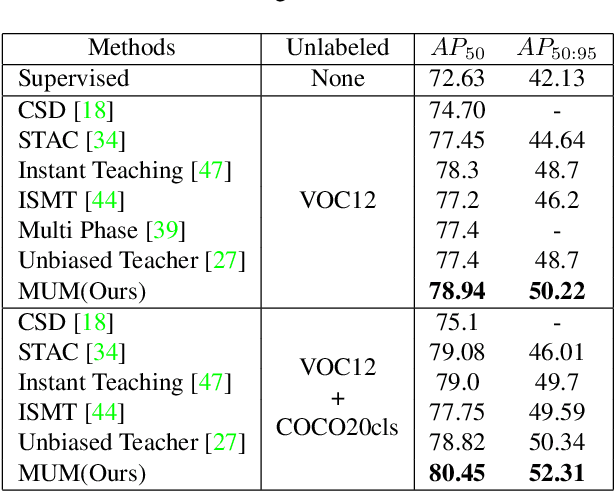
Many recent semi-supervised learning (SSL) studies build teacher-student architecture and train the student network by the generated supervisory signal from the teacher. Data augmentation strategy plays a significant role in the SSL framework since it is hard to create a weak-strong augmented input pair without losing label information. Especially when extending SSL to semi-supervised object detection (SSOD), many strong augmentation methodologies related to image geometry and interpolation-regularization are hard to utilize since they possibly hurt the location information of the bounding box in the object detection task. To address this, we introduce a simple yet effective data augmentation method, Mix/UnMix (MUM), which unmixes feature tiles for the mixed image tiles for the SSOD framework. Our proposed method makes mixed input image tiles and reconstructs them in the feature space. Thus, MUM can enjoy the interpolation-regularization effect from non-interpolated pseudo-labels and successfully generate a meaningful weak-strong pair. Furthermore, MUM can be easily equipped on top of various SSOD methods. Extensive experiments on MS-COCO and PASCAL VOC datasets demonstrate the superiority of MUM by consistently improving the mAP performance over the baseline in all the tested SSOD benchmark protocols.