 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUM : Mix Image Tiles and UnMix Feature Tiles for Semi-Supervised Object Detection
Nov 22, 2021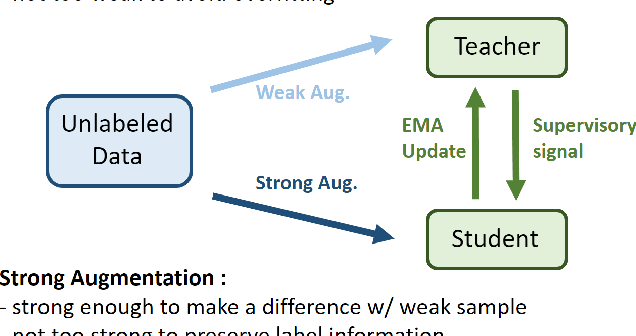
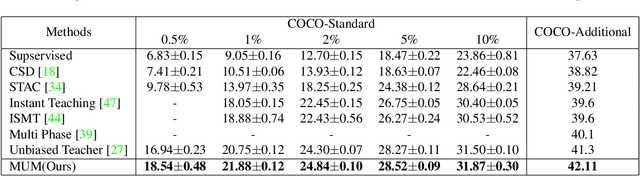
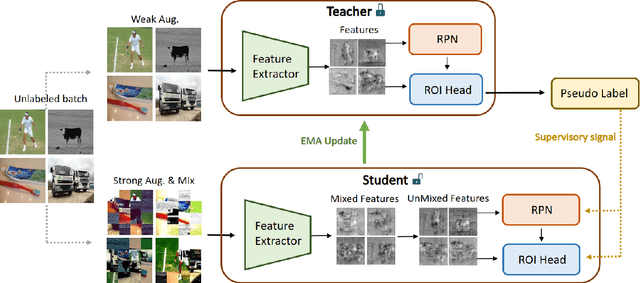
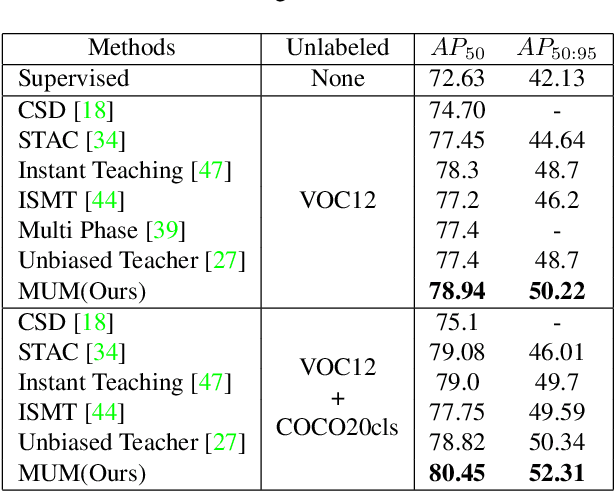
Many recent semi-supervised learning (SSL) studies build teacher-student architecture and train the student network by the generated supervisory signal from the teacher. Data augmentation strategy plays a significant role in the SSL framework since it is hard to create a weak-strong augmented input pair without losing label information. Especially when extending SSL to semi-supervised object detection (SSOD), many strong augmentation methodologies related to image geometry and interpolation-regularization are hard to utilize since they possibly hurt the location information of the bounding box in the object detection task. To address this, we introduce a simple yet effective data augmentation method, Mix/UnMix (MUM), which unmixes feature tiles for the mixed image tiles for the SSOD framework. Our proposed method makes mixed input image tiles and reconstructs them in the feature space. Thus, MUM can enjoy the interpolation-regularization effect from non-interpolated pseudo-labels and successfully generate a meaningful weak-strong pair. Furthermore, MUM can be easily equipped on top of various SSOD methods. Extensive experiments on MS-COCO and PASCAL VOC datasets demonstrate the superiority of MUM by consistently improving the mAP performance over the baseline in all the tested SSOD benchmark protocols.
Structured Consistency Loss for semi-supervised semantic segmentation
Jan 14, 2020
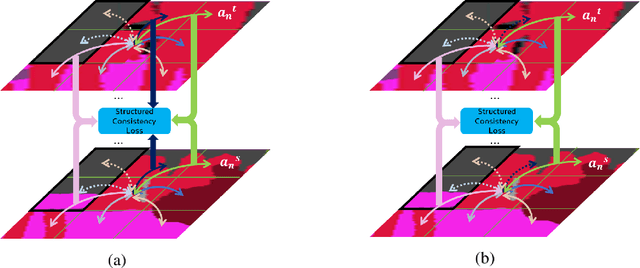
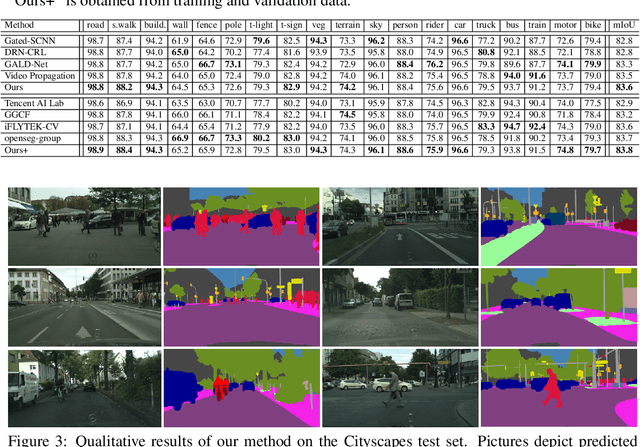
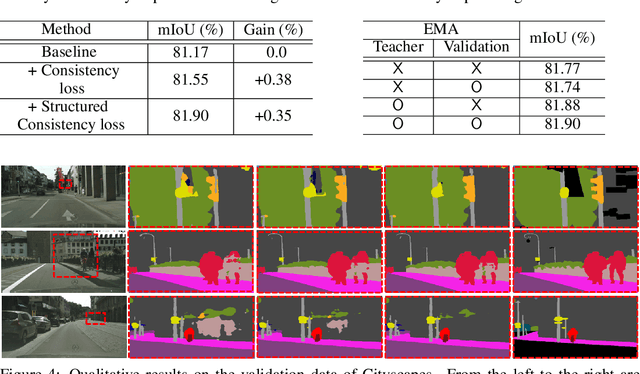
The consistency loss has played a key role in solving problems in recent studies on semi-supervised learning. Yet extant studies with the consistency loss are limited to its application to classification tasks; extant studies on semi-supervised semantic segmentation rely on pixel-wise classification, which does not reflect the structured nature of characteristics in prediction. We propose a structured consistency loss to address this limitation of extant studies. Structured consistency loss promotes consistency in inter-pixel similarity between teacher and student networks. Specifically, collaboration with CutMix optimizes the efficient performance of semi-supervised semantic segmentation with structured consistency loss by reducing computational burden dramatically. The superiority of proposed method is verified with the Cityscapes; The Cityscapes benchmark results with validation and with test data are 81.9 mIoU and 83.84 mIoU respectively. This ranks the first place on the pixel-level semantic labeling task of Cityscapes benchmark suite. To the best of our knowledge, we are the first to present the superiority of state-of-the-art semi-supervised learning in semantic segmentation.