 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Query Memorization: Large Language Model Routing with Query Decomposition and Historical Matching
May 25, 2026Optimizing the trade-off among predictive performance and computational cost is a central focus in the deployment of Large Language Models (LLMs). Current routing methods primarily rely on direct mapping from queries to models based on surface-level features, making them susceptible to the memorization trap and leading to poor generalizability on out-of-distribution (OOD) data. In this paper, we propose DecoR, a novel routing framework that recasts the routing task as a matching process of sifting similar queries from historical logs, effectively mitigating the memorization trap. To enhance matching accuracy, we introduce a query capability deconstruction method that decouples linguistic surface forms from task-intrinsic requirements, directing matching toward capability dimensions to ground decisions in essential task attributes. Furthermore, we develop CodaSet, a comprehensive benchmark for assessing routing generalization, where experimental results demonstrate that DecoR maintains superior accuracy while substantially lowering inference costs across both in-distribution and OOD settings. All the codes and data are available at https://github.com/lvbotenbest/DecoR.
Saliency-Guided Representation with Consistency Policy Learning for Visual Unsupervised Reinforcement Learning
Apr 07, 2026Zero-shot unsupervised reinforcement learning (URL) offers a promising direction for building generalist agents capable of generalizing to unseen tasks without additional supervision. Among existing approaches, successor representations (SR) have emerged as a prominent paradigm due to their effectiveness in structured, low-dimensional settings. However, SR methods struggle to scale to high-dimensional visual environments. Through empirical analysis, we identify two key limitations of SR in visual URL: (1) SR objectives often lead to suboptimal representations that attend to dynamics-irrelevant regions, resulting in inaccurate successor measures and degraded task generalization; and (2) these flawed representations hinder SR policies from modeling multi-modal skill-conditioned action distributions and ensuring skill controllability. To address these limitations, we propose Saliency-Guided Representation with Consistency Policy Learning (SRCP), a novel framework that improves zero-shot generalization of SR methods in visual URL. SRCP decouples representation learning from successor training by introducing a saliency-guided dynamics task to capture dynamics-relevant representations, thereby improving successor measure and task generalization. Moreover, it integrates a fast-sampling consistency policy with URL-specific classifier-free guidance and tailored training objectives to improve skill-conditioned policy modeling and controllability. Extensive experiments on 16 tasks across 4 datasets from the ExORL benchmark demonstrate that SRCP achieves state-of-the-art zero-shot generalization in visual URL and is compatible with various SR methods.
Randomized Neural Networks for Partial Differential Equation on Static and Evolving Surfaces
Mar 02, 2026Surface partial differential equations arise in numerous scientific and engineering applications. Their numerical solution on static and evolving surfaces remains challenging due to geometric complexity and, for evolving geometries, the need for repeated mesh updates and geometry or solution transfer. While neural-network-based methods offer mesh-free discretizations, approaches based on nonconvex training can be costly and may fail to deliver high accuracy in practice. In this work, we develop a randomized neural network (RaNN) method for solving PDEs on both static and evolving surfaces: the hidden-layer parameters are randomly generated and kept fixed, and the output-layer coefficients are determined efficiently by solving a least-squares problem. For static surfaces, we present formulations for parametrized surfaces, implicit level-set surfaces, and point-cloud geometries, and provide a corresponding theoretical analysis for the parametrization-based formulation with interface compatibility. For evolving surfaces with topology preserved over time, we introduce a RaNN-based strategy that learns the surface evolution through a flow-map representation and then solves the surface PDE on a space--time collocation set, avoiding remeshing. Extensive numerical experiments demonstrate broad applicability and favorable accuracy--efficiency performance on representative benchmarks.
Online Preference-based Reinforcement Learning with Self-augmented Feedback from Large Language Model
Dec 22, 2024Preference-based reinforcement learning (PbRL) provides a powerful paradigm to avoid meticulous reward engineering by learning rewards based on human preferences. However, real-time human feedback is hard to obtain in online tasks. Most work suppose there is a "scripted teacher" that utilizes privileged predefined reward to provide preference feedback. In this paper, we propose a RL Self-augmented Large Language Model Feedback (RL-SaLLM-F) technique that does not rely on privileged information for online PbRL. RL-SaLLM-F leverages the reflective and discriminative capabilities of LLM to generate self-augmented trajectories and provide preference labels for reward learning. First, we identify an failure issue in LLM-based preference discrimination, specifically "query ambiguity", in online PbRL. Then LLM is employed to provide preference labels and generate self-augmented imagined trajectories that better achieve the task goal, thereby enhancing the quality and efficiency of feedback. Additionally, a double-check mechanism is introduced to mitigate randomness in the preference labels, improving the reliability of LLM feedback. The experiment across multiple tasks in the MetaWorld benchmark demonstrates the specific contributions of each proposed module in RL-SaLLM-F, and shows that self-augmented LLM feedback can effectively replace the impractical "scripted teacher" feedback. In summary, RL-SaLLM-F introduces a new direction of feedback acquisition in online PbRL that does not rely on any online privileged information, offering an efficient and lightweight solution with LLM-driven feedback.
* 19 pages, The 24th International Conference on Autonomous Agents and Multi-Agent Systems (AAMAS25)
In-Dataset Trajectory Return Regularization for Offline Preference-based Reinforcement Learning
Dec 12, 2024



Offline preference-based reinforcement learning (PbRL) typically operates in two phases: first, use human preferences to learn a reward model and annotate rewards for a reward-free offline dataset; second, learn a policy by optimizing the learned reward via offline RL. However, accurately modeling step-wise rewards from trajectory-level preference feedback presents inherent challenges. The reward bias introduced, particularly the overestimation of predicted rewards, leads to optimistic trajectory stitching, which undermines the pessimism mechanism critical to the offline RL phase. To address this challenge, we propose In-Dataset Trajectory Return Regularization (DTR) for offline PbRL, which leverages conditional sequence modeling to mitigate the risk of learning inaccurate trajectory stitching under reward bias. Specifically, DTR employs Decision Transformer and TD-Learning to strike a balance between maintaining fidelity to the behavior policy with high in-dataset trajectory returns and selecting optimal actions based on high reward labels. Additionally, we introduce an ensemble normalization technique that effectively integrates multiple reward models, balancing the tradeoff between reward differentiation and accuracy. Empirical evaluations on various benchmarks demonstrate the superiority of DTR over other state-of-the-art baselines
* 7 pages, Proceedings of the 39th AAAI Conference on Artificial Intelligence (AAAI-25)
Soulstyler: Using Large Language Model to Guide Image Style Transfer for Target Object
Nov 29, 2023Image style transfer occupies an important place in both computer graphics and computer vision. However, most current methods require reference to stylized images and cannot individually stylize specific objects. To overcome this limitation, we propose the "Soulstyler" framework, which allows users to guide the stylization of specific objects in an image through simple textual descriptions. We introduce a large language model to parse the text and identify stylization goals and specific styles. Combined with a CLIP-based semantic visual embedding encoder, the model understands and matches text and image content. We also introduce a novel localized text-image block matching loss that ensures that style transfer is performed only on specified target objects, while non-target regions remain in their original style. Experimental results demonstrate that our model is able to accurately perform style transfer on target objects according to textual descriptions without affecting the style of background regions. Our code will be available at https://github.com/yisuanwang/Soulstyler.
Gradient-based Novelty Detection Boosted by Self-supervised Binary Classification
Dec 18, 2021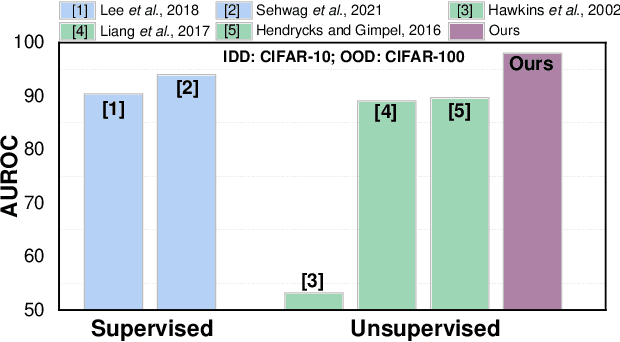
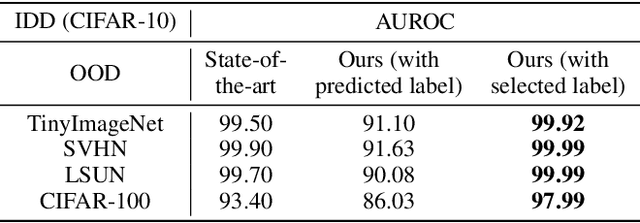
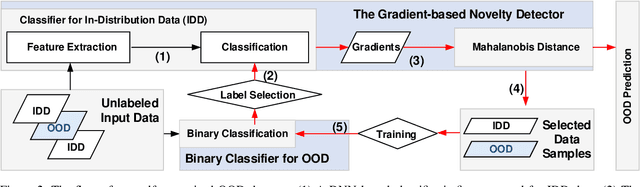
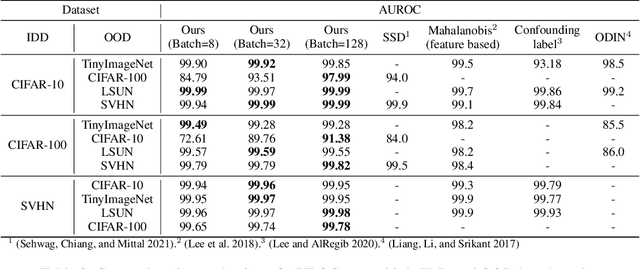
Novelty detection aims to automatically identify out-of-distribution (OOD) data, without any prior knowledge of them. It is a critical step in data monitoring, behavior analysis and other applications, helping enable continual learning in the field. Conventional methods of OOD detection perform multi-variate analysis on an ensemble of data or features, and usually resort to the supervision with OOD data to improve the accuracy. In reality, such supervision is impractical as one cannot anticipate the anomalous data. In this paper, we propose a novel, self-supervised approach that does not rely on any pre-defined OOD data: (1) The new method evaluates the Mahalanobis distance of the gradients between the in-distribution and OOD data. (2) It is assisted by a self-supervised binary classifier to guide the label selection to generate the gradients, and maximize the Mahalanobis distance. In the evaluation with multiple datasets, such as CIFAR-10, CIFAR-100, SVHN and TinyImageNet, the proposed approach consistently outperforms state-of-the-art supervised and unsupervised methods in the area under the receiver operating characteristic (AUROC) and area under the precision-recall curve (AUPR) metrics. We further demonstrate that this detector is able to accurately learn one OOD class in continual learning.