 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-based Inverse Rendering of Complex Indoor Scenes with Differentiable Monte Carlo Raytracing
Nov 06, 2022



Indoor scenes typically exhibit complex, spatially-varying appearance from global illumination, making inverse rendering a challenging ill-posed problem. This work presents an end-to-end, learning-based inverse rendering framework incorporating differentiable Monte Carlo raytracing with importance sampling. The framework takes a single image as input to jointly recover the underlying geometry, spatially-varying lighting, and photorealistic materials. Specifically, we introduce a physically-based differentiable rendering layer with screen-space ray tracing, resulting in more realistic specular reflections that match the input photo. In addition, we create a large-scale, photorealistic indoor scene dataset with significantly richer details like complex furniture and dedicated decorations. Further, we design a novel out-of-view lighting network with uncertainty-aware refinement leveraging hypernetwork-based neural radiance fields to predict lighting outside the view of the input photo. Through extensive evaluations on common benchmark datasets, we demonstrate superior inverse rendering quality of our method compared to state-of-the-art baselines, enabling various applications such as complex object insertion and material editing with high fidelity. Code and data will be made available at \url{https://jingsenzhu.github.io/invrend}.
MINERVAS: Massive INterior EnviRonments VirtuAl Synthesis
Jul 14, 2021


With the rapid development of data-driven techniques, data has played an essential role in various computer vision tasks. Many realistic and synthetic datasets have been proposed to address different problems. However, there are lots of unresolved challenges: (1) the creation of dataset is usually a tedious process with manual annotations, (2) most datasets are only designed for a single specific task, (3) the modification or randomization of the 3D scene is difficult, and (4) the release of commercial 3D data may encounter copyright issue. This paper presents MINERVAS, a Massive INterior EnviRonments VirtuAl Synthesis system, to facilitate the 3D scene modification and the 2D image synthesis for various vision tasks. In particular, we design a programmable pipeline with Domain-Specific Language, allowing users to (1) select scenes from the commercial indoor scene database, (2) synthesize scenes for different tasks with customized rules, and (3) render various imagery data, such as visual color, geometric structures, semantic label. Our system eases the difficulty of customizing massive numbers of scenes for different tasks and relieves users from manipulating fine-grained scene configurations by providing user-controllable randomness using multi-level samplers. Most importantly, it empowers users to access commercial scene databases with millions of indoor scenes and protects the copyright of core data assets, e.g., 3D CAD models. We demonstrate the validity and flexibility of our system by using our synthesized data to improve the performance on different kinds of computer vision tasks.
A Video Analysis Method on Wanfang Dataset via Deep Neural Network
Feb 28, 2020

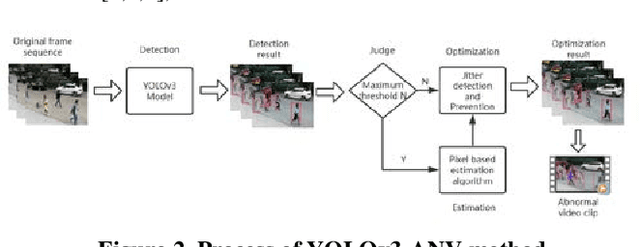
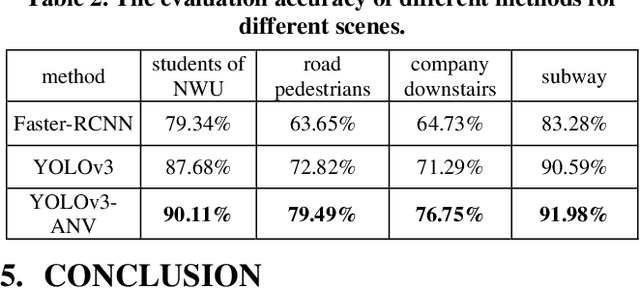
The topic of object detection has been largely improved recently, especially with the development of convolutional neural network. However, there still exist a lot of challenging cases, such as small object, compact and dense or highly overlapping object. Existing methods can detect multiple objects wonderfully, but because of the slight changes between frames, the detection effect of the model will become unstable, the detection results may result in dropping or increasing the object. In the pedestrian flow detection task, such phenomenon can not accurately calculate the flow. To solve this problem, in this paper, we describe the new function for real-time multi-object detection in sports competition and pedestrians flow detection in public based on deep learning. Our work is to extract a video clip and solve this frame of clips efficiently. More specfically, our algorithm includes two stages: judge method and optimization method. The judge can set a maximum threshold for better results under the model, the threshold value corresponds to the upper limit of the algorithm with better detection results. The optimization method to solve detection jitter problem. Because of the occurrence of frame hopping in the video, and it will result in the generation of video fragments discontinuity. We use optimization algorithm to get the key value, and then the detection result value of index is replaced by key value to stabilize the change of detection result sequence. Based on the proposed algorithm, we adopt wanfang sports competition dataset as the main test dataset and our own test dataset for YOLOv3-Abnormal Number Version(YOLOv3-ANV), which is 5.4% average improvement compared with existing methods. Also, video above the threshold value can be obtained for further analysis. Spontaneously, our work also can used for pedestrians flow detection and pedestrian alarm tasks.