 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Better Dermoscopic Image Feature Representation Learning for Melanoma Classification
Jul 15, 2022Deep learning-based melanoma classification with dermoscopic images has recently shown great potential in automatic early-stage melanoma diagnosis. However, limited by the significant data imbalance and obvious extraneous artifacts, i.e., the hair and ruler markings, discriminative feature extraction from dermoscopic images is very challenging. In this study, we seek to resolve these problems respectively towards better representation learning for lesion features. Specifically, a GAN-based data augmentation (GDA) strategy is adapted to generate synthetic melanoma-positive images, in conjunction with the proposed implicit hair denoising (IHD) strategy. Wherein the hair-related representations are implicitly disentangled via an auxiliary classifier network and reversely sent to the melanoma-feature extraction backbone for better melanoma-specific representation learning. Furthermore, to train the IHD module, the hair noises are additionally labeled on the ISIC2020 dataset, making it the first large-scale dermoscopic dataset with annotation of hair-like artifacts. Extensive experiments demonstrate the superiority of the proposed framework as well as the effectiveness of each component. The improved dataset publicly avaliable at https://github.com/kirtsy/DermoscopicDataset.
Assessing generalisability of deep learning-based polyp detection and segmentation methods through a computer vision challenge
Feb 24, 2022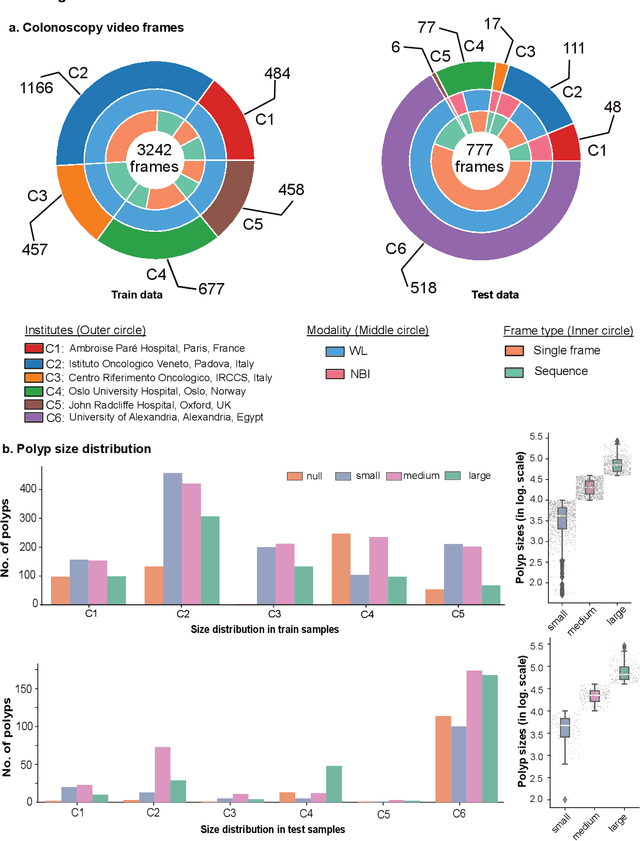
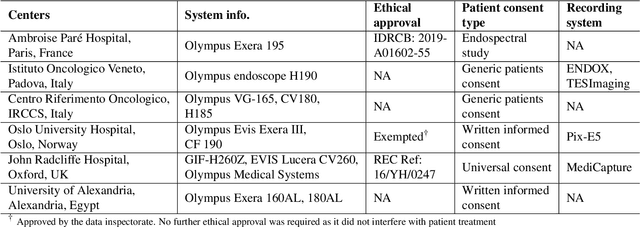
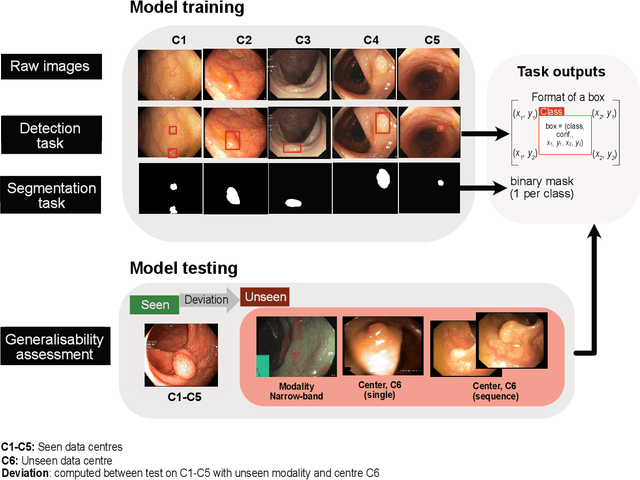
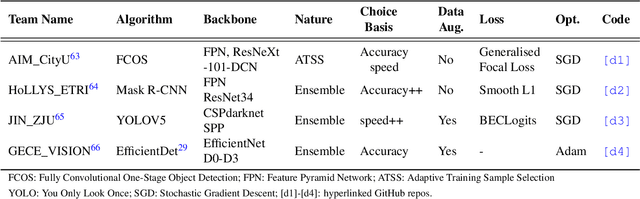
Polyps are well-known cancer precursors identified by colonoscopy. However, variability in their size, location, and surface largely affect identification, localisation, and characterisation. Moreover, colonoscopic surveillance and removal of polyps (referred to as polypectomy ) are highly operator-dependent procedures. There exist a high missed detection rate and incomplete removal of colonic polyps due to their variable nature, the difficulties to delineate the abnormality, the high recurrence rates, and the anatomical topography of the colon. There have been several developments in realising automated methods for both detection and segmentation of these polyps using machine learning. However, the major drawback in most of these methods is their ability to generalise to out-of-sample unseen datasets that come from different centres, modalities and acquisition systems. To test this hypothesis rigorously we curated a multi-centre and multi-population dataset acquired from multiple colonoscopy systems and challenged teams comprising machine learning experts to develop robust automated detection and segmentation methods as part of our crowd-sourcing Endoscopic computer vision challenge (EndoCV) 2021. In this paper, we analyse the detection results of the four top (among seven) teams and the segmentation results of the five top teams (among 16). Our analyses demonstrate that the top-ranking teams concentrated on accuracy (i.e., accuracy > 80% on overall Dice score on different validation sets) over real-time performance required for clinical applicability. We further dissect the methods and provide an experiment-based hypothesis that reveals the need for improved generalisability to tackle diversity present in multi-centre datasets.