 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstraintMatch for Semi-constrained Clustering
Nov 26, 2023Constrained clustering allows the training of classification models using pairwise constraints only, which are weak and relatively easy to mine, while still yielding full-supervision-level model performance. While they perform well even in the absence of the true underlying class labels, constrained clustering models still require large amounts of binary constraint annotations for training. In this paper, we propose a semi-supervised context whereby a large amount of \textit{unconstrained} data is available alongside a smaller set of constraints, and propose \textit{ConstraintMatch} to leverage such unconstrained data. While a great deal of progress has been made in semi-supervised learning using full labels, there are a number of challenges that prevent a naive application of the resulting methods in the constraint-based label setting. Therefore, we reason about and analyze these challenges, specifically 1) proposing a \textit{pseudo-constraining} mechanism to overcome the confirmation bias, a major weakness of pseudo-labeling, 2) developing new methods for pseudo-labeling towards the selection of \textit{informative} unconstrained samples, 3) showing that this also allows the use of pairwise loss functions for the initial and auxiliary losses which facilitates semi-constrained model training. In extensive experiments, we demonstrate the effectiveness of ConstraintMatch over relevant baselines in both the regular clustering and overclustering scenarios on five challenging benchmarks and provide analyses of its several components.
Approximate Bayes Optimal Pseudo-Label Selection
Feb 20, 2023Semi-supervised learning by self-training heavily relies on pseudo-label selection (PLS). The selection often depends on the initial model fit on labeled data. Early overfitting might thus be propagated to the final model by selecting instances with overconfident but erroneous predictions, often referred to as confirmation bias. This paper introduces BPLS, a Bayesian framework for PLS that aims to mitigate this issue. At its core lies a criterion for selecting instances to label: an analytical approximation of the posterior predictive of pseudo-samples. We derive this selection criterion by proving Bayes optimality of the posterior predictive of pseudo-samples. We further overcome computational hurdles by approximating the criterion analytically. Its relation to the marginal likelihood allows us to come up with an approximation based on Laplace's method and the Gaussian integral. We empirically assess BPLS for parametric generalized linear and non-parametric generalized additive models on simulated and real-world data. When faced with high-dimensional data prone to overfitting, BPLS outperforms traditional PLS methods.
Multimodal Deep Learning
Jan 12, 2023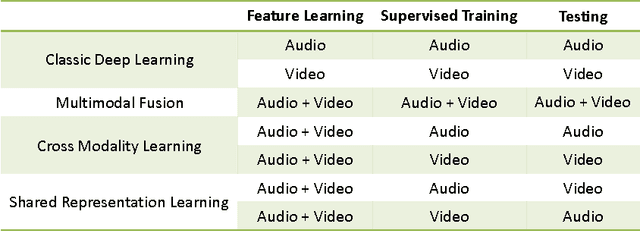
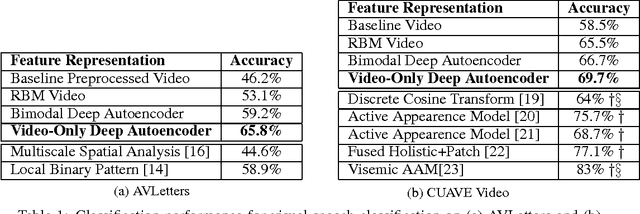
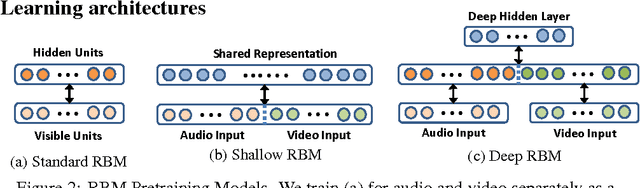
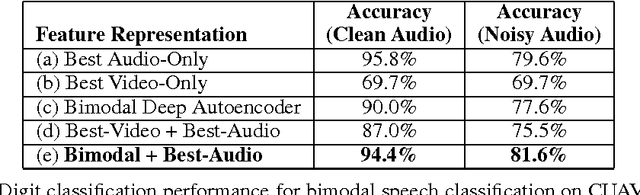
This book is the result of a seminar in which we reviewed multimodal approaches and attempted to create a solid overview of the field, starting with the current state-of-the-art approaches in the two subfields of Deep Learning individually. Further, modeling frameworks are discussed where one modality is transformed into the other, as well as models in which one modality is utilized to enhance representation learning for the other. To conclude the second part, architectures with a focus on handling both modalities simultaneously are introduced. Finally, we also cover other modalities as well as general-purpose multi-modal models, which are able to handle different tasks on different modalities within one unified architecture. One interesting application (Generative Art) eventually caps off this booklet.
Positive-Unlabeled Learning with Uncertainty-aware Pseudo-label Selection
Jan 31, 2022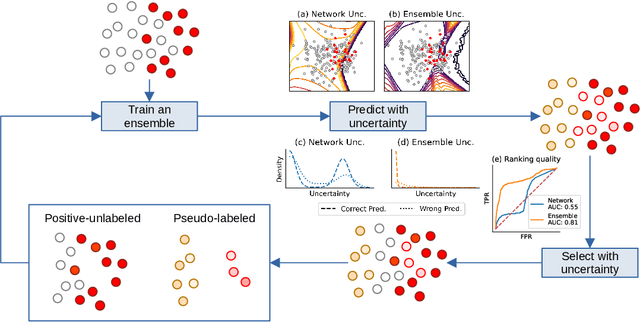
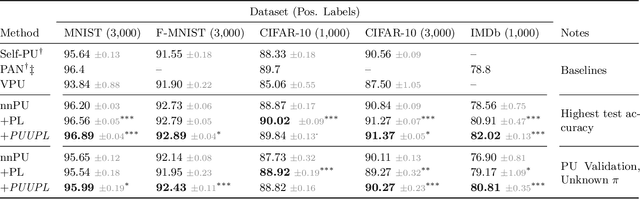
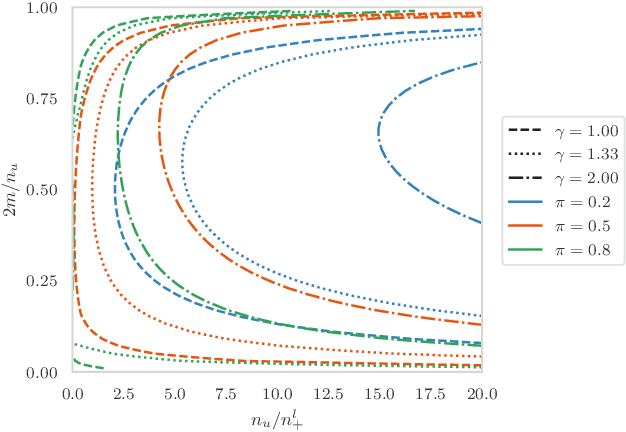
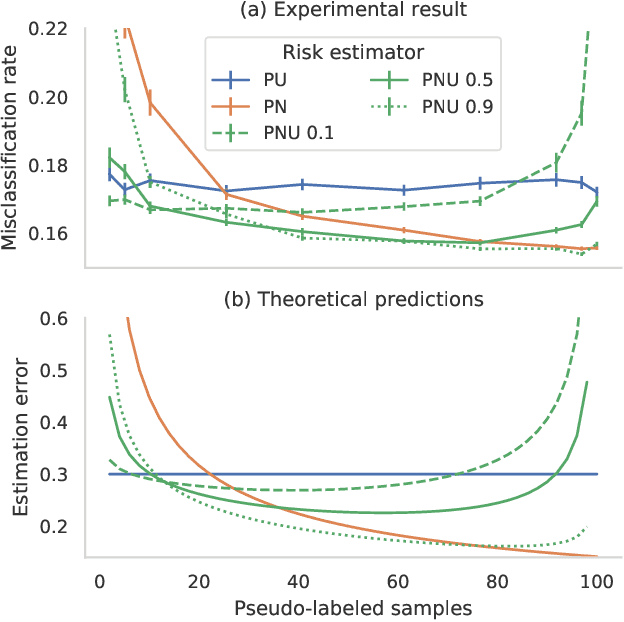
Pseudo-labeling solutions for positive-unlabeled (PU) learning have the potential to result in higher performance compared to cost-sensitive learning but are vulnerable to incorrectly estimated pseudo-labels. In this paper, we provide a theoretical analysis of a risk estimator that combines risk on PU and pseudo-labeled data. Furthermore, we show analytically as well as experimentally that such an estimator results in lower excess risk compared to using PU data alone, provided that enough samples are pseudo-labeled with acceptable error rates. We then propose PUUPL, a novel training procedure for PU learning that leverages the epistemic uncertainty of an ensemble of deep neural networks to minimize errors in pseudo-label selection. We conclude with extensive experiments showing the effectiveness of our proposed algorithm over different datasets, modalities, and learning tasks. These show that PUUPL enables a reduction of up to 20% in test error rates even when prior and negative samples are not provided for validation, setting a new state-of-the-art for PU learning.
Deep Semi-Supervised Learning for Time Series Classification
Feb 06, 2021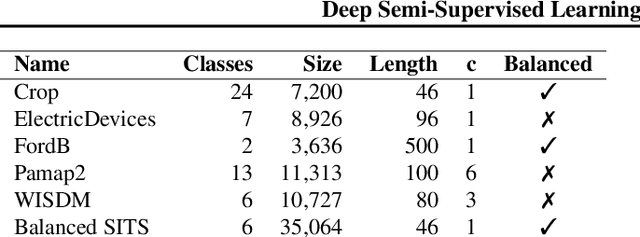
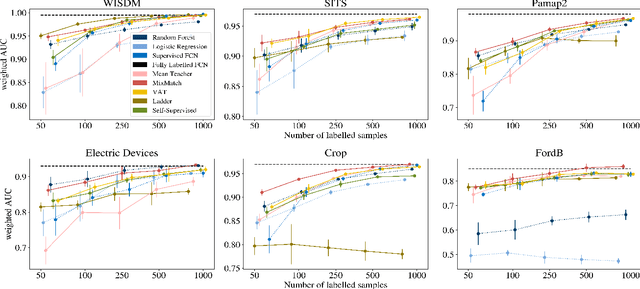
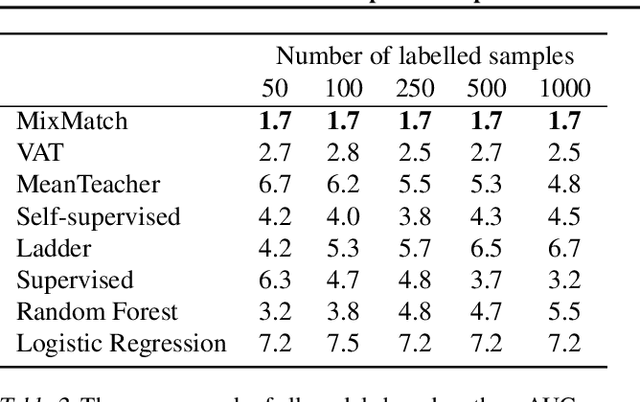
While Semi-supervised learning has gained much attention in computer vision on image data, yet limited research exists on its applicability in the time series domain. In this work, we investigate the transferability of state-of-the-art deep semi-supervised models from image to time series classification. We discuss the necessary model adaptations, in particular an appropriate model backbone architecture and the use of tailored data augmentation strategies. Based on these adaptations, we explore the potential of deep semi-supervised learning in the context of time series classification by evaluating our methods on large public time series classification problems with varying amounts of labelled samples. We perform extensive comparisons under a decidedly realistic and appropriate evaluation scheme with a unified reimplementation of all algorithms considered, which is yet lacking in the field. We find that these transferred semi-supervised models show significant performance gains over strong supervised, semi-supervised and self-supervised alternatives, especially for scenarios with very few labelled samples.
Granular Motor State Monitoring of Free Living Parkinson's Disease Patients via Deep Learning
Dec 11, 2019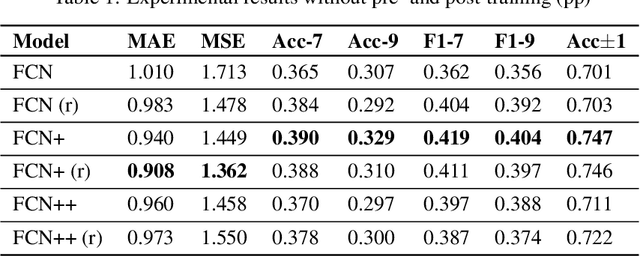
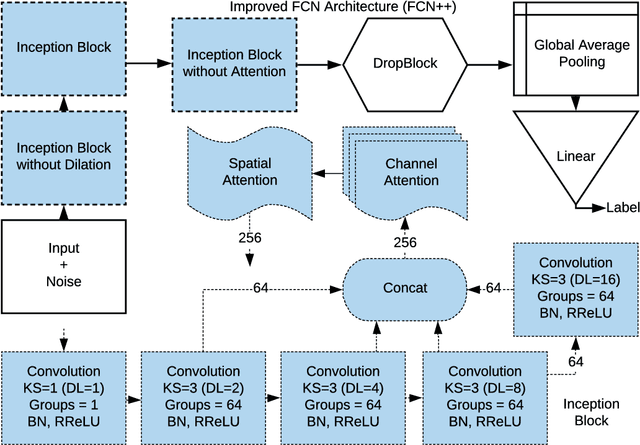
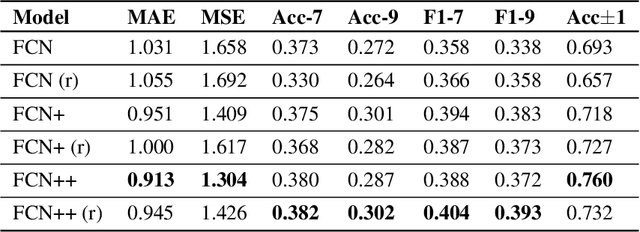
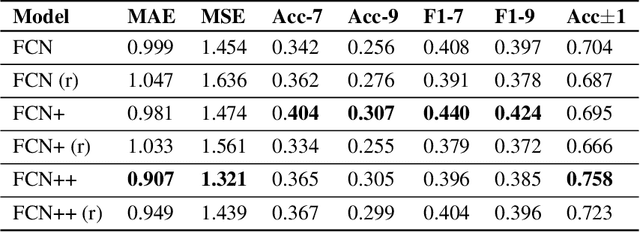
Parkinson's disease (PD) is the second most common neurodegenerative disease worldwide and affects around 1% of the (60+ years old) elderly population in industrial nations. More than 80% of PD patients suffer from motor symptoms, which could be well addressed if a personalized medication schedule and dosage could be administered to them. However, such personalized medication schedule requires a continuous, objective and precise measurement of motor symptoms experienced by the patients during their regular daily activities. In this work, we propose the use of a wrist-worn smart-watch, which is equipped with 3D motion sensors, for estimating the motor fluctuation severity of PD patients in a free-living environment. We introduce a novel network architecture, a post-training scheme and a custom loss function that accounts for label noise to improve the results of our previous work in this domain and to establish a novel benchmark for nine-level PD motor state estimation.
Wearable-based Parkinson's Disease Severity Monitoring using Deep Learning
Apr 24, 2019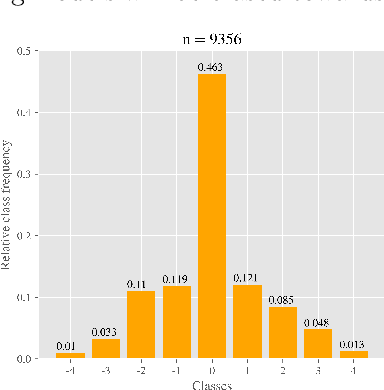
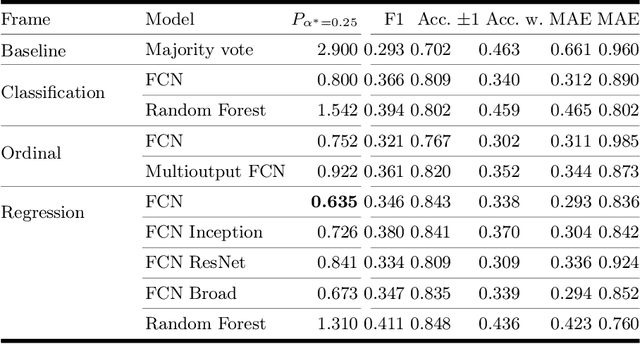
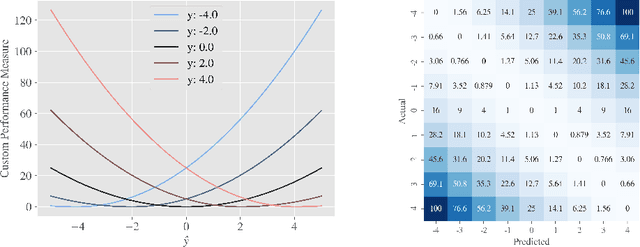
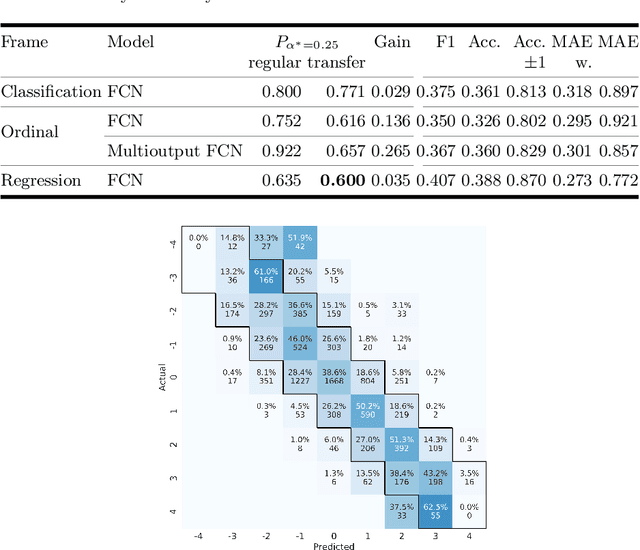
One major challenge in the medication of Parkinson's disease is that the severity of the disease, reflected in the patients' motor state, cannot be measured using accessible biomarkers. Therefore, we develop and examine a variety of statistical models to detect the motor state of such patients based on sensor data from a wearable device. We find that deep learning models consistently outperform a classical machine learning model applied on hand-crafted features in this time series classification task. Furthermore, our results suggest that treating this problem as a regression instead of an ordinal regression or a classification task is most appropriate. For consistent model evaluation and training, we adopt the leave-one-subject-out validation scheme to the training of deep learning models. We also employ a class-weighting scheme to successfully mitigate the problem of high multi-class imbalances in this domain. In addition, we propose a customized performance measure that reflects the requirements of the involved medical staff on the model. To solve the problem of limited availability of high quality training data, we propose a transfer learning technique which helps to improve model performance substantially. Our results suggest that deep learning techniques offer a high potential to autonomously detect motor states of patients with Parkinson's disease.