 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRaN-X: FRaming and Narratives-eXplorer
Jul 09, 2025We present FRaN-X, a Framing and Narratives Explorer that automatically detects entity mentions and classifies their narrative roles directly from raw text. FRaN-X comprises a two-stage system that combines sequence labeling with fine-grained role classification to reveal how entities are portrayed as protagonists, antagonists, or innocents, using a unique taxonomy of 22 fine-grained roles nested under these three main categories. The system supports five languages (Bulgarian, English, Hindi, Russian, and Portuguese) and two domains (the Russia-Ukraine Conflict and Climate Change). It provides an interactive web interface for media analysts to explore and compare framing across different sources, tackling the challenge of automatically detecting and labeling how entities are framed. Our system allows end users to focus on a single article as well as analyze up to four articles simultaneously. We provide aggregate level analysis including an intuitive graph visualization that highlights the narrative a group of articles are pushing. Our system includes a search feature for users to look up entities of interest, along with a timeline view that allows analysts to track an entity's role transitions across different contexts within the article. The FRaN-X system and the trained models are licensed under an MIT License. FRaN-X is publicly accessible at https://fran-x.streamlit.app/ and a video demonstration is available at https://youtu.be/VZVi-1B6yYk.
Entity Framing and Role Portrayal in the News
Feb 20, 2025



We introduce a novel multilingual hierarchical corpus annotated for entity framing and role portrayal in news articles. The dataset uses a unique taxonomy inspired by storytelling elements, comprising 22 fine-grained roles, or archetypes, nested within three main categories: protagonist, antagonist, and innocent. Each archetype is carefully defined, capturing nuanced portrayals of entities such as guardian, martyr, and underdog for protagonists; tyrant, deceiver, and bigot for antagonists; and victim, scapegoat, and exploited for innocents. The dataset includes 1,378 recent news articles in five languages (Bulgarian, English, Hindi, European Portuguese, and Russian) focusing on two critical domains of global significance: the Ukraine-Russia War and Climate Change. Over 5,800 entity mentions have been annotated with role labels. This dataset serves as a valuable resource for research into role portrayal and has broader implications for news analysis. We describe the characteristics of the dataset and the annotation process, and we report evaluation results on fine-tuned state-of-the-art multilingual transformers and hierarchical zero-shot learning using LLMs at the level of a document, a paragraph, and a sentence.
Cross-lingual Named Entity Corpus for Slavic Languages
Apr 07, 2024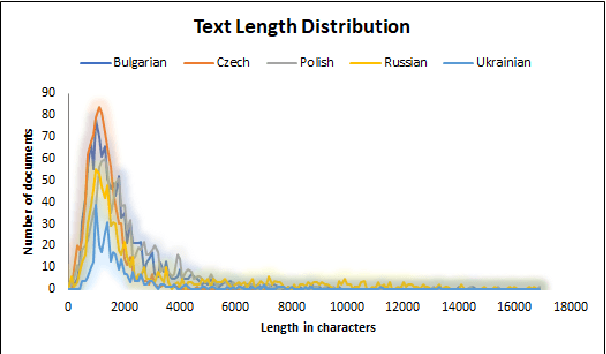

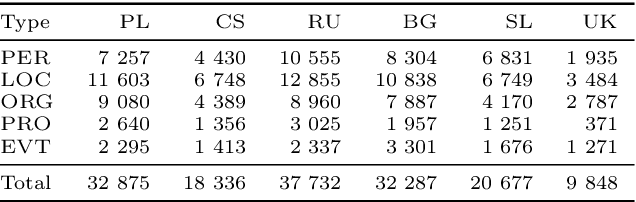
This paper presents a corpus manually annotated with named entities for six Slavic languages - Bulgarian, Czech, Polish, Slovenian, Russian, and Ukrainian. This work is the result of a series of shared tasks, conducted in 2017-2023 as a part of the Workshops on Slavic Natural Language Processing. The corpus consists of 5 017 documents on seven topics. The documents are annotated with five classes of named entities. Each entity is described by a category, a lemma, and a unique cross-lingual identifier. We provide two train-tune dataset splits - single topic out and cross topics. For each split, we set benchmarks using a transformer-based neural network architecture with the pre-trained multilingual models - XLM-RoBERTa-large for named entity mention recognition and categorization, and mT5-large for named entity lemmatization and linking.
Challenges and Applications of Automated Extraction of Socio-political Events from Text : Workshop and Shared Task Report
Aug 17, 2021This workshop is the fourth issue of a series of workshops on automatic extraction of socio-political events from news, organized by the Emerging Market Welfare Project, with the support of the Joint Research Centre of the European Commission and with contributions from many other prominent scholars in this field. The purpose of this series of workshops is to foster research and development of reliable, valid, robust, and practical solutions for automatically detecting descriptions of socio-political events, such as protests, riots, wars and armed conflicts, in text streams. This year workshop contributors make use of the state-of-the-art NLP technologies, such as Deep Learning, Word Embeddings and Transformers and cover a wide range of topics from text classification to news bias detection. Around 40 teams have registered and 15 teams contributed to three tasks that are i) multilingual protest news detection, ii) fine-grained classification of socio-political events, and iii) discovering Black Lives Matter protest events. The workshop also highlights two keynote and four invited talks about various aspects of creating event data sets and multi- and cross-lingual machine learning in few- and zero-shot settings.