 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Named Entity Corpus for Slavic Languages
Apr 07, 2024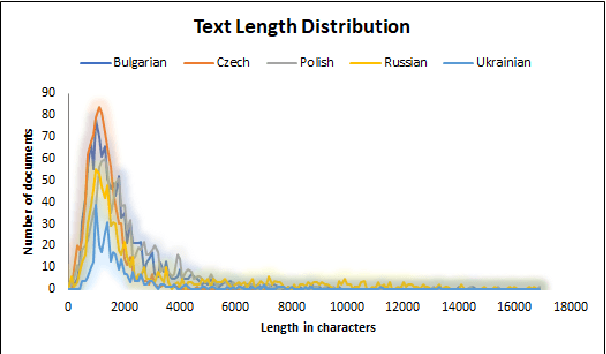

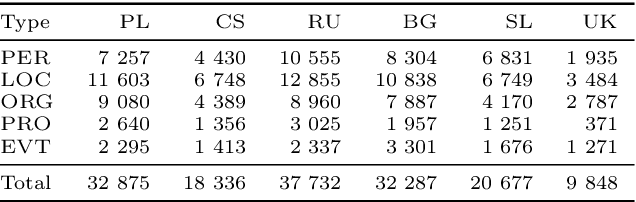
This paper presents a corpus manually annotated with named entities for six Slavic languages - Bulgarian, Czech, Polish, Slovenian, Russian, and Ukrainian. This work is the result of a series of shared tasks, conducted in 2017-2023 as a part of the Workshops on Slavic Natural Language Processing. The corpus consists of 5 017 documents on seven topics. The documents are annotated with five classes of named entities. Each entity is described by a category, a lemma, and a unique cross-lingual identifier. We provide two train-tune dataset splits - single topic out and cross topics. For each split, we set benchmarks using a transformer-based neural network architecture with the pre-trained multilingual models - XLM-RoBERTa-large for named entity mention recognition and categorization, and mT5-large for named entity lemmatization and linking.