 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector Space of Cycles
Jun 06, 2026Most statistical and machine learning methods for directed interactions focus on pairwise effects among variables. Even existing cyclic models represent feedback primarily through node-level dependencies, making large-scale recurrent organization difficult to estimate and compare. This limitation is particularly acute in biological and neural systems, where interactions are highly recurrent and involve many overlapping cycles. We introduce a variational framework for statistical inference on cyclic interactions. Directed interactions are represented as edge flows on a simplicial complex and evolved under an energy-minimizing dynamical system. The resulting dynamics separate transient interaction components from persistent harmonic flows, yielding a low-dimensional cycle space that captures stable recurrent organization. Rather than enumerating individual cycles, the proposed framework represents cyclic interactions as elements of a Hilbert space, enabling projection, averaging, comparison, and population-level statistical inference. We establish theoretical properties of the harmonic projection, including characterization of the cycle space, variance reduction, and population inference. Simulations demonstrate substantially improved recovery of cyclic structure in dense recurrent systems compared with existing directed-interaction methods. Applied to resting-state fMRI from 400 human subjects, the framework reveals reproducible large-scale cyclic organization that is not detectable through edgewise averaging. These results provide a scalable statistical framework for studying recurrent interactions in high-dimensional dynamical systems.
Functional MRI Time Series Generation via Wavelet-Based Image Transform and Spectral Flow Matching for Brain Disorder Identification
May 28, 2026Functional Magnetic Resonance Imaging (fMRI) provides non-invasive access to dynamic brain activity by measuring blood oxygen level-dependent (BOLD) signals over time. However, the resource-intensive nature of fMRI acquisition limits the availability of high-fidelity samples required for data-driven brain analysis models. While modern generative models can synthesize fMRI data, they often remain challenging in replicating their inherent non-stationarity, intricate spatiotemporal dynamics, and physiological variations of raw BOLD signals. To address these challenges, we propose Dual-Spectral Flow Matching (DSFM), a novel fMRI generative framework that cascades dual frequency representation of BOLD signals with spectral flow matching. Specifically, our framework first converts BOLD signals into a wavelet decomposition map via a discrete wavelet transform (DWT) to capture globalized transient and multi-scale variations, and projects into the discrete cosine transform (DCT) space across brain regions and time to exploit localized energy compaction of low-frequency dominant BOLD coefficients. Subsequently, a spectral flow matching model is trained to generate class-conditioned cosine-frequency representation. The generated samples are reconstructed through inverse DCT and inverse DWT operations to recover physiologically plausible time-domain BOLD signals. This dual-transform approach imposes structured frequency priors and preserves key physiological brain dynamics. Ultimately, we demonstrate the efficacy of our approach through improved downstream fMRI-based brain network classification. The code is available at https://github.com/htew0001/DSFM.git .
Forecasting Multivariate Time Series under Predictive Heterogeneity: A Validation-Driven Clustering Framework
Apr 15, 2026We study adaptive pooling under predictive heterogeneity in high-dimensional multivariate time series forecasting, where global models improve statistical efficiency but may fail to capture heterogeneous predictive structure, while naive specialization can induce negative transfer. We formulate adaptive pooling as a statistical decision problem and propose a validation-driven framework that determines when and how specialization should be applied. Rather than grouping series based on representation similarity, we define partitions through out-of-sample predictive performance, thereby aligning data organization with predictive risk, defined as expected out-of-sample loss and approximated via validation error. Cluster assignments are iteratively updated using validation losses for both point (Huber) and probabilistic (pinball) forecasting, improving robustness to heavy-tailed errors and local anomalies. To ensure reliability, we introduce a leakage-free fallback mechanism that reverts to a global model whenever specialization fails to improve validation performance, providing a safeguard against performance degradation under a strict training-validation-test protocol. Experiments on large-scale traffic datasets demonstrate consistent improvements over strong baselines while avoiding degradation when heterogeneity is weak. Overall, the proposed framework provides a principled and practically reliable approach to adaptive pooling in high-dimensional forecasting problems.
Robust fuzzy clustering for high-dimensional multivariate time series with outlier detection
Oct 30, 2025

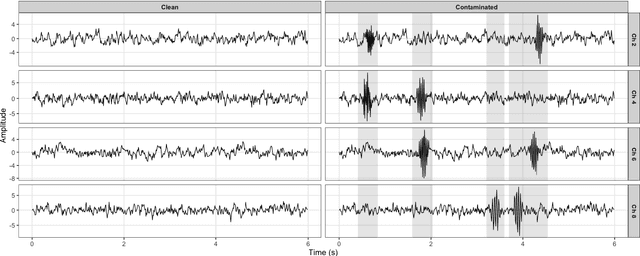

Fuzzy clustering provides a natural framework for modeling partial memberships, particularly important in multivariate time series (MTS) where state boundaries are often ambiguous. For example, in EEG monitoring of driver alertness, neural activity evolves along a continuum (from unconscious to fully alert, with many intermediate levels of drowsiness) so crisp labels are unrealistic and partial memberships are essential. However, most existing algorithms are developed for static, low-dimensional data and struggle with temporal dependence, unequal sequence lengths, high dimensionality, and contamination by noise or artifacts. To address these challenges, we introduce RFCPCA, a robust fuzzy subspace-clustering method explicitly tailored to MTS that, to the best of our knowledge, is the first of its kind to simultaneously: (i) learn membership-informed subspaces, (ii) accommodate unequal lengths and moderately high dimensions, (iii) achieve robustness through trimming, exponential reweighting, and a dedicated noise cluster, and (iv) automatically select all required hyperparameters. These components enable RFCPCA to capture latent temporal structure, provide calibrated membership uncertainty, and flag series-level outliers while remaining stable under contamination. On driver drowsiness EEG, RFCPCA improves clustering accuracy over related methods and yields a more reliable characterization of uncertainty and outlier structure in MTS.
FCPCA: Fuzzy clustering of high-dimensional time series based on common principal component analysis
May 12, 2025
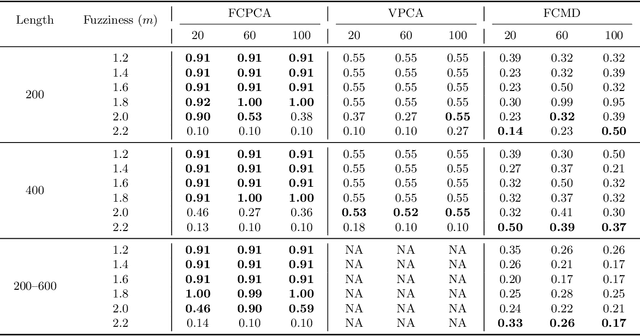


Clustering multivariate time series data is a crucial task in many domains, as it enables the identification of meaningful patterns and groups in time-evolving data. Traditional approaches, such as crisp clustering, rely on the assumption that clusters are sufficiently separated with little overlap. However, real-world data often defy this assumption, exhibiting overlapping distributions or overlapping clouds of points and blurred boundaries between clusters. Fuzzy clustering offers a compelling alternative by allowing partial membership in multiple clusters, making it well-suited for these ambiguous scenarios. Despite its advantages, current fuzzy clustering methods primarily focus on univariate time series, and for multivariate cases, even datasets of moderate dimensionality become computationally prohibitive. This challenge is further exacerbated when dealing with time series of varying lengths, leaving a clear gap in addressing the complexities of modern datasets. This work introduces a novel fuzzy clustering approach based on common principal component analysis to address the aforementioned shortcomings. Our method has the advantage of efficiently handling high-dimensional multivariate time series by reducing dimensionality while preserving critical temporal features. Extensive numerical results show that our proposed clustering method outperforms several existing approaches in the literature. An interesting application involving brain signals from different drivers recorded from a simulated driving experiment illustrates the potential of the approach.
SFC-GAN: A Generative Adversarial Network for Brain Functional and Structural Connectome Translation
Jan 13, 2025Modern brain imaging technologies have enabled the detailed reconstruction of human brain connectomes, capturing structural connectivity (SC) from diffusion MRI and functional connectivity (FC) from functional MRI. Understanding the intricate relationships between SC and FC is vital for gaining deeper insights into the brain's functional and organizational mechanisms. However, obtaining both SC and FC modalities simultaneously remains challenging, hindering comprehensive analyses. Existing deep generative models typically focus on synthesizing a single modality or unidirectional translation between FC and SC, thereby missing the potential benefits of bi-directional translation, especially in scenarios where only one connectome is available. Therefore, we propose Structural-Functional Connectivity GAN (SFC-GAN), a novel framework for bidirectional translation between SC and FC. This approach leverages the CycleGAN architecture, incorporating convolutional layers to effectively capture the spatial structures of brain connectomes. To preserve the topological integrity of these connectomes, we employ a structure-preserving loss that guides the model in capturing both global and local connectome patterns while maintaining symmetry. Our framework demonstrates superior performance in translating between SC and FC, outperforming baseline models in similarity and graph property evaluations compared to ground truth data, each translated modality can be effectively utilized for downstream classification.
Classification of High-dimensional Time Series in Spectral Domain using Explainable Features
Aug 15, 2024Interpretable classification of time series presents significant challenges in high dimensions. Traditional feature selection methods in the frequency domain often assume sparsity in spectral density matrices (SDMs) or their inverses, which can be restrictive for real-world applications. In this article, we propose a model-based approach for classifying high-dimensional stationary time series by assuming sparsity in the difference between inverse SDMs. Our approach emphasizes the interpretability of model parameters, making it especially suitable for fields like neuroscience, where understanding differences in brain network connectivity across various states is crucial. The estimators for model parameters demonstrate consistency under appropriate conditions. We further propose using standard deep learning optimizers for parameter estimation, employing techniques such as mini-batching and learning rate scheduling. Additionally, we introduce a method to screen the most discriminatory frequencies for classification, which exhibits the sure screening property under general conditions. The flexibility of the proposed model allows the significance of covariates to vary across frequencies, enabling nuanced inferences and deeper insights into the underlying problem. The novelty of our method lies in the interpretability of the model parameters, addressing critical needs in neuroscience. The proposed approaches have been evaluated on simulated examples and the `Alert-vs-Drowsy' EEG dataset.
Predictive Performance Test based on the Exhaustive Nested Cross-Validation for High-dimensional data
Aug 06, 2024



It is crucial to assess the predictive performance of a model in order to establish its practicality and relevance in real-world scenarios, particularly for high-dimensional data analysis. Among data splitting or resampling methods, cross-validation (CV) is extensively used for several tasks such as estimating the prediction error, tuning the regularization parameter, and selecting the most suitable predictive model among competing alternatives. The K-fold cross-validation is a popular CV method but its limitation is that the risk estimates are highly dependent on the partitioning of the data (for training and testing). Here, the issues regarding the reproducibility of the K-fold CV estimator is demonstrated in hypothesis testing wherein different partitions lead to notably disparate conclusions. This study presents an alternative novel predictive performance test and valid confidence intervals based on exhaustive nested cross-validation for determining the difference in prediction error between two model-fitting algorithms. A naive implementation of the exhaustive nested cross-validation is computationally costly. Here, we address concerns regarding computational complexity by devising a computationally tractable closed-form expression for the proposed cross-validation estimator using ridge regularization. Our study also investigates strategies aimed at enhancing statistical power within high-dimensional scenarios while controlling the Type I error rate. To illustrate the practical utility of our method, we apply it to an RNA sequencing study and demonstrate its effectiveness in the context of biological data analysis.
Dynamic MRI reconstruction using low-rank plus sparse decomposition with smoothness regularization
Jan 30, 2024



The low-rank plus sparse (L+S) decomposition model has enabled better reconstruction of dynamic magnetic resonance imaging (dMRI) with separation into background (L) and dynamic (S) component. However, use of low-rank prior alone may not fully explain the slow variations or smoothness of the background part at the local scale. In this paper, we propose a smoothness-regularized L+S (SR-L+S) model for dMRI reconstruction from highly undersampled k-t-space data. We exploit joint low-rank and smooth priors on the background component of dMRI to better capture both its global and local temporal correlated structures. Extending the L+S formulation, the low-rank property is encoded by the nuclear norm, while the smoothness by a general \ell_{p}-norm penalty on the local differences of the columns of L. The additional smoothness regularizer can promote piecewise local consistency between neighboring frames. By smoothing out the noise and dynamic activities, it allows accurate recovery of the background part, and subsequently more robust dMRI reconstruction. Extensive experiments on multi-coil cardiac and synthetic data shows that the SR-L+S model outp
Stylized Projected GAN: A Novel Architecture for Fast and Realistic Image Generation
Jul 30, 2023Generative Adversarial Networks are used for generating the data using a generator and a discriminator, GANs usually produce high-quality images, but training GANs in an adversarial setting is a difficult task. GANs require high computation power and hyper-parameter regularization for converging. Projected GANs tackle the training difficulty of GANs by using transfer learning to project the generated and real samples into a pre-trained feature space. Projected GANs improve the training time and convergence but produce artifacts in the generated images which reduce the quality of the generated samples, we propose an optimized architecture called Stylized Projected GANs which integrates the mapping network of the Style GANs with Skip Layer Excitation of Fast GAN. The integrated modules are incorporated within the generator architecture of the Fast GAN to mitigate the problem of artifacts in the generated images.