 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust fuzzy clustering for high-dimensional multivariate time series with outlier detection
Oct 30, 2025

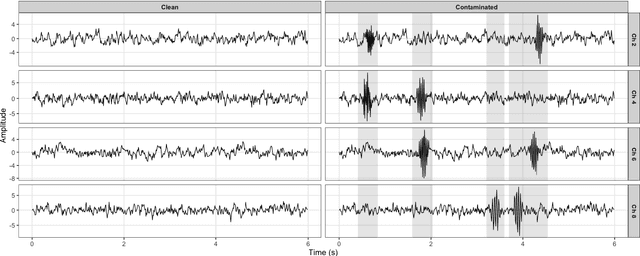

Fuzzy clustering provides a natural framework for modeling partial memberships, particularly important in multivariate time series (MTS) where state boundaries are often ambiguous. For example, in EEG monitoring of driver alertness, neural activity evolves along a continuum (from unconscious to fully alert, with many intermediate levels of drowsiness) so crisp labels are unrealistic and partial memberships are essential. However, most existing algorithms are developed for static, low-dimensional data and struggle with temporal dependence, unequal sequence lengths, high dimensionality, and contamination by noise or artifacts. To address these challenges, we introduce RFCPCA, a robust fuzzy subspace-clustering method explicitly tailored to MTS that, to the best of our knowledge, is the first of its kind to simultaneously: (i) learn membership-informed subspaces, (ii) accommodate unequal lengths and moderately high dimensions, (iii) achieve robustness through trimming, exponential reweighting, and a dedicated noise cluster, and (iv) automatically select all required hyperparameters. These components enable RFCPCA to capture latent temporal structure, provide calibrated membership uncertainty, and flag series-level outliers while remaining stable under contamination. On driver drowsiness EEG, RFCPCA improves clustering accuracy over related methods and yields a more reliable characterization of uncertainty and outlier structure in MTS.
FCPCA: Fuzzy clustering of high-dimensional time series based on common principal component analysis
May 12, 2025
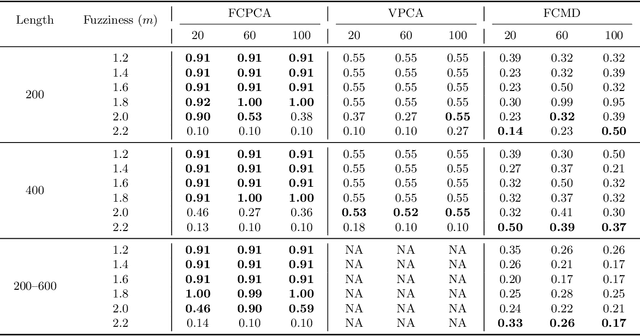


Clustering multivariate time series data is a crucial task in many domains, as it enables the identification of meaningful patterns and groups in time-evolving data. Traditional approaches, such as crisp clustering, rely on the assumption that clusters are sufficiently separated with little overlap. However, real-world data often defy this assumption, exhibiting overlapping distributions or overlapping clouds of points and blurred boundaries between clusters. Fuzzy clustering offers a compelling alternative by allowing partial membership in multiple clusters, making it well-suited for these ambiguous scenarios. Despite its advantages, current fuzzy clustering methods primarily focus on univariate time series, and for multivariate cases, even datasets of moderate dimensionality become computationally prohibitive. This challenge is further exacerbated when dealing with time series of varying lengths, leaving a clear gap in addressing the complexities of modern datasets. This work introduces a novel fuzzy clustering approach based on common principal component analysis to address the aforementioned shortcomings. Our method has the advantage of efficiently handling high-dimensional multivariate time series by reducing dimensionality while preserving critical temporal features. Extensive numerical results show that our proposed clustering method outperforms several existing approaches in the literature. An interesting application involving brain signals from different drivers recorded from a simulated driving experiment illustrates the potential of the approach.
New bootstrap tests for categorical time series. A comparative study
Apr 30, 2023The problem of testing the equality of the generating processes of two categorical time series is addressed in this work. To this aim, we propose three tests relying on a dissimilarity measure between categorical processes. Particular versions of these tests are constructed by considering three specific distances evaluating discrepancy between the marginal distributions and the serial dependence patterns of both processes. Proper estimates of these dissimilarities are an essential element of the constructed tests, which are based on the bootstrap. Specifically, a parametric bootstrap method assuming the true generating models and extensions of the moving blocks bootstrap and the stationary bootstrap are considered. The approaches are assessed in a broad simulation study including several types of categorical models with different degrees of complexity. Advantages and disadvantages of each one of the methods are properly discussed according to their behavior under the null and the alternative hypothesis. The impact that some important input parameters have on the results of the tests is also analyzed. An application involving biological sequences highlights the usefulness of the proposed techniques.
Quantile-based fuzzy C-means clustering of multivariate time series: Robust techniques
Sep 22, 2021

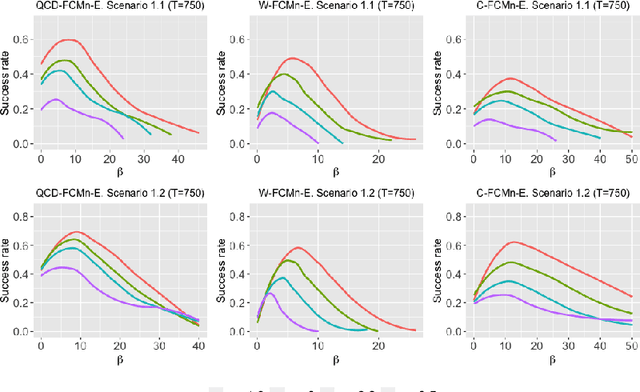

Three robust methods for clustering multivariate time series from the point of view of generating processes are proposed. The procedures are robust versions of a fuzzy C-means model based on: (i) estimates of the quantile cross-spectral density and (ii) the classical principal component analysis. Robustness to the presence of outliers is achieved by using the so-called metric, noise and trimmed approaches. The metric approach incorporates in the objective function a distance measure aimed at neutralizing the effect of the outliers, the noise approach builds an artificial cluster expected to contain the outlying series and the trimmed approach eliminates the most atypical series in the dataset. All the proposed techniques inherit the nice properties of the quantile cross-spectral density, as being able to uncover general types of dependence. Results from a broad simulation study including multivariate linear, nonlinear and GARCH processes indicate that the algorithms are substantially effective in coping with the presence of outlying series (i.e., series exhibiting a dependence structure different from that of the majority), clearly poutperforming alternative procedures. The usefulness of the suggested methods is highlighted by means of two specific applications regarding financial and environmental series.
Quantile-based fuzzy clustering of multivariate time series in the frequency domain
Sep 08, 2021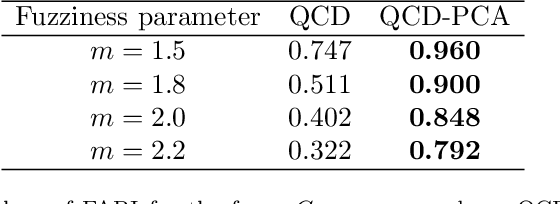
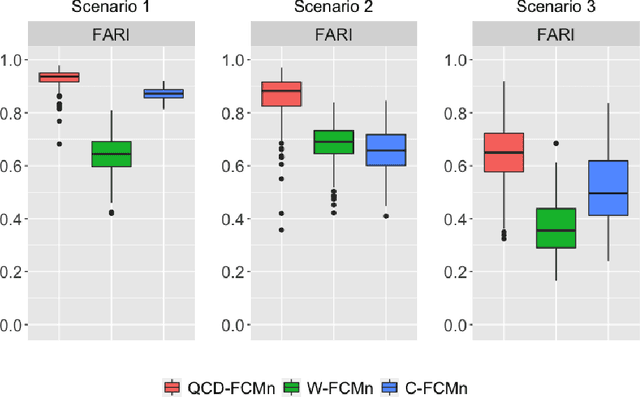


A novel procedure to perform fuzzy clustering of multivariate time series generated from different dependence models is proposed. Different amounts of dissimilarity between the generating models or changes on the dynamic behaviours over time are some arguments justifying a fuzzy approach, where each series is associated to all the clusters with specific membership levels. Our procedure considers quantile-based cross-spectral features and consists of three stages: (i) each element is characterized by a vector of proper estimates of the quantile cross-spectral densities, (ii) principal component analysis is carried out to capture the main differences reducing the effects of the noise, and (iii) the squared Euclidean distance between the first retained principal components is used to perform clustering through the standard fuzzy C-means and fuzzy C-medoids algorithms. The performance of the proposed approach is evaluated in a broad simulation study where several types of generating processes are considered, including linear, nonlinear and dynamic conditional correlation models. Assessment is done in two different ways: by directly measuring the quality of the resulting fuzzy partition and by taking into account the ability of the technique to determine the overlapping nature of series located equidistant from well-defined clusters. The procedure is compared with the few alternatives suggested in the literature, substantially outperforming all of them whatever the underlying process and the evaluation scheme. Two specific applications involving air quality and financial databases illustrate the usefulness of our approach.