 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuzzy clustering of ordinal time series based on two novel distances with economic applications
Apr 24, 2023Time series clustering is a central machine learning task with applications in many fields. While the majority of the methods focus on real-valued time series, very few works consider series with discrete response. In this paper, the problem of clustering ordinal time series is addressed. To this aim, two novel distances between ordinal time series are introduced and used to construct fuzzy clustering procedures. Both metrics are functions of the estimated cumulative probabilities, thus automatically taking advantage of the ordering inherent to the series' range. The resulting clustering algorithms are computationally efficient and able to group series generated from similar stochastic processes, reaching accurate results even though the series come from a wide variety of models. Since the dynamic of the series may vary over the time, we adopt a fuzzy approach, thus enabling the procedures to locate each series into several clusters with different membership degrees. An extensive simulation study shows that the proposed methods outperform several alternative procedures. Weighted versions of the clustering algorithms are also presented and their advantages with respect to the original methods are discussed. Two specific applications involving economic time series illustrate the usefulness of the proposed approaches.
Quantile-based fuzzy C-means clustering of multivariate time series: Robust techniques
Sep 22, 2021

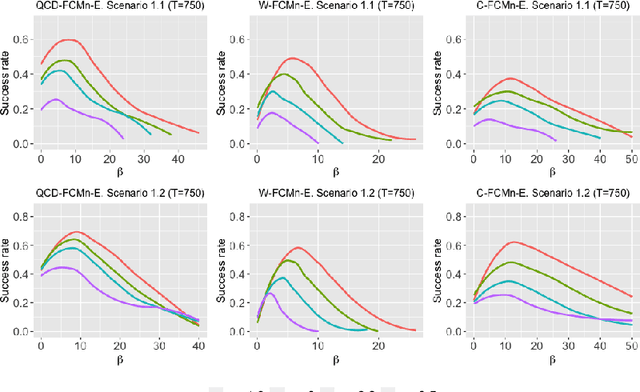

Three robust methods for clustering multivariate time series from the point of view of generating processes are proposed. The procedures are robust versions of a fuzzy C-means model based on: (i) estimates of the quantile cross-spectral density and (ii) the classical principal component analysis. Robustness to the presence of outliers is achieved by using the so-called metric, noise and trimmed approaches. The metric approach incorporates in the objective function a distance measure aimed at neutralizing the effect of the outliers, the noise approach builds an artificial cluster expected to contain the outlying series and the trimmed approach eliminates the most atypical series in the dataset. All the proposed techniques inherit the nice properties of the quantile cross-spectral density, as being able to uncover general types of dependence. Results from a broad simulation study including multivariate linear, nonlinear and GARCH processes indicate that the algorithms are substantially effective in coping with the presence of outlying series (i.e., series exhibiting a dependence structure different from that of the majority), clearly poutperforming alternative procedures. The usefulness of the suggested methods is highlighted by means of two specific applications regarding financial and environmental series.